 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing User Profiles via Contextual Bandits for Retrieval-Augmented LLM Personalization
Jan 17, 2026Large Language Models (LLMs) excel at general-purpose tasks, yet adapting their responses to individual users remains challenging. Retrieval augmentation provides a lightweight alternative to fine-tuning by conditioning LLMs on user history records, and existing approaches typically select these records based on semantic relevance. We argue that relevance serves as an unreliable proxy for utility: a record may be semantically similar to a query yet fail to improve generation quality or even degrade it due to redundancy or conflicting information. To bridge this gap, we propose PURPLE, a contextual bandit framework that oPtimizes UseR Profiles for Llm pErsonalization. In contrast to a greedy selection of the most relevant records, PURPLE treats profile construction as a set generation process and utilizes a Plackett-Luce ranking model to capture complex inter-record dependencies. By training with dense feedback provided by the likelihood of the reference response, our method aligns retrieval directly with generation quality. Extensive experiments on nine personalization tasks demonstrate that PURPLE consistently outperforms strong heuristic and retrieval-augmented baselines in both effectiveness and efficiency, establishing a principled and scalable solution for optimizing user profiles.
WebGames: Challenging General-Purpose Web-Browsing AI Agents
Feb 25, 2025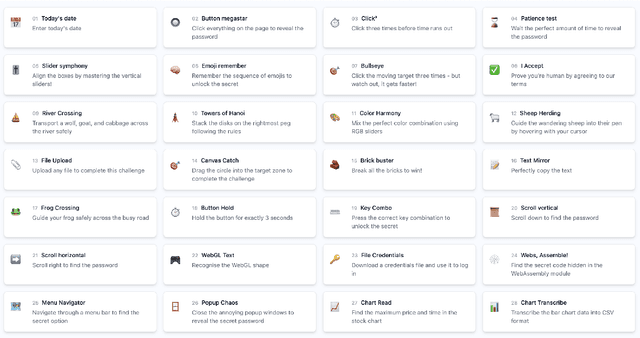


We introduce WebGames, a comprehensive benchmark suite designed to evaluate general-purpose web-browsing AI agents through a collection of 50+ interactive challenges. These challenges are specifically crafted to be straightforward for humans while systematically testing the limitations of current AI systems across fundamental browser interactions, advanced input processing, cognitive tasks, workflow automation, and interactive entertainment. Our framework eliminates external dependencies through a hermetic testing environment, ensuring reproducible evaluation with verifiable ground-truth solutions. We evaluate leading vision-language models including GPT-4o, Claude Computer-Use, Gemini-1.5-Pro, and Qwen2-VL against human performance. Results reveal a substantial capability gap, with the best AI system achieving only 43.1% success rate compared to human performance of 95.7%, highlighting fundamental limitations in current AI systems' ability to handle common web interaction patterns that humans find intuitive. The benchmark is publicly available at webgames.convergence.ai, offering a lightweight, client-side implementation that facilitates rapid evaluation cycles. Through its modular architecture and standardized challenge specifications, WebGames provides a robust foundation for measuring progress in development of more capable web-browsing agents.
LM2: Large Memory Models
Feb 09, 2025This paper introduces the Large Memory Model (LM2), a decoder-only Transformer architecture enhanced with an auxiliary memory module that aims to address the limitations of standard Transformers in multi-step reasoning, relational argumentation, and synthesizing information distributed over long contexts. The proposed LM2 incorporates a memory module that acts as a contextual representation repository, interacting with input tokens via cross attention and updating through gating mechanisms. To preserve the Transformers general-purpose capabilities, LM2 maintains the original information flow while integrating a complementary memory pathway. Experimental results on the BABILong benchmark demonstrate that the LM2model outperforms both the memory-augmented RMT model by 37.1% and the baseline Llama-3.2 model by 86.3% on average across tasks. LM2 exhibits exceptional capabilities in multi-hop inference, numerical reasoning, and large-context question-answering. On the MMLU dataset, it achieves a 5.0% improvement over a pre-trained vanilla model, demonstrating that its memory module does not degrade performance on general tasks. Further, in our analysis, we explore the memory interpretability, effectiveness of memory modules, and test-time behavior. Our findings emphasize the importance of explicit memory in enhancing Transformer architectures.
MindStar: Enhancing Math Reasoning in Pre-trained LLMs at Inference Time
May 25, 2024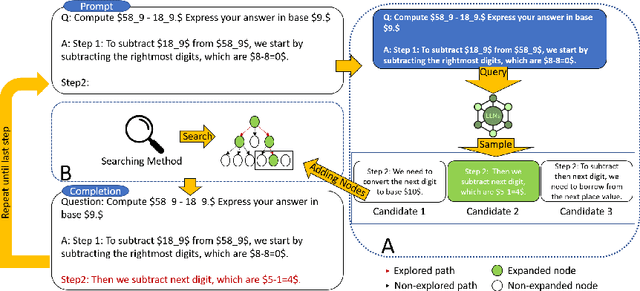
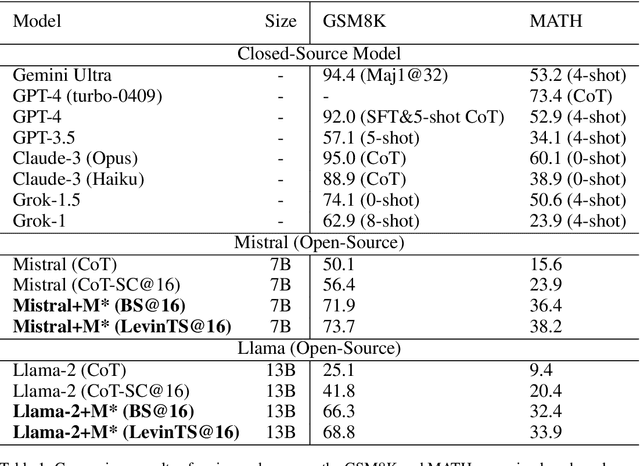
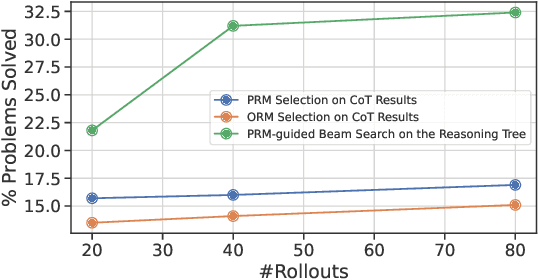
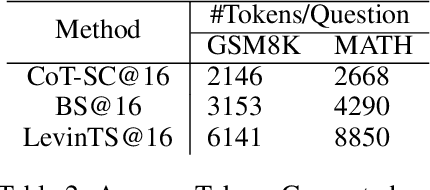
Although Large Language Models (LLMs) achieve remarkable performance across various tasks, they often struggle with complex reasoning tasks, such as answering mathematical questions. Recent efforts to address this issue have primarily focused on leveraging mathematical datasets through supervised fine-tuning or self-improvement techniques. However, these methods often depend on high-quality datasets that are difficult to prepare, or they require substantial computational resources for fine-tuning. Inspired by findings that LLMs know how to produce right answer but struggle to select the correct reasoning path, we propose a purely inference-based searching method called MindStar (M*), which treats reasoning tasks as search problems. This method utilizes a step-wise reasoning approach to navigate the tree space. To enhance search efficiency, we propose two tree-search ideas to identify the optimal reasoning paths. We evaluate the M* framework on both the GSM8K and MATH datasets, comparing its performance with existing open and closed-source LLMs. Our results demonstrate that M* significantly enhances the reasoning abilities of open-source models, such as Llama-2-13B and Mistral-7B, and achieves comparable performance to GPT-3.5 and Grok-1, but with substantially reduced model size and computational costs.
LaFFi: Leveraging Hybrid Natural Language Feedback for Fine-tuning Language Models
Dec 31, 2023Fine-tuning Large Language Models (LLMs) adapts a trained model to specific downstream tasks, significantly improving task-specific performance. Supervised Fine-Tuning (SFT) is a common approach, where an LLM is trained to produce desired answers. However, LLMs trained with SFT sometimes make simple mistakes and result in hallucinations on reasoning tasks such as question-answering. Without external feedback, it is difficult for SFT to learn a good mapping between the question and the desired answer, especially with a small dataset. This paper introduces an alternative to SFT called Natural Language Feedback for Finetuning LLMs (LaFFi). LaFFi has LLMs directly predict the feedback they will receive from an annotator. We find that requiring such reflection can significantly improve the accuracy in in-domain question-answering tasks, providing a promising direction for the application of natural language feedback in the realm of SFT LLMs. Additional ablation studies show that the portion of human-annotated data in the annotated datasets affects the fine-tuning performance.
Think Before You Act: Decision Transformers with Internal Working Memory
May 24, 2023Large language model (LLM)-based decision-making agents have shown the ability to generalize across multiple tasks. However, their performance relies on massive data and compute. We argue that this inefficiency stems from the forgetting phenomenon, in which a model memorizes its behaviors in parameters throughout training. As a result, training on a new task may deteriorate the model's performance on previous tasks. In contrast to LLMs' implicit memory mechanism, the human brain utilizes distributed memory storage, which helps manage and organize multiple skills efficiently, mitigating the forgetting phenomenon. Thus inspired, we propose an internal working memory module to store, blend, and retrieve information for different downstream tasks. Evaluation results show that the proposed method improves training efficiency and generalization in both Atari games and meta-world object manipulation tasks. Moreover, we demonstrate that memory fine-tuning further enhances the adaptability of the proposed architecture.
Multi-agent Attention Actor-Critic Algorithm for Load Balancing in Cellular Networks
Mar 14, 2023In cellular networks, User Equipment (UE) handoff from one Base Station (BS) to another, giving rise to the load balancing problem among the BSs. To address this problem, BSs can work collaboratively to deliver a smooth migration (or handoff) and satisfy the UEs' service requirements. This paper formulates the load balancing problem as a Markov game and proposes a Robust Multi-agent Attention Actor-Critic (Robust-MA3C) algorithm that can facilitate collaboration among the BSs (i.e., agents). In particular, to solve the Markov game and find a Nash equilibrium policy, we embrace the idea of adopting a nature agent to model the system uncertainty. Moreover, we utilize the self-attention mechanism, which encourages high-performance BSs to assist low-performance BSs. In addition, we consider two types of schemes, which can facilitate load balancing for both active UEs and idle UEs. We carry out extensive evaluations by simulations, and simulation results illustrate that, compared to the state-of-the-art MARL methods, Robust-\ours~scheme can improve the overall performance by up to 45%.
Learning Multi-Objective Curricula for Deep Reinforcement Learning
Oct 06, 2021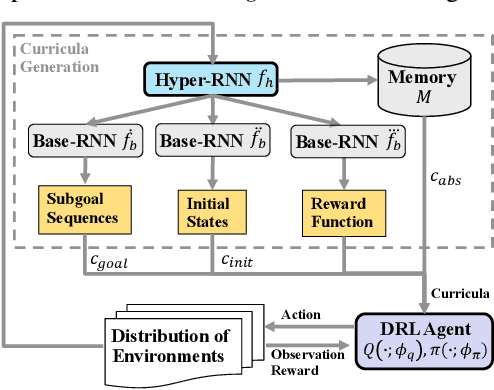

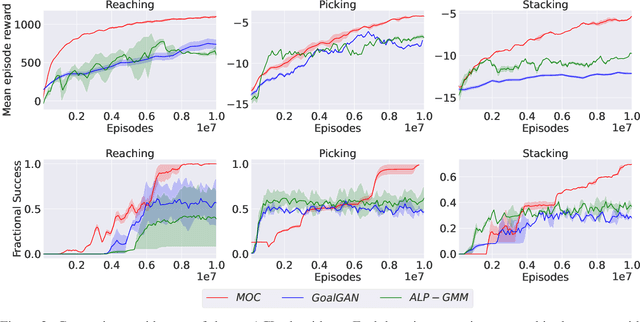
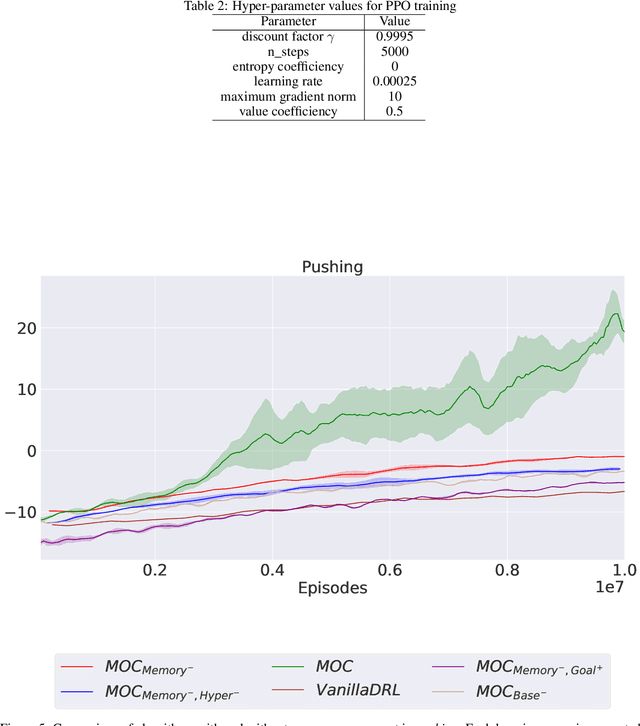
Various automatic curriculum learning (ACL) methods have been proposed to improve the sample efficiency and final performance of deep reinforcement learning (DRL). They are designed to control how a DRL agent collects data, which is inspired by how humans gradually adapt their learning processes to their capabilities. For example, ACL can be used for subgoal generation, reward shaping, environment generation, or initial state generation. However, prior work only considers curriculum learning following one of the aforementioned predefined paradigms. It is unclear which of these paradigms are complementary, and how the combination of them can be learned from interactions with the environment. Therefore, in this paper, we propose a unified automatic curriculum learning framework to create multi-objective but coherent curricula that are generated by a set of parametric curriculum modules. Each curriculum module is instantiated as a neural network and is responsible for generating a particular curriculum. In order to coordinate those potentially conflicting modules in unified parameter space, we propose a multi-task hyper-net learning framework that uses a single hyper-net to parameterize all those curriculum modules. In addition to existing hand-designed curricula paradigms, we further design a flexible memory mechanism to learn an abstract curriculum, which may otherwise be difficult to design manually. We evaluate our method on a series of robotic manipulation tasks and demonstrate its superiority over other state-of-the-art ACL methods in terms of sample efficiency and final performance.