 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaplacian Representations for Decision-Time Planning
Feb 04, 2026Planning with a learned model remains a key challenge in model-based reinforcement learning (RL). In decision-time planning, state representations are critical as they must support local cost computation while preserving long-horizon structure. In this paper, we show that the Laplacian representation provides an effective latent space for planning by capturing state-space distances at multiple time scales. This representation preserves meaningful distances and naturally decomposes long-horizon problems into subgoals, also mitigating the compounding errors that arise over long prediction horizons. Building on these properties, we introduce ALPS, a hierarchical planning algorithm, and demonstrate that it outperforms commonly used baselines on a selection of offline goal-conditioned RL tasks from OGBench, a benchmark previously dominated by model-free methods.
Reward Learning through Ranking Mean Squared Error
Jan 15, 2026Reward design remains a significant bottleneck in applying reinforcement learning (RL) to real-world problems. A popular alternative is reward learning, where reward functions are inferred from human feedback rather than manually specified. Recent work has proposed learning reward functions from human feedback in the form of ratings, rather than traditional binary preferences, enabling richer and potentially less cognitively demanding supervision. Building on this paradigm, we introduce a new rating-based RL method, Ranked Return Regression for RL (R4). At its core, R4 employs a novel ranking mean squared error (rMSE) loss, which treats teacher-provided ratings as ordinal targets. Our approach learns from a dataset of trajectory-rating pairs, where each trajectory is labeled with a discrete rating (e.g., "bad," "neutral," "good"). At each training step, we sample a set of trajectories, predict their returns, and rank them using a differentiable sorting operator (soft ranks). We then optimize a mean squared error loss between the resulting soft ranks and the teacher's ratings. Unlike prior rating-based approaches, R4 offers formal guarantees: its solution set is provably minimal and complete under mild assumptions. Empirically, using simulated human feedback, we demonstrate that R4 consistently matches or outperforms existing rating and preference-based RL methods on robotic locomotion benchmarks from OpenAI Gym and the DeepMind Control Suite, while requiring significantly less feedback.
Proceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
A Systematic Approach to Design Real-World Human-in-the-Loop Deep Reinforcement Learning: Salient Features, Challenges and Trade-offs
Apr 23, 2025

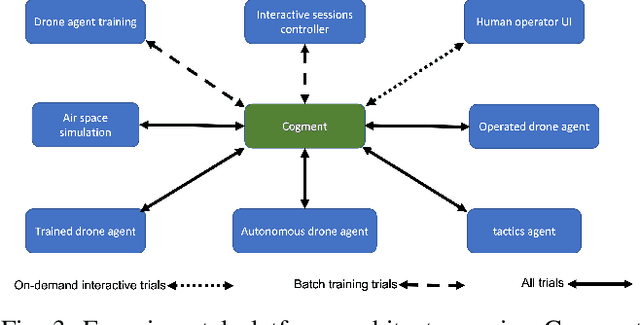
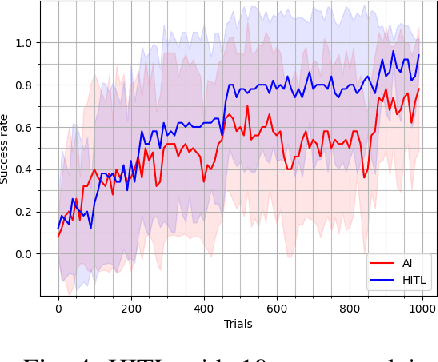
With the growing popularity of deep reinforcement learning (DRL), human-in-the-loop (HITL) approach has the potential to revolutionize the way we approach decision-making problems and create new opportunities for human-AI collaboration. In this article, we introduce a novel multi-layered hierarchical HITL DRL algorithm that comprises three types of learning: self learning, imitation learning and transfer learning. In addition, we consider three forms of human inputs: reward, action and demonstration. Furthermore, we discuss main challenges, trade-offs and advantages of HITL in solving complex problems and how human information can be integrated in the AI solution systematically. To verify our technical results, we present a real-world unmanned aerial vehicles (UAV) problem wherein a number of enemy drones attack a restricted area. The objective is to design a scalable HITL DRL algorithm for ally drones to neutralize the enemy drones before they reach the area. To this end, we first implement our solution using an award-winning open-source HITL software called Cogment. We then demonstrate several interesting results such as (a) HITL leads to faster training and higher performance, (b) advice acts as a guiding direction for gradient methods and lowers variance, and (c) the amount of advice should neither be too large nor too small to avoid over-training and under-training. Finally, we illustrate the role of human-AI cooperation in solving two real-world complex scenarios, i.e., overloaded and decoy attacks.
Towards Improving Reward Design in RL: A Reward Alignment Metric for RL Practitioners
Mar 08, 2025Reinforcement learning agents are fundamentally limited by the quality of the reward functions they learn from, yet reward design is often overlooked under the assumption that a well-defined reward is readily available. However, in practice, designing rewards is difficult, and even when specified, evaluating their correctness is equally problematic: how do we know if a reward function is correctly specified? In our work, we address these challenges by focusing on reward alignment -- assessing whether a reward function accurately encodes the preferences of a human stakeholder. As a concrete measure of reward alignment, we introduce the Trajectory Alignment Coefficient to quantify the similarity between a human stakeholder's ranking of trajectory distributions and those induced by a given reward function. We show that the Trajectory Alignment Coefficient exhibits desirable properties, such as not requiring access to a ground truth reward, invariance to potential-based reward shaping, and applicability to online RL. Additionally, in an 11 -- person user study of RL practitioners, we found that access to the Trajectory Alignment Coefficient during reward selection led to statistically significant improvements. Compared to relying only on reward functions, our metric reduced cognitive workload by 1.5x, was preferred by 82% of users and increased the success rate of selecting reward functions that produced performant policies by 41%.
Model-Based Exploration in Monitored Markov Decision Processes
Feb 24, 2025A tenet of reinforcement learning is that rewards are always observed by the agent. However, this is not true in many realistic settings, e.g., a human observer may not always be able to provide rewards, a sensor to observe rewards may be limited or broken, or rewards may be unavailable during deployment. Monitored Markov decision processes (Mon-MDPs) have recently been proposed as a model of such settings. Yet, Mon-MDP algorithms developed thus far do not fully exploit the problem structure, cannot take advantage of a known monitor, have no worst-case guarantees for ``unsolvable'' Mon-MDPs without specific initialization, and only have asymptotic proofs of convergence. This paper makes three contributions. First, we introduce a model-based algorithm for Mon-MDPs that addresses all of these shortcomings. The algorithm uses two instances of model-based interval estimation, one to guarantee that observable rewards are indeed observed, and another to learn the optimal policy. Second, empirical results demonstrate these advantages, showing faster convergence than prior algorithms in over two dozen benchmark settings, and even more dramatic improvements when the monitor process is known. Third, we present the first finite-sample bound on performance and show convergence to an optimal worst-case policy when some rewards are never observable.
The Evolving Landscape of LLM- and VLM-Integrated Reinforcement Learning
Feb 21, 2025



Reinforcement learning (RL) has shown impressive results in sequential decision-making tasks. Meanwhile, Large Language Models (LLMs) and Vision-Language Models (VLMs) have emerged, exhibiting impressive capabilities in multimodal understanding and reasoning. These advances have led to a surge of research integrating LLMs and VLMs into RL. In this survey, we review representative works in which LLMs and VLMs are used to overcome key challenges in RL, such as lack of prior knowledge, long-horizon planning, and reward design. We present a taxonomy that categorizes these LLM/VLM-assisted RL approaches into three roles: agent, planner, and reward. We conclude by exploring open problems, including grounding, bias mitigation, improved representations, and action advice. By consolidating existing research and identifying future directions, this survey establishes a framework for integrating LLMs and VLMs into RL, advancing approaches that unify natural language and visual understanding with sequential decision-making.
Investigating the Benefits of Nonlinear Action Maps in Data-Driven Teleoperation
Oct 28, 2024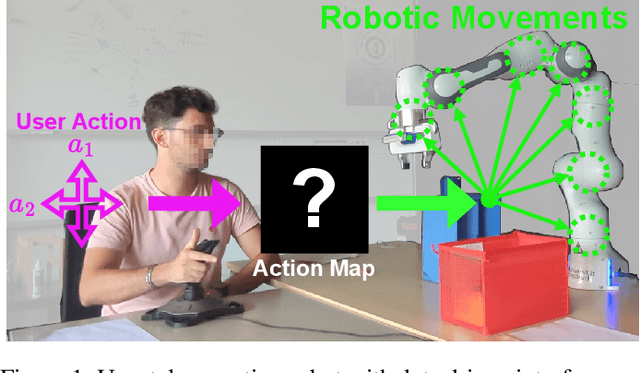

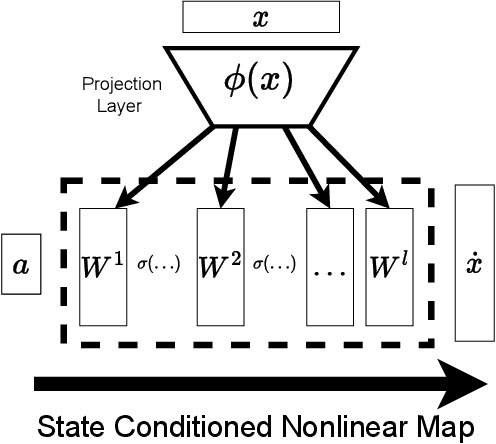

As robots become more common for both able-bodied individuals and those living with a disability, it is increasingly important that lay people be able to drive multi-degree-of-freedom platforms with low-dimensional controllers. One approach is to use state-conditioned action mapping methods to learn mappings between low-dimensional controllers and high DOF manipulators -- prior research suggests these mappings can simplify the teleoperation experience for users. Recent works suggest that neural networks predicting a local linear function are superior to the typical end-to-end multi-layer perceptrons because they allow users to more easily undo actions, providing more control over the system. However, local linear models assume actions exist on a linear subspace and may not capture nuanced actions in training data. We observe that the benefit of these mappings is being an odd function concerning user actions, and propose end-to-end nonlinear action maps which achieve this property. Unfortunately, our experiments show that such modifications offer minimal advantages over previous solutions. We find that nonlinear odd functions behave linearly for most of the control space, suggesting architecture structure improvements are not the primary factor in data-driven teleoperation. Our results suggest other avenues, such as data augmentation techniques and analysis of human behavior, are necessary for action maps to become practical in real-world applications, such as in assistive robotics to improve the quality of life of people living with w disability.
ODGR: Online Dynamic Goal Recognition
Jul 23, 2024
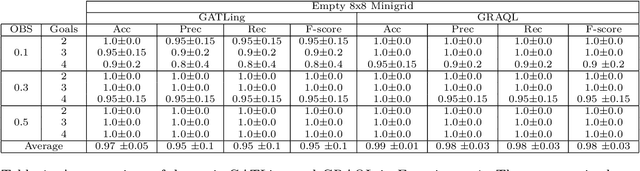

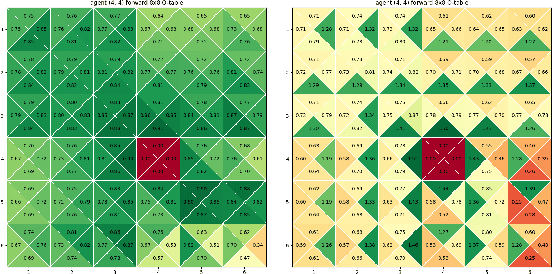
Traditionally, Reinforcement Learning (RL) problems are aimed at optimization of the behavior of an agent. This paper proposes a novel take on RL, which is used to learn the policy of another agent, to allow real-time recognition of that agent's goals. Goal Recognition (GR) has traditionally been framed as a planning problem where one must recognize an agent's objectives based on its observed actions. Recent approaches have shown how reinforcement learning can be used as part of the GR pipeline, but are limited to recognizing predefined goals and lack scalability in domains with a large goal space. This paper formulates a novel problem, "Online Dynamic Goal Recognition" (ODGR), as a first step to address these limitations. Contributions include introducing the concept of dynamic goals into the standard GR problem definition, revisiting common approaches by reformulating them using ODGR, and demonstrating the feasibility of solving ODGR in a navigation domain using transfer learning. These novel formulations open the door for future extensions of existing transfer learning-based GR methods, which will be robust to changing and expansive real-time environments.
A Novel Framework for Automated Warehouse Layout Generation
Jul 11, 2024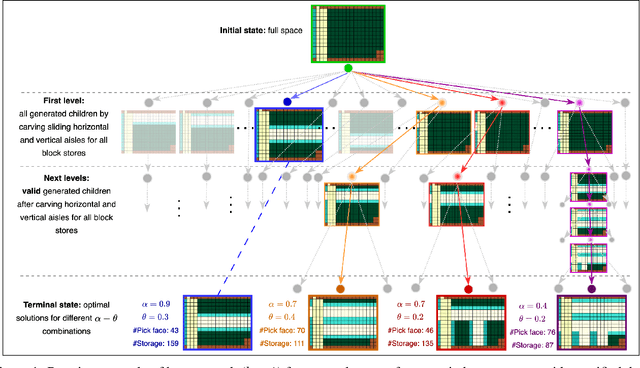
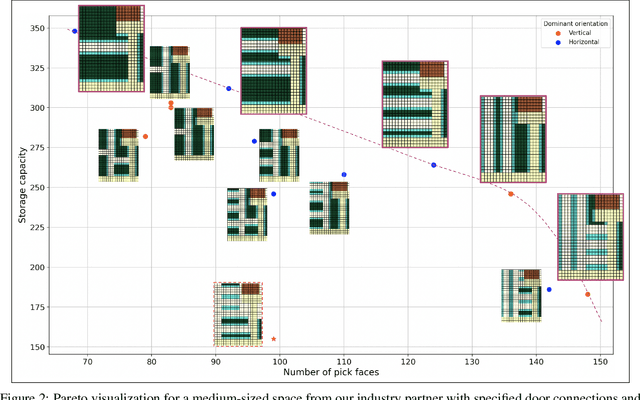
Optimizing warehouse layouts is crucial due to its significant impact on efficiency and productivity. We present an AI-driven framework for automated warehouse layout generation. This framework employs constrained beam search to derive optimal layouts within given spatial parameters, adhering to all functional requirements. The feasibility of the generated layouts is verified based on criteria such as item accessibility, required minimum clearances, and aisle connectivity. A scoring function is then used to evaluate the feasible layouts considering the number of storage locations, access points, and accessibility costs. We demonstrate our method's ability to produce feasible, optimal layouts for a variety of warehouse dimensions and shapes, diverse door placements, and interconnections. This approach, currently being prepared for deployment, will enable human designers to rapidly explore and confirm options, facilitating the selection of the most appropriate layout for their use-case.