 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Feature Dependent Noise in Preference-based Reinforcement Learning
Jan 05, 2026Learning from Preferences in Reinforcement Learning (PbRL) has gained attention recently, as it serves as a natural fit for complicated tasks where the reward function is not easily available. However, preferences often come with uncertainty and noise if they are not from perfect teachers. Much prior literature aimed to detect noise, but with limited types of noise and most being uniformly distributed with no connection to observations. In this work, we formalize the notion of targeted feature-dependent noise and propose several variants like trajectory feature noise, trajectory similarity noise, uncertainty-aware noise, and Language Model noise. We evaluate feature-dependent noise, where noise is correlated with certain features in complex continuous control tasks from DMControl and Meta-world. Our experiments show that in some feature-dependent noise settings, the state-of-the-art noise-robust PbRL method's learning performance is significantly deteriorated, while PbRL method with no explicit denoising can surprisingly outperform noise-robust PbRL in majority settings. We also find language model's noise exhibits similar characteristics to feature-dependent noise, thereby simulating realistic humans and call for further study in learning with feature-dependent noise robustly.
A Systematic Approach to Design Real-World Human-in-the-Loop Deep Reinforcement Learning: Salient Features, Challenges and Trade-offs
Apr 23, 2025

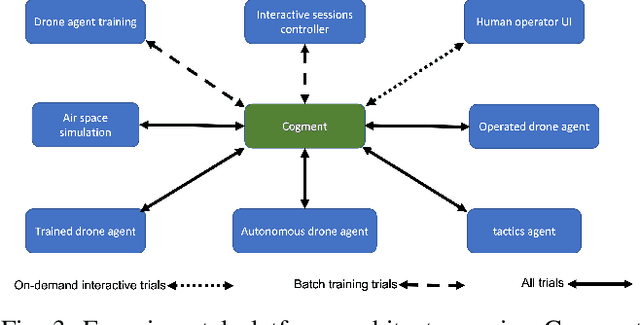
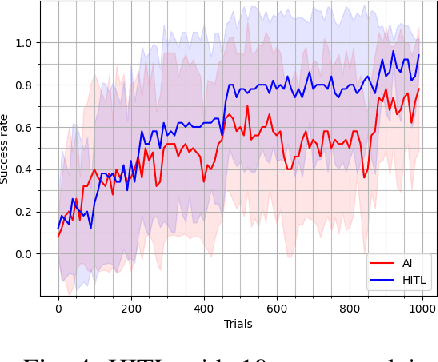
With the growing popularity of deep reinforcement learning (DRL), human-in-the-loop (HITL) approach has the potential to revolutionize the way we approach decision-making problems and create new opportunities for human-AI collaboration. In this article, we introduce a novel multi-layered hierarchical HITL DRL algorithm that comprises three types of learning: self learning, imitation learning and transfer learning. In addition, we consider three forms of human inputs: reward, action and demonstration. Furthermore, we discuss main challenges, trade-offs and advantages of HITL in solving complex problems and how human information can be integrated in the AI solution systematically. To verify our technical results, we present a real-world unmanned aerial vehicles (UAV) problem wherein a number of enemy drones attack a restricted area. The objective is to design a scalable HITL DRL algorithm for ally drones to neutralize the enemy drones before they reach the area. To this end, we first implement our solution using an award-winning open-source HITL software called Cogment. We then demonstrate several interesting results such as (a) HITL leads to faster training and higher performance, (b) advice acts as a guiding direction for gradient methods and lowers variance, and (c) the amount of advice should neither be too large nor too small to avoid over-training and under-training. Finally, we illustrate the role of human-AI cooperation in solving two real-world complex scenarios, i.e., overloaded and decoy attacks.
GLIDE-RL: Grounded Language Instruction through DEmonstration in RL
Jan 03, 2024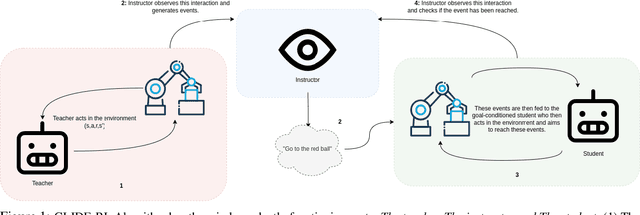

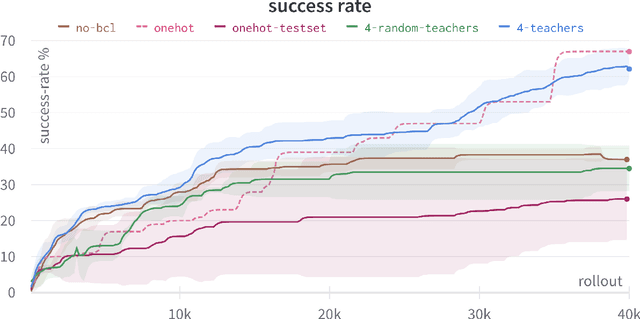
One of the final frontiers in the development of complex human - AI collaborative systems is the ability of AI agents to comprehend the natural language and perform tasks accordingly. However, training efficient Reinforcement Learning (RL) agents grounded in natural language has been a long-standing challenge due to the complexity and ambiguity of the language and sparsity of the rewards, among other factors. Several advances in reinforcement learning, curriculum learning, continual learning, language models have independently contributed to effective training of grounded agents in various environments. Leveraging these developments, we present a novel algorithm, Grounded Language Instruction through DEmonstration in RL (GLIDE-RL) that introduces a teacher-instructor-student curriculum learning framework for training an RL agent capable of following natural language instructions that can generalize to previously unseen language instructions. In this multi-agent framework, the teacher and the student agents learn simultaneously based on the student's current skill level. We further demonstrate the necessity for training the student agent with not just one, but multiple teacher agents. Experiments on a complex sparse reward environment validates the effectiveness of our proposed approach.
Human-AI Collaboration in Real-World Complex Environment with Reinforcement Learning
Dec 23, 2023Recent advances in reinforcement learning (RL) and Human-in-the-Loop (HitL) learning have made human-AI collaboration easier for humans to team with AI agents. Leveraging human expertise and experience with AI in intelligent systems can be efficient and beneficial. Still, it is unclear to what extent human-AI collaboration will be successful, and how such teaming performs compared to humans or AI agents only. In this work, we show that learning from humans is effective and that human-AI collaboration outperforms human-controlled and fully autonomous AI agents in a complex simulation environment. In addition, we have developed a new simulator for critical infrastructure protection, focusing on a scenario where AI-powered drones and human teams collaborate to defend an airport against enemy drone attacks. We develop a user interface to allow humans to assist AI agents effectively. We demonstrated that agents learn faster while learning from policy correction compared to learning from humans or agents. Furthermore, human-AI collaboration requires lower mental and temporal demands, reduces human effort, and yields higher performance than if humans directly controlled all agents. In conclusion, we show that humans can provide helpful advice to the RL agents, allowing them to improve learning in a multi-agent setting.
Augmenting Flight Training with AI to Efficiently Train Pilots
Oct 13, 2022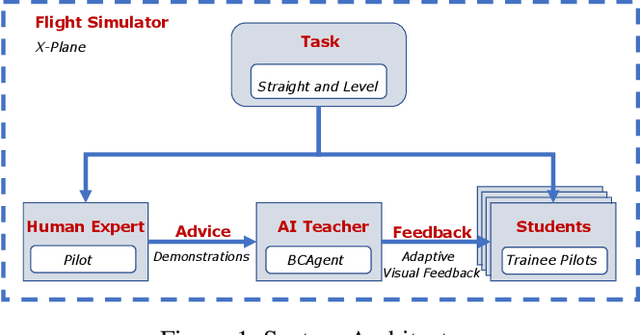
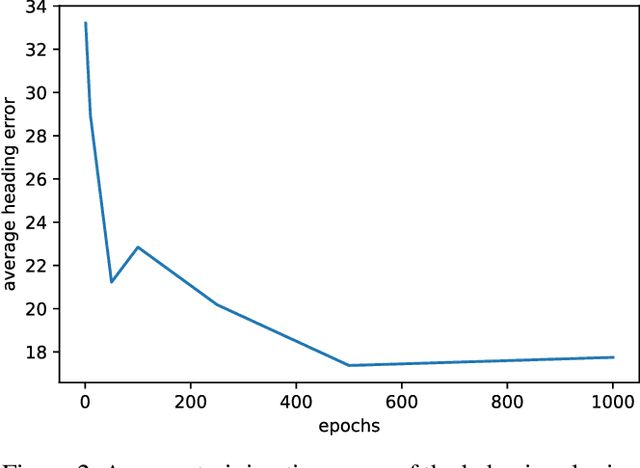

We propose an AI-based pilot trainer to help students learn how to fly aircraft. First, an AI agent uses behavioral cloning to learn flying maneuvers from qualified flight instructors. Later, the system uses the agent's decisions to detect errors made by students and provide feedback to help students correct their errors. This paper presents an instantiation of the pilot trainer. We focus on teaching straight and level flying maneuvers by automatically providing formative feedback to the human student.
Methodical Advice Collection and Reuse in Deep Reinforcement Learning
Apr 14, 2022
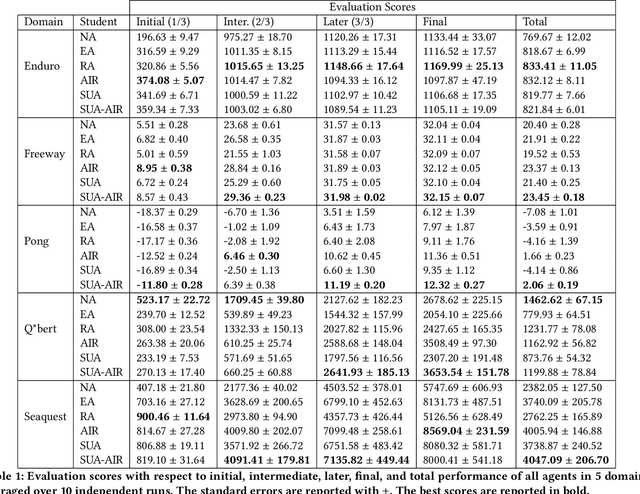
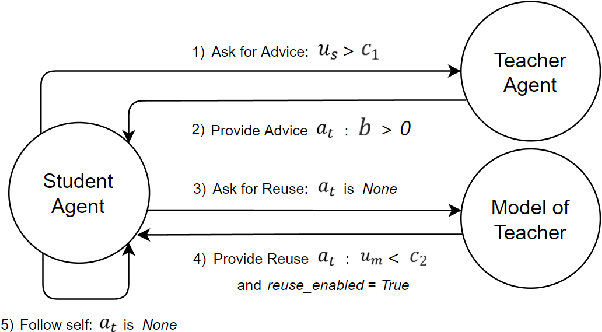
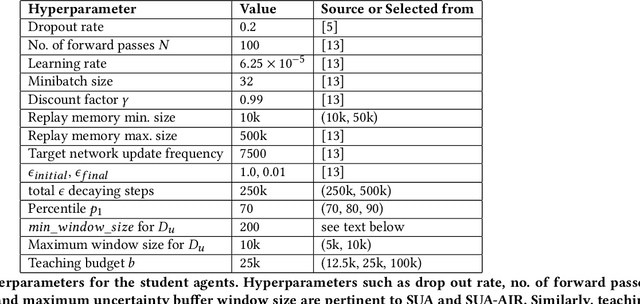
Reinforcement learning (RL) has shown great success in solving many challenging tasks via use of deep neural networks. Although using deep learning for RL brings immense representational power, it also causes a well-known sample-inefficiency problem. This means that the algorithms are data-hungry and require millions of training samples to converge to an adequate policy. One way to combat this issue is to use action advising in a teacher-student framework, where a knowledgeable teacher provides action advice to help the student. This work considers how to better leverage uncertainties about when a student should ask for advice and if the student can model the teacher to ask for less advice. The student could decide to ask for advice when it is uncertain or when both it and its model of the teacher are uncertain. In addition to this investigation, this paper introduces a new method to compute uncertainty for a deep RL agent using a secondary neural network. Our empirical results show that using dual uncertainties to drive advice collection and reuse may improve learning performance across several Atari games.
Fitted Q-Learning for Relational Domains
Jun 10, 2020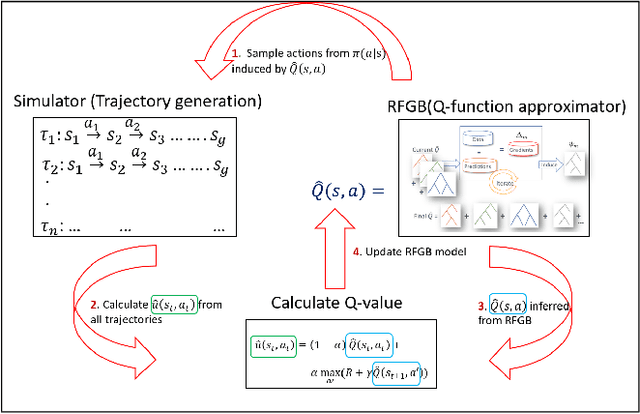
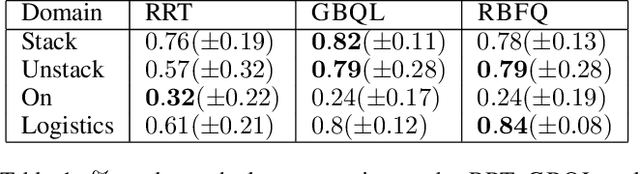
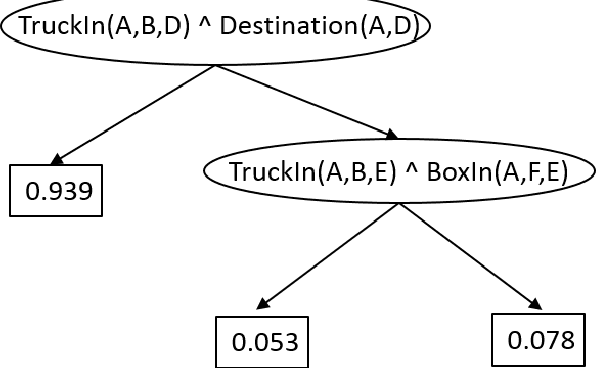
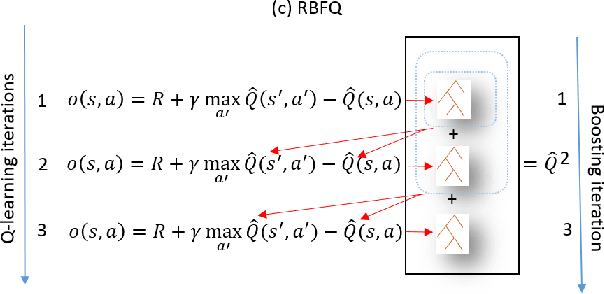
We consider the problem of Approximate Dynamic Programming in relational domains. Inspired by the success of fitted Q-learning methods in propositional settings, we develop the first relational fitted Q-learning algorithms by representing the value function and Bellman residuals. When we fit the Q-functions, we show how the two steps of Bellman operator; application and projection steps can be performed using a gradient-boosting technique. Our proposed framework performs reasonably well on standard domains without using domain models and using fewer training trajectories.