 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Learning through Ranking Mean Squared Error
Jan 15, 2026Reward design remains a significant bottleneck in applying reinforcement learning (RL) to real-world problems. A popular alternative is reward learning, where reward functions are inferred from human feedback rather than manually specified. Recent work has proposed learning reward functions from human feedback in the form of ratings, rather than traditional binary preferences, enabling richer and potentially less cognitively demanding supervision. Building on this paradigm, we introduce a new rating-based RL method, Ranked Return Regression for RL (R4). At its core, R4 employs a novel ranking mean squared error (rMSE) loss, which treats teacher-provided ratings as ordinal targets. Our approach learns from a dataset of trajectory-rating pairs, where each trajectory is labeled with a discrete rating (e.g., "bad," "neutral," "good"). At each training step, we sample a set of trajectories, predict their returns, and rank them using a differentiable sorting operator (soft ranks). We then optimize a mean squared error loss between the resulting soft ranks and the teacher's ratings. Unlike prior rating-based approaches, R4 offers formal guarantees: its solution set is provably minimal and complete under mild assumptions. Empirically, using simulated human feedback, we demonstrate that R4 consistently matches or outperforms existing rating and preference-based RL methods on robotic locomotion benchmarks from OpenAI Gym and the DeepMind Control Suite, while requiring significantly less feedback.
GLIDE-RL: Grounded Language Instruction through DEmonstration in RL
Jan 03, 2024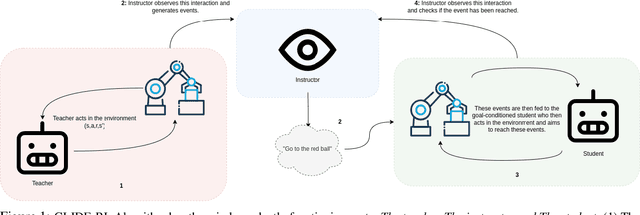

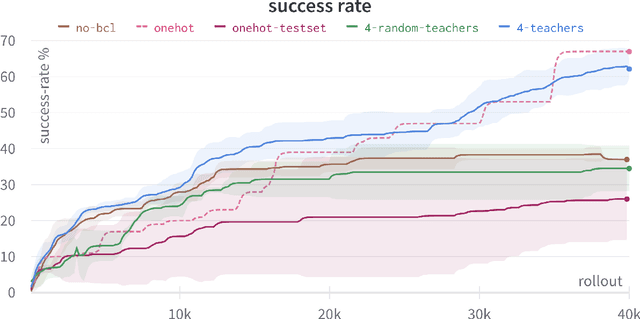
One of the final frontiers in the development of complex human - AI collaborative systems is the ability of AI agents to comprehend the natural language and perform tasks accordingly. However, training efficient Reinforcement Learning (RL) agents grounded in natural language has been a long-standing challenge due to the complexity and ambiguity of the language and sparsity of the rewards, among other factors. Several advances in reinforcement learning, curriculum learning, continual learning, language models have independently contributed to effective training of grounded agents in various environments. Leveraging these developments, we present a novel algorithm, Grounded Language Instruction through DEmonstration in RL (GLIDE-RL) that introduces a teacher-instructor-student curriculum learning framework for training an RL agent capable of following natural language instructions that can generalize to previously unseen language instructions. In this multi-agent framework, the teacher and the student agents learn simultaneously based on the student's current skill level. We further demonstrate the necessity for training the student agent with not just one, but multiple teacher agents. Experiments on a complex sparse reward environment validates the effectiveness of our proposed approach.
Spatial Relation Graph and Graph Convolutional Network for Object Goal Navigation
Aug 27, 2022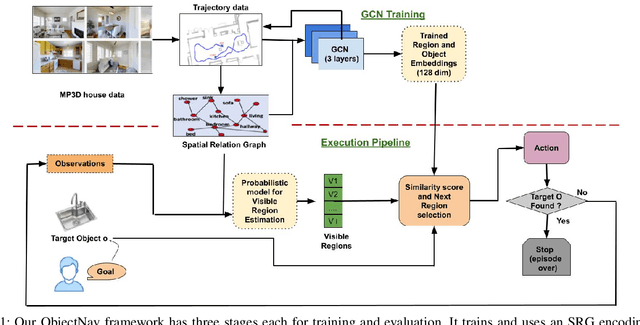
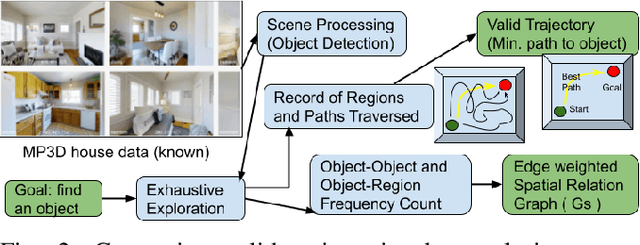
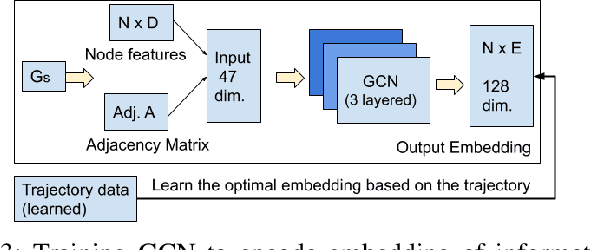
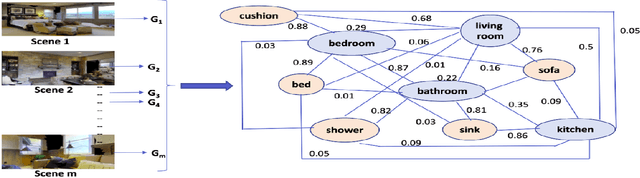
This paper describes a framework for the object-goal navigation task, which requires a robot to find and move to the closest instance of a target object class from a random starting position. The framework uses a history of robot trajectories to learn a Spatial Relational Graph (SRG) and Graph Convolutional Network (GCN)-based embeddings for the likelihood of proximity of different semantically-labeled regions and the occurrence of different object classes in these regions. To locate a target object instance during evaluation, the robot uses Bayesian inference and the SRG to estimate the visible regions, and uses the learned GCN embeddings to rank visible regions and select the region to explore next.
RP-VIO: Robust Plane-based Visual-Inertial Odometry for Dynamic Environments
Mar 18, 2021



Modern visual-inertial navigation systems (VINS) are faced with a critical challenge in real-world deployment: they need to operate reliably and robustly in highly dynamic environments. Current best solutions merely filter dynamic objects as outliers based on the semantics of the object category. Such an approach does not scale as it requires semantic classifiers to encompass all possibly-moving object classes; this is hard to define, let alone deploy. On the other hand, many real-world environments exhibit strong structural regularities in the form of planes such as walls and ground surfaces, which are also crucially static. We present RP-VIO, a monocular visual-inertial odometry system that leverages the simple geometry of these planes for improved robustness and accuracy in challenging dynamic environments. Since existing datasets have a limited number of dynamic elements, we also present a highly-dynamic, photorealistic synthetic dataset for a more effective evaluation of the capabilities of modern VINS systems. We evaluate our approach on this dataset, and three diverse sequences from standard datasets including two real-world dynamic sequences and show a significant improvement in robustness and accuracy over a state-of-the-art monocular visual-inertial odometry system. We also show in simulation an improvement over a simple dynamic-features masking approach. Our code and dataset are publicly available.