 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMomaGraph: State-Aware Unified Scene Graphs with Vision-Language Model for Embodied Task Planning
Dec 18, 2025Mobile manipulators in households must both navigate and manipulate. This requires a compact, semantically rich scene representation that captures where objects are, how they function, and which parts are actionable. Scene graphs are a natural choice, yet prior work often separates spatial and functional relations, treats scenes as static snapshots without object states or temporal updates, and overlooks information most relevant for accomplishing the current task. To address these limitations, we introduce MomaGraph, a unified scene representation for embodied agents that integrates spatial-functional relationships and part-level interactive elements. However, advancing such a representation requires both suitable data and rigorous evaluation, which have been largely missing. We thus contribute MomaGraph-Scenes, the first large-scale dataset of richly annotated, task-driven scene graphs in household environments, along with MomaGraph-Bench, a systematic evaluation suite spanning six reasoning capabilities from high-level planning to fine-grained scene understanding. Built upon this foundation, we further develop MomaGraph-R1, a 7B vision-language model trained with reinforcement learning on MomaGraph-Scenes. MomaGraph-R1 predicts task-oriented scene graphs and serves as a zero-shot task planner under a Graph-then-Plan framework. Extensive experiments demonstrate that our model achieves state-of-the-art results among open-source models, reaching 71.6% accuracy on the benchmark (+11.4% over the best baseline), while generalizing across public benchmarks and transferring effectively to real-robot experiments.
Watch Less, Feel More: Sim-to-Real RL for Generalizable Articulated Object Manipulation via Motion Adaptation and Impedance Control
Feb 20, 2025Articulated object manipulation poses a unique challenge compared to rigid object manipulation as the object itself represents a dynamic environment. In this work, we present a novel RL-based pipeline equipped with variable impedance control and motion adaptation leveraging observation history for generalizable articulated object manipulation, focusing on smooth and dexterous motion during zero-shot sim-to-real transfer. To mitigate the sim-to-real gap, our pipeline diminishes reliance on vision by not leveraging the vision data feature (RGBD/pointcloud) directly as policy input but rather extracting useful low-dimensional data first via off-the-shelf modules. Additionally, we experience less sim-to-real gap by inferring object motion and its intrinsic properties via observation history as well as utilizing impedance control both in the simulation and in the real world. Furthermore, we develop a well-designed training setting with great randomization and a specialized reward system (task-aware and motion-aware) that enables multi-staged, end-to-end manipulation without heuristic motion planning. To the best of our knowledge, our policy is the first to report 84\% success rate in the real world via extensive experiments with various unseen objects.
GAMMA: Graspability-Aware Mobile MAnipulation Policy Learning based on Online Grasping Pose Fusion
Sep 27, 2023



Mobile manipulation constitutes a fundamental task for robotic assistants and garners significant attention within the robotics community. A critical challenge inherent in mobile manipulation is the effective observation of the target while approaching it for grasping. In this work, we propose a graspability-aware mobile manipulation approach powered by an online grasping pose fusion framework that enables a temporally consistent grasping observation. Specifically, the predicted grasping poses are online organized to eliminate the redundant, outlier grasping poses, which can be encoded as a grasping pose observation state for reinforcement learning. Moreover, on-the-fly fusing the grasping poses enables a direct assessment of graspability, encompassing both the quantity and quality of grasping poses.
Sequence-Agnostic Multi-Object Navigation
May 10, 2023The Multi-Object Navigation (MultiON) task requires a robot to localize an instance (each) of multiple object classes. It is a fundamental task for an assistive robot in a home or a factory. Existing methods for MultiON have viewed this as a direct extension of Object Navigation (ON), the task of localising an instance of one object class, and are pre-sequenced, i.e., the sequence in which the object classes are to be explored is provided in advance. This is a strong limitation in practical applications characterized by dynamic changes. This paper describes a deep reinforcement learning framework for sequence-agnostic MultiON based on an actor-critic architecture and a suitable reward specification. Our framework leverages past experiences and seeks to reward progress toward individual as well as multiple target object classes. We use photo-realistic scenes from the Gibson benchmark dataset in the AI Habitat 3D simulation environment to experimentally show that our method performs better than a pre-sequenced approach and a state of the art ON method extended to MultiON.
Spatial Relation Graph and Graph Convolutional Network for Object Goal Navigation
Aug 27, 2022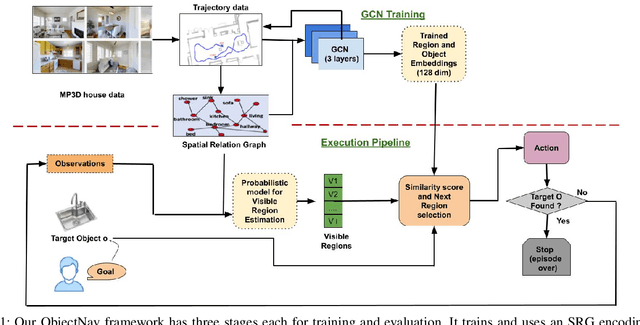
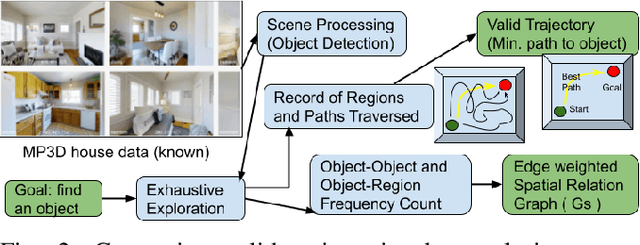
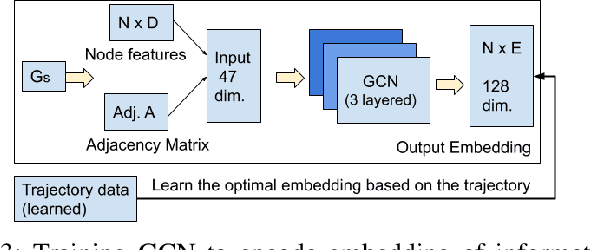
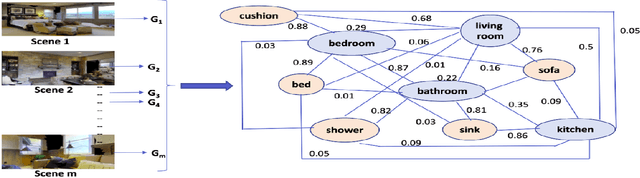
This paper describes a framework for the object-goal navigation task, which requires a robot to find and move to the closest instance of a target object class from a random starting position. The framework uses a history of robot trajectories to learn a Spatial Relational Graph (SRG) and Graph Convolutional Network (GCN)-based embeddings for the likelihood of proximity of different semantically-labeled regions and the occurrence of different object classes in these regions. To locate a target object instance during evaluation, the robot uses Bayesian inference and the SRG to estimate the visible regions, and uses the learned GCN embeddings to rank visible regions and select the region to explore next.
Object Goal Navigation using Data Regularized Q-Learning
Aug 27, 2022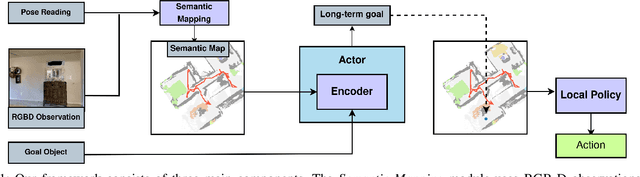
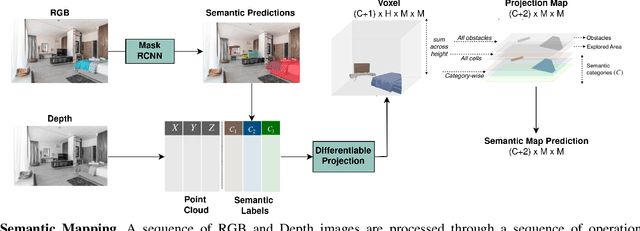
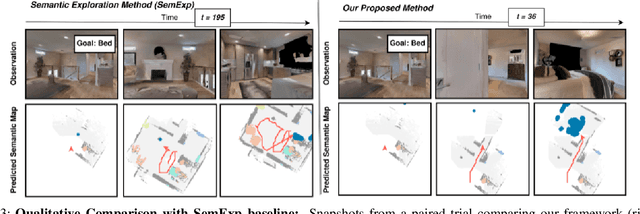

Object Goal Navigation requires a robot to find and navigate to an instance of a target object class in a previously unseen environment. Our framework incrementally builds a semantic map of the environment over time, and then repeatedly selects a long-term goal ('where to go') based on the semantic map to locate the target object instance. Long-term goal selection is formulated as a vision-based deep reinforcement learning problem. Specifically, an Encoder Network is trained to extract high-level features from a semantic map and select a long-term goal. In addition, we incorporate data augmentation and Q-function regularization to make the long-term goal selection more effective. We report experimental results using the photo-realistic Gibson benchmark dataset in the AI Habitat 3D simulation environment to demonstrate substantial performance improvement on standard measures in comparison with a state of the art data-driven baseline.
XRayGAN: Consistency-preserving Generation of X-ray Images from Radiology Reports
Jun 17, 2020



To effectively train medical students to become qualified radiologists, a large number of X-ray images collected from patients with diverse medical conditions are needed. However, due to data privacy concerns, such images are typically difficult to obtain. To address this problem, we develop methods to generate view-consistent, high-fidelity, and high-resolution X-ray images from radiology reports to facilitate radiology training of medical students. This task is presented with several challenges. First, from a single report, images with different views (e.g., frontal, lateral) need to be generated. How to ensure consistency of these images (i.e., make sure they are about the same patient)? Second, X-ray images are required to have high resolution. Otherwise, many details of diseases would be lost. How to generate high-resolutions images? Third, radiology reports are long and have complicated structure. How to effectively understand their semantics to generate high-fidelity images that accurately reflect the contents of the reports? To address these three challenges, we propose an XRayGAN composed of three modules: (1) a view consistency network that maximizes the consistency between generated frontal-view and lateral-view images; (2) a multi-scale conditional GAN that progressively generates a cascade of images with increasing resolution; (3) a hierarchical attentional encoder that learns the latent semantics of a radiology report by capturing its hierarchical linguistic structure and various levels of clinical importance of words and sentences. Experiments on two radiology datasets demonstrate the effectiveness of our methods. To our best knowledge, this work represents the first one generating consistent and high-resolution X-ray images from radiology reports. The code is available at https://github.com/UCSD-AI4H/XRayGAN.