 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPVO: Motion-Prior based Visual Odometry for PointGoal Navigation
Nov 07, 2024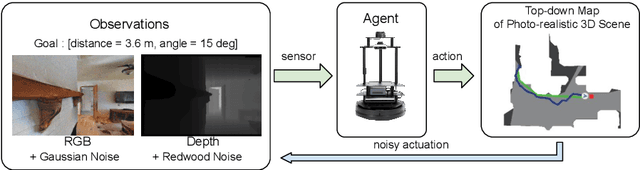
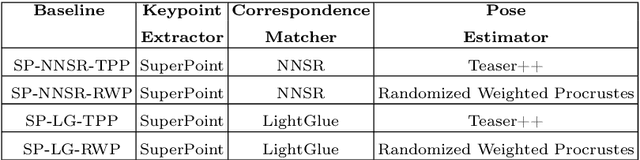
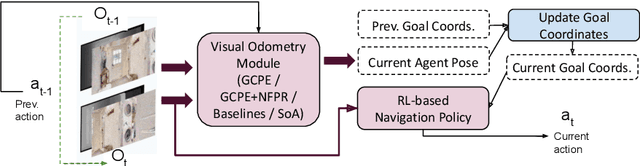
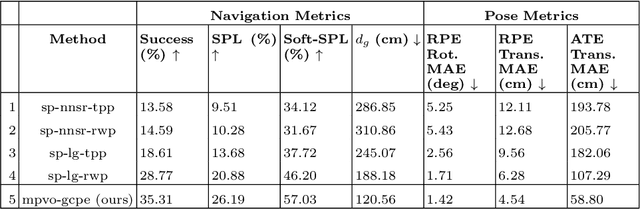
Visual odometry (VO) is essential for enabling accurate point-goal navigation of embodied agents in indoor environments where GPS and compass sensors are unreliable and inaccurate. However, traditional VO methods face challenges in wide-baseline scenarios, where fast robot motions and low frames per second (FPS) during inference hinder their performance, leading to drift and catastrophic failures in point-goal navigation. Recent deep-learned VO methods show robust performance but suffer from sample inefficiency during training; hence, they require huge datasets and compute resources. So, we propose a robust and sample-efficient VO pipeline based on motion priors available while an agent is navigating an environment. It consists of a training-free action-prior based geometric VO module that estimates a coarse relative pose which is further consumed as a motion prior by a deep-learned VO model, which finally produces a fine relative pose to be used by the navigation policy. This strategy helps our pipeline achieve up to 2x sample efficiency during training and demonstrates superior accuracy and robustness in point-goal navigation tasks compared to state-of-the-art VO method(s). Realistic indoor environments of the Gibson dataset is used in the AI-Habitat simulator to evaluate the proposed approach using navigation metrics (like success/SPL) and pose metrics (like RPE/ATE). We hope this method further opens a direction of work where motion priors from various sources can be utilized to improve VO estimates and achieve better results in embodied navigation tasks.
Spatial Relation Graph and Graph Convolutional Network for Object Goal Navigation
Aug 27, 2022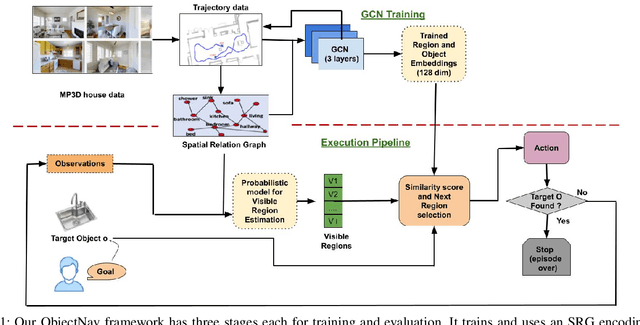
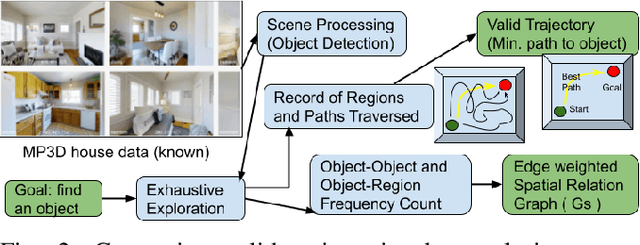
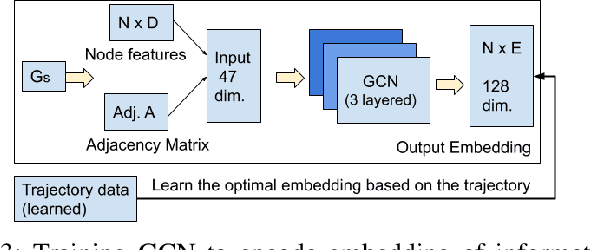
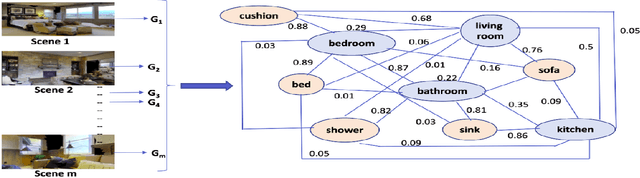
This paper describes a framework for the object-goal navigation task, which requires a robot to find and move to the closest instance of a target object class from a random starting position. The framework uses a history of robot trajectories to learn a Spatial Relational Graph (SRG) and Graph Convolutional Network (GCN)-based embeddings for the likelihood of proximity of different semantically-labeled regions and the occurrence of different object classes in these regions. To locate a target object instance during evaluation, the robot uses Bayesian inference and the SRG to estimate the visible regions, and uses the learned GCN embeddings to rank visible regions and select the region to explore next.
DoRO: Disambiguation of referred object for embodied agents
Jul 28, 2022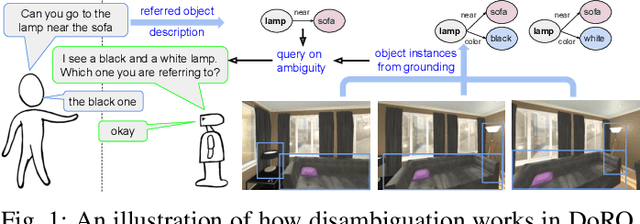
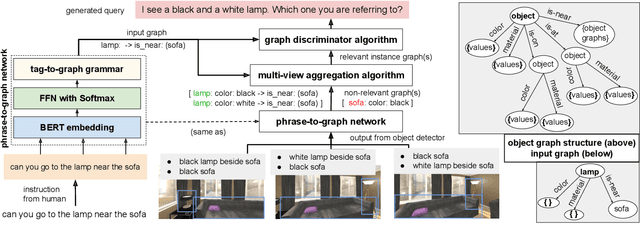
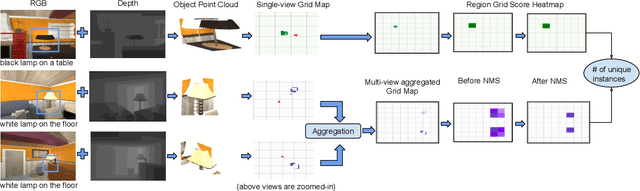
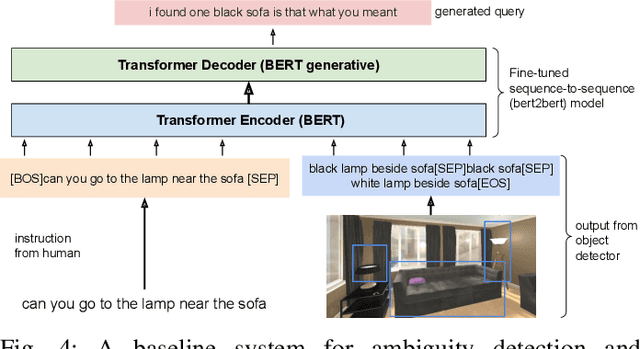
Robotic task instructions often involve a referred object that the robot must locate (ground) within the environment. While task intent understanding is an essential part of natural language understanding, less effort is made to resolve ambiguity that may arise while grounding the task. Existing works use vision-based task grounding and ambiguity detection, suitable for a fixed view and a static robot. However, the problem magnifies for a mobile robot, where the ideal view is not known beforehand. Moreover, a single view may not be sufficient to locate all the object instances in the given area, which leads to inaccurate ambiguity detection. Human intervention is helpful only if the robot can convey the kind of ambiguity it is facing. In this article, we present DoRO (Disambiguation of Referred Object), a system that can help an embodied agent to disambiguate the referred object by raising a suitable query whenever required. Given an area where the intended object is, DoRO finds all the instances of the object by aggregating observations from multiple views while exploring & scanning the area. It then raises a suitable query using the information from the grounded object instances. Experiments conducted with the AI2Thor simulator show that DoRO not only detects the ambiguity more accurately but also raises verbose queries with more accurate information from the visual-language grounding.
A Perspective on Robotic Telepresence and Teleoperation using Cognition: Are we there yet?
Mar 06, 2022



Telepresence and teleoperation robotics have attracted a great amount of attention in the last 10 years. With the Artificial Intelligence (AI) revolution already being started, we can see a wide range of robotic applications being realized. Intelligent robotic systems are being deployed both in industrial and domestic environments. Telepresence is the idea of being present in a remote location virtually or via robotic avatars. Similarly, the idea of operating a robot from a remote location for various tasks is called teleoperation. These technologies find significant application in health care, education, surveillance, disaster recovery, and corporate/government sectors. But question still remains about their maturity, security and safety levels. We also need to think about enhancing the user experience and trust in such technologies going into the next generation of computing.
Sharing Cognition: Human Gesture and Natural Language Grounding Based Planning and Navigation for Indoor Robots
Aug 14, 2021
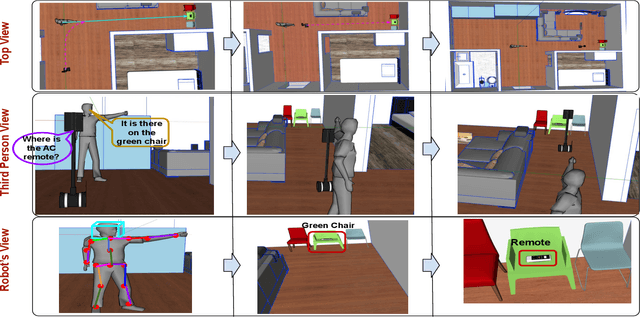
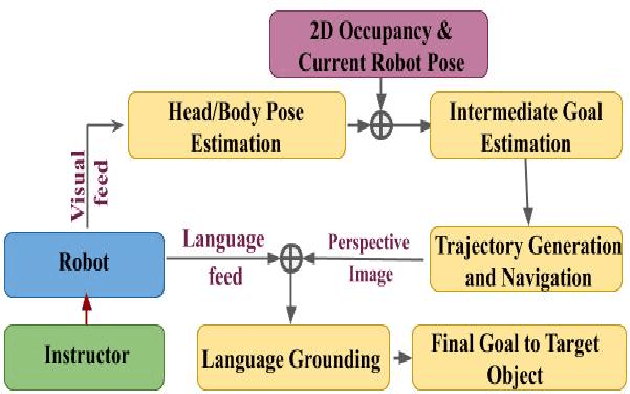
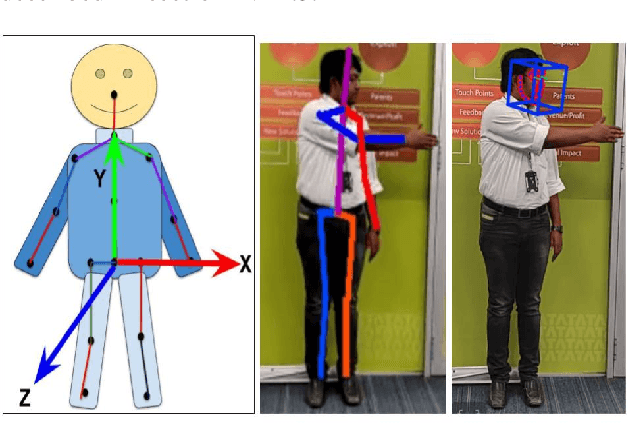
Cooperation among humans makes it easy to execute tasks and navigate seamlessly even in unknown scenarios. With our individual knowledge and collective cognition skills, we can reason about and perform well in unforeseen situations and environments. To achieve a similar potential for a robot navigating among humans and interacting with them, it is crucial for it to acquire the ability for easy, efficient and natural ways of communication and cognition sharing with humans. In this work, we aim to exploit human gestures which is known to be the most prominent modality of communication after the speech. We demonstrate how the incorporation of gestures for communicating spatial understanding can be achieved in a very simple yet effective way using a robot having the vision and listening capability. This shows a big advantage over using only Vision and Language-based Navigation, Language Grounding or Human-Robot Interaction in a task requiring the development of cognition and indoor navigation. We adapt the state-of-the-art modules of Language Grounding and Human-Robot Interaction to demonstrate a novel system pipeline in real-world environments on a Telepresence robot for performing a set of challenging tasks. To the best of our knowledge, this is the first pipeline to couple the fields of HRI and language grounding in an indoor environment to demonstrate autonomous navigation.