 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Social Motion Latent Space and Human Awareness for Effective Robot Navigation in Crowded Environments
Oct 11, 2023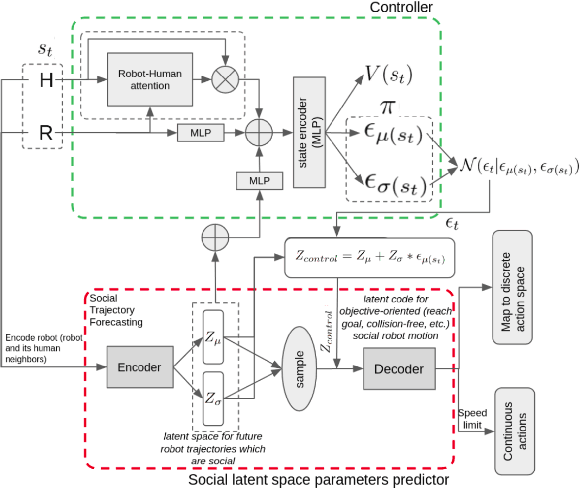
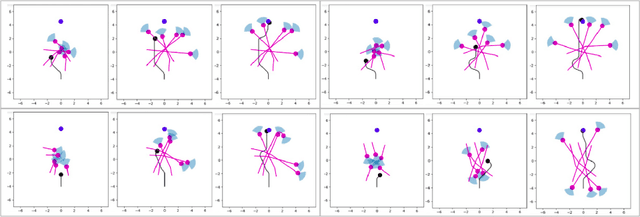
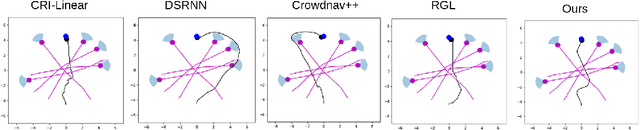
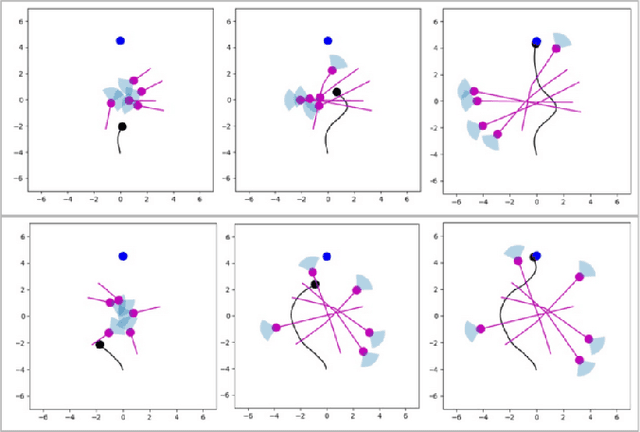
This work proposes a novel approach to social robot navigation by learning to generate robot controls from a social motion latent space. By leveraging this social motion latent space, the proposed method achieves significant improvements in social navigation metrics such as success rate, navigation time, and trajectory length while producing smoother (less jerk and angular deviations) and more anticipatory trajectories. The superiority of the proposed method is demonstrated through comparison with baseline models in various scenarios. Additionally, the concept of humans' awareness towards the robot is introduced into the social robot navigation framework, showing that incorporating human awareness leads to shorter and smoother trajectories owing to humans' ability to positively interact with the robot.
Sharing Cognition: Human Gesture and Natural Language Grounding Based Planning and Navigation for Indoor Robots
Aug 14, 2021
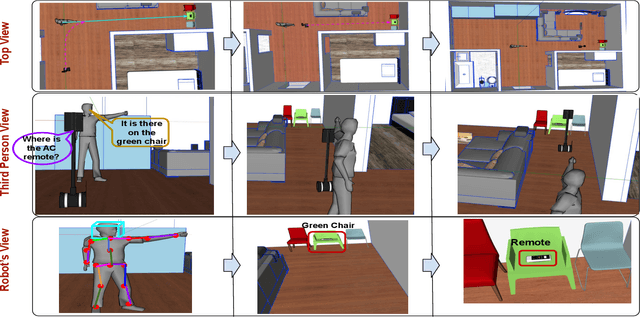
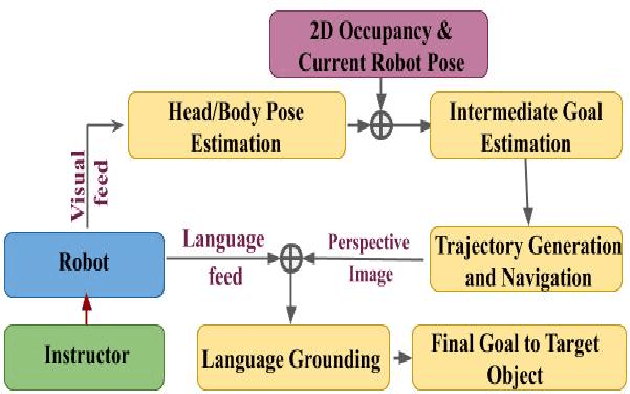
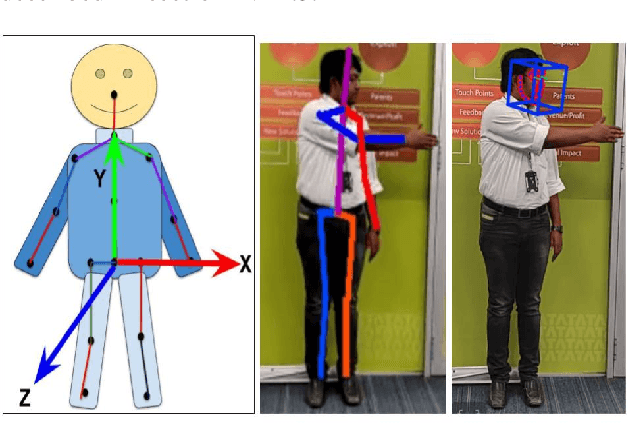
Cooperation among humans makes it easy to execute tasks and navigate seamlessly even in unknown scenarios. With our individual knowledge and collective cognition skills, we can reason about and perform well in unforeseen situations and environments. To achieve a similar potential for a robot navigating among humans and interacting with them, it is crucial for it to acquire the ability for easy, efficient and natural ways of communication and cognition sharing with humans. In this work, we aim to exploit human gestures which is known to be the most prominent modality of communication after the speech. We demonstrate how the incorporation of gestures for communicating spatial understanding can be achieved in a very simple yet effective way using a robot having the vision and listening capability. This shows a big advantage over using only Vision and Language-based Navigation, Language Grounding or Human-Robot Interaction in a task requiring the development of cognition and indoor navigation. We adapt the state-of-the-art modules of Language Grounding and Human-Robot Interaction to demonstrate a novel system pipeline in real-world environments on a Telepresence robot for performing a set of challenging tasks. To the best of our knowledge, this is the first pipeline to couple the fields of HRI and language grounding in an indoor environment to demonstrate autonomous navigation.
DeepMPCVS: Deep Model Predictive Control for Visual Servoing
May 03, 2021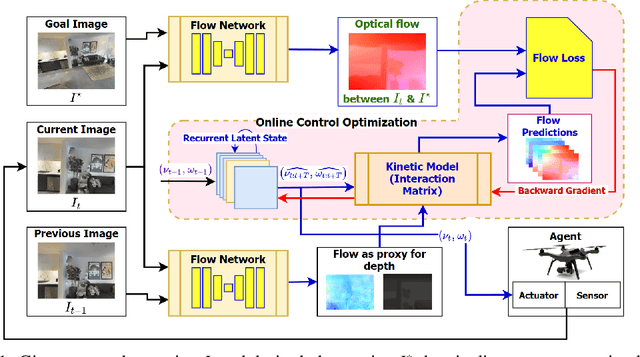
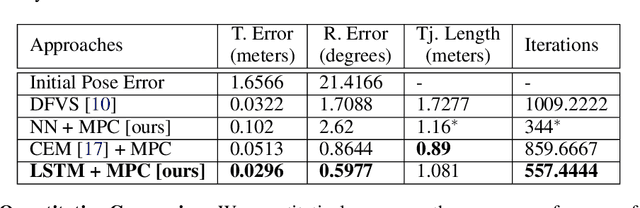

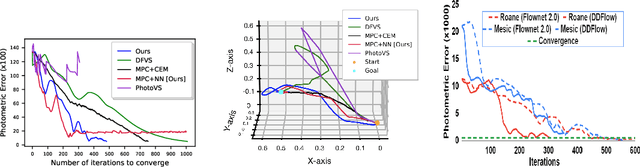
The simplicity of the visual servoing approach makes it an attractive option for tasks dealing with vision-based control of robots in many real-world applications. However, attaining precise alignment for unseen environments pose a challenge to existing visual servoing approaches. While classical approaches assume a perfect world, the recent data-driven approaches face issues when generalizing to novel environments. In this paper, we aim to combine the best of both worlds. We present a deep model predictive visual servoing framework that can achieve precise alignment with optimal trajectories and can generalize to novel environments. Our framework consists of a deep network for optical flow predictions, which are used along with a predictive model to forecast future optical flow. For generating an optimal set of velocities we present a control network that can be trained on the fly without any supervision. Through extensive simulations on photo-realistic indoor settings of the popular Habitat framework, we show significant performance gain due to the proposed formulation vis-a-vis recent state-of-the-art methods. Specifically, we show a faster convergence and an improved performance in trajectory length over recent approaches.
* Accepted at 4th Annual Conference on Robot Learning, CoRL 2020, Cambridge, MA, USA, November 16 - November 18, 2020
A Hierarchical Network for Diverse Trajectory Proposals
Jun 09, 2019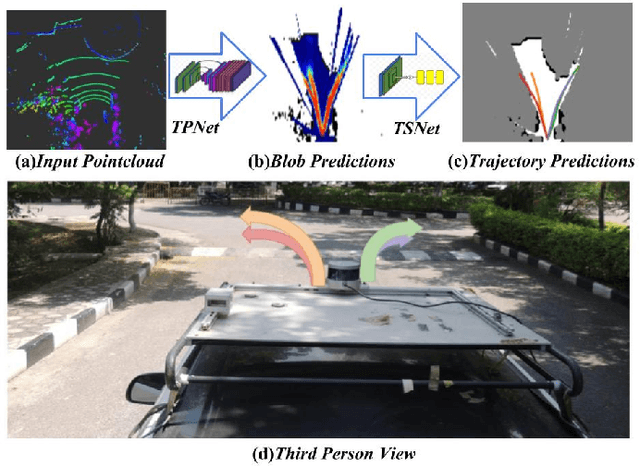
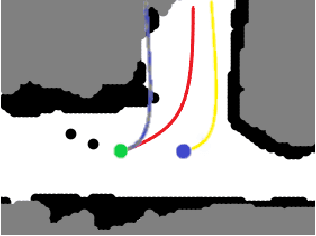
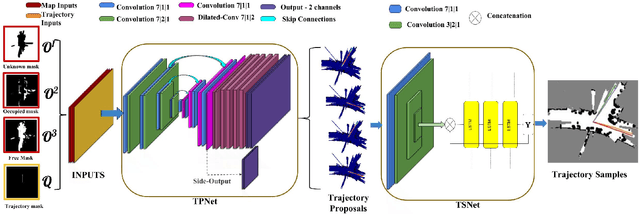

Autonomous explorative robots frequently encounter scenarios where multiple future trajectories can be pursued. Often these are cases with multiple paths around an obstacle or trajectory options towards various frontiers. Humans in such situations can inherently perceive and reason about the surrounding environment to identify several possibilities of either manoeuvring around the obstacles or moving towards various frontiers. In this work, we propose a 2 stage Convolutional Neural Network architecture which mimics such an ability to map the perceived surroundings to multiple trajectories that a robot can choose to traverse. The first stage is a Trajectory Proposal Network which suggests diverse regions in the environment which can be occupied in the future. The second stage is a Trajectory Sampling network which provides a finegrained trajectory over the regions proposed by Trajectory Proposal Network. We evaluate our framework in diverse and complicated real life settings. For the outdoor case, we use the KITTI dataset and our own outdoor driving dataset. In the indoor setting, we use an autonomous drone to navigate various scenarios and also a ground robot which can explore the environment using the trajectories proposed by our framework. Our experiments suggest that the framework is able to develop a semantic understanding of the obstacles, open regions and identify diverse trajectories that a robot can traverse. Our comparisons portray the performance gain of the proposed architecture over a diverse set of methods against which it is compared.
Exploring Convolutional Networks for End-to-End Visual Servoing
Jun 10, 2017



Present image based visual servoing approaches rely on extracting hand crafted visual features from an image. Choosing the right set of features is important as it directly affects the performance of any approach. Motivated by recent breakthroughs in performance of data driven methods on recognition and localization tasks, we aim to learn visual feature representations suitable for servoing tasks in unstructured and unknown environments. In this paper, we present an end-to-end learning based approach for visual servoing in diverse scenes where the knowledge of camera parameters and scene geometry is not available a priori. This is achieved by training a convolutional neural network over color images with synchronised camera poses. Through experiments performed in simulation and on a quadrotor, we demonstrate the efficacy and robustness of our approach for a wide range of camera poses in both indoor as well as outdoor environments.