 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCity-Mesh3R: Simulation-Ready City-Scale 3D Mesh Reconstruction from Multi-View Images
May 28, 2026City-scale 3D surface reconstruction from multiview images for downstream 3D simulation, poses highly challenging problems due to the scale and complexity of urban scenes. Existing city-scale 3D reconstruction methods based on NeRF, Gaussian Splatting etc. often fail to recover 3D meshes ready for simulation due to incomplete/missing geometry and irregular, noisy surfaces. Scaling existing small-scale 3D reconstruction methods to arbitrarily large urban scenes is highly infeasible due to their computational complexity. We present City-Mesh3R, a scalable framework for reconstructing watertight surface meshes directly from large unordered image collections. Unlike recent methods which use global sparse SfM point-cloud initialization followed by a distributed 3D dense reconstruction of large-scale scenes, our method follows an end-to-end images-to-mesh 3D reconstruction approach using a divide-and-conquer strategy. The sparse city map is reconstructed via topological image clustering, cluster-wise independent sparse SfM and map merging, without need for exhaustive image feature matching. Then this map is partitioned spatially to perform geometry-aware camera selection, followed by dense surface reconstruction and surface refinement using curvature-aware adaptive vertex density remeshing. These partition meshes are then stitched together to produce the global mesh of the city. The proposed end-to-end framework is evaluated on city-scale reconstruction datasets. As demonstrated by our qualitative and quantitative results, our proposed method yields high-fidelity watertight 3D meshes with regular geometry, capturing fine surface details, and is suitable for scaling to arbitrarily large scenes owing to the end-to-end processing in a distributed setting.
Anticipate & Act : Integrating LLMs and Classical Planning for Efficient Task Execution in Household Environments
Feb 04, 2025



Assistive agents performing household tasks such as making the bed or cooking breakfast often compute and execute actions that accomplish one task at a time. However, efficiency can be improved by anticipating upcoming tasks and computing an action sequence that jointly achieves these tasks. State-of-the-art methods for task anticipation use data-driven deep networks and Large Language Models (LLMs), but they do so at the level of high-level tasks and/or require many training examples. Our framework leverages the generic knowledge of LLMs through a small number of prompts to perform high-level task anticipation, using the anticipated tasks as goals in a classical planning system to compute a sequence of finer-granularity actions that jointly achieve these goals. We ground and evaluate our framework's abilities in realistic scenarios in the VirtualHome environment and demonstrate a 31% reduction in execution time compared with a system that does not consider upcoming tasks.
GPD: Guided Polynomial Diffusion for Motion Planning
Jan 30, 2025



Diffusion-based motion planners are becoming popular due to their well-established performance improvements, stemming from sample diversity and the ease of incorporating new constraints directly during inference. However, a primary limitation of the diffusion process is the requirement for a substantial number of denoising steps, especially when the denoising process is coupled with gradient-based guidance. In this paper, we introduce, diffusion in the parametric space of trajectories, where the parameters are represented as Bernstein coefficients. We show that this representation greatly improves the effectiveness of the cost function guidance and the inference speed. We also introduce a novel stitching algorithm that leverages the diversity in diffusion-generated trajectories to produce collision-free trajectories with just a single cost function-guided model. We demonstrate that our approaches outperform current SOTA diffusion-based motion planners for manipulators and provide an ablation study on key components.
MPVO: Motion-Prior based Visual Odometry for PointGoal Navigation
Nov 07, 2024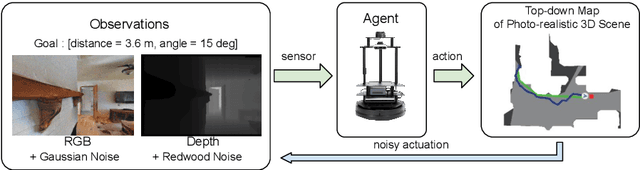
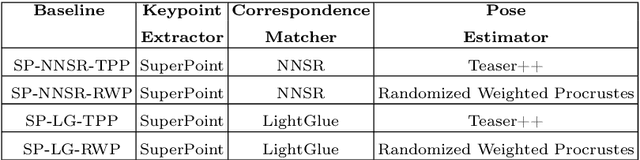
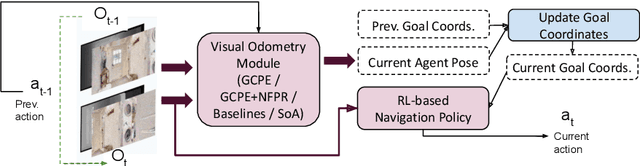
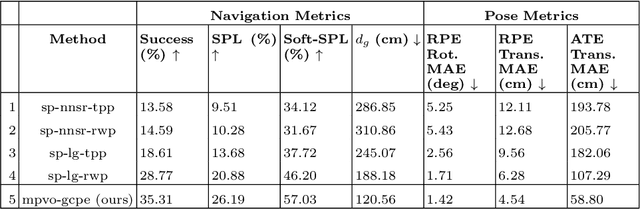
Visual odometry (VO) is essential for enabling accurate point-goal navigation of embodied agents in indoor environments where GPS and compass sensors are unreliable and inaccurate. However, traditional VO methods face challenges in wide-baseline scenarios, where fast robot motions and low frames per second (FPS) during inference hinder their performance, leading to drift and catastrophic failures in point-goal navigation. Recent deep-learned VO methods show robust performance but suffer from sample inefficiency during training; hence, they require huge datasets and compute resources. So, we propose a robust and sample-efficient VO pipeline based on motion priors available while an agent is navigating an environment. It consists of a training-free action-prior based geometric VO module that estimates a coarse relative pose which is further consumed as a motion prior by a deep-learned VO model, which finally produces a fine relative pose to be used by the navigation policy. This strategy helps our pipeline achieve up to 2x sample efficiency during training and demonstrates superior accuracy and robustness in point-goal navigation tasks compared to state-of-the-art VO method(s). Realistic indoor environments of the Gibson dataset is used in the AI-Habitat simulator to evaluate the proposed approach using navigation metrics (like success/SPL) and pose metrics (like RPE/ATE). We hope this method further opens a direction of work where motion priors from various sources can be utilized to improve VO estimates and achieve better results in embodied navigation tasks.
Task Planning for Object Rearrangement in Multi-room Environments
Jun 01, 2024



Object rearrangement in a multi-room setup should produce a reasonable plan that reduces the agent's overall travel and the number of steps. Recent state-of-the-art methods fail to produce such plans because they rely on explicit exploration for discovering unseen objects due to partial observability and a heuristic planner to sequence the actions for rearrangement. This paper proposes a novel hierarchical task planner to efficiently plan a sequence of actions to discover unseen objects and rearrange misplaced objects within an untidy house to achieve a desired tidy state. The proposed method introduces several novel techniques, including (i) a method for discovering unseen objects using commonsense knowledge from large language models, (ii) a collision resolution and buffer prediction method based on Cross-Entropy Method to handle blocked goal and swap cases, (iii) a directed spatial graph-based state space for scalability, and (iv) deep reinforcement learning (RL) for producing an efficient planner. The planner interleaves the discovery of unseen objects and rearrangement to minimize the number of steps taken and overall traversal of the agent. The paper also presents new metrics and a benchmark dataset called MoPOR to evaluate the effectiveness of the rearrangement planning in a multi-room setting. The experimental results demonstrate that the proposed method effectively addresses the multi-room rearrangement problem.
Teledrive: An Embodied AI based Telepresence System
Jun 01, 2024



This article presents Teledrive, a telepresence robotic system with embodied AI features that empowers an operator to navigate the telerobot in any unknown remote place with minimal human intervention. We conceive Teledrive in the context of democratizing remote care-giving for elderly citizens as well as for isolated patients, affected by contagious diseases. In particular, this paper focuses on the problem of navigating to a rough target area (like bedroom or kitchen) rather than pre-specified point destinations. This ushers in a unique AreaGoal based navigation feature, which has not been explored in depth in the contemporary solutions. Further, we describe an edge computing-based software system built on a WebRTC-based communication framework to realize the aforementioned scheme through an easy-to-use speech-based human-robot interaction. Moreover, to enhance the ease of operation for the remote caregiver, we incorporate a person following feature, whereby a robot follows a person on the move in its premises as directed by the operator. Moreover, the system presented is loosely coupled with specific robot hardware, unlike the existing solutions. We have evaluated the efficacy of the proposed system through baseline experiments, user study, and real-life deployment.
* Accepted in Journal of Intelligent Robotic System
Enhanced Spatio-Temporal Context for Temporally Consistent Robust 3D Human Motion Recovery from Monocular Videos
Nov 20, 2023



Recovering temporally consistent 3D human body pose, shape and motion from a monocular video is a challenging task due to (self-)occlusions, poor lighting conditions, complex articulated body poses, depth ambiguity, and limited availability of annotated data. Further, doing a simple perframe estimation is insufficient as it leads to jittery and implausible results. In this paper, we propose a novel method for temporally consistent motion estimation from a monocular video. Instead of using generic ResNet-like features, our method uses a body-aware feature representation and an independent per-frame pose and camera initialization over a temporal window followed by a novel spatio-temporal feature aggregation by using a combination of self-similarity and self-attention over the body-aware features and the perframe initialization. Together, they yield enhanced spatiotemporal context for every frame by considering remaining past and future frames. These features are used to predict the pose and shape parameters of the human body model, which are further refined using an LSTM. Experimental results on the publicly available benchmark data show that our method attains significantly lower acceleration error and outperforms the existing state-of-the-art methods over all key quantitative evaluation metrics, including complex scenarios like partial occlusion, complex poses and even relatively low illumination.
Exploring Social Motion Latent Space and Human Awareness for Effective Robot Navigation in Crowded Environments
Oct 11, 2023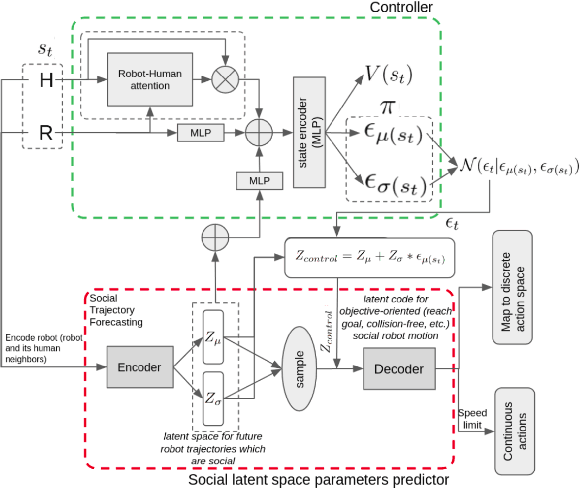
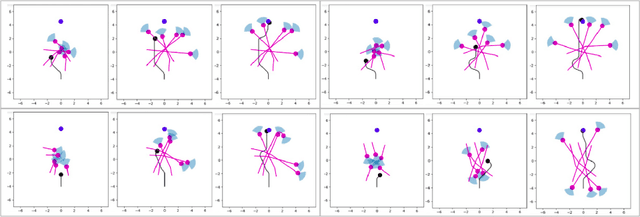
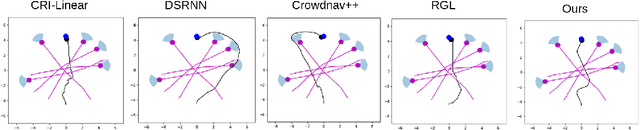
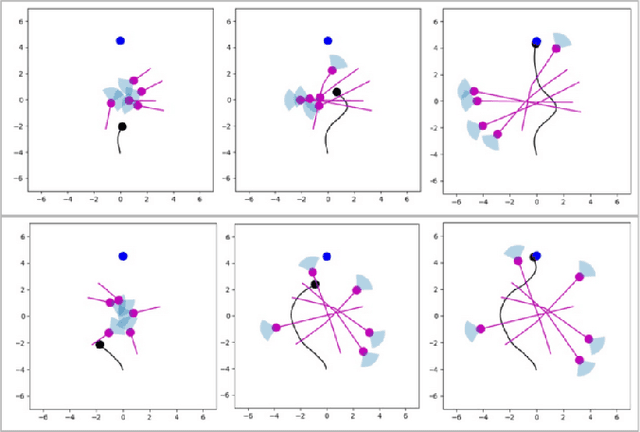
This work proposes a novel approach to social robot navigation by learning to generate robot controls from a social motion latent space. By leveraging this social motion latent space, the proposed method achieves significant improvements in social navigation metrics such as success rate, navigation time, and trajectory length while producing smoother (less jerk and angular deviations) and more anticipatory trajectories. The superiority of the proposed method is demonstrated through comparison with baseline models in various scenarios. Additionally, the concept of humans' awareness towards the robot is introduced into the social robot navigation framework, showing that incorporating human awareness leads to shorter and smoother trajectories owing to humans' ability to positively interact with the robot.
CLIPGraphs: Multimodal Graph Networks to Infer Object-Room Affinities
Jun 02, 2023



This paper introduces a novel method for determining the best room to place an object in, for embodied scene rearrangement. While state-of-the-art approaches rely on large language models (LLMs) or reinforcement learned (RL) policies for this task, our approach, CLIPGraphs, efficiently combines commonsense domain knowledge, data-driven methods, and recent advances in multimodal learning. Specifically, it (a)encodes a knowledge graph of prior human preferences about the room location of different objects in home environments, (b) incorporates vision-language features to support multimodal queries based on images or text, and (c) uses a graph network to learn object-room affinities based on embeddings of the prior knowledge and the vision-language features. We demonstrate that our approach provides better estimates of the most appropriate location of objects from a benchmark set of object categories in comparison with state-of-the-art baselines
Sequence-Agnostic Multi-Object Navigation
May 10, 2023The Multi-Object Navigation (MultiON) task requires a robot to localize an instance (each) of multiple object classes. It is a fundamental task for an assistive robot in a home or a factory. Existing methods for MultiON have viewed this as a direct extension of Object Navigation (ON), the task of localising an instance of one object class, and are pre-sequenced, i.e., the sequence in which the object classes are to be explored is provided in advance. This is a strong limitation in practical applications characterized by dynamic changes. This paper describes a deep reinforcement learning framework for sequence-agnostic MultiON based on an actor-critic architecture and a suitable reward specification. Our framework leverages past experiences and seeks to reward progress toward individual as well as multiple target object classes. We use photo-realistic scenes from the Gibson benchmark dataset in the AI Habitat 3D simulation environment to experimentally show that our method performs better than a pre-sequenced approach and a state of the art ON method extended to MultiON.