 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnticipate, Adapt, Act: A Hybrid Framework for Task Planning
Feb 23, 2026Anticipating and adapting to failures is a key capability robots need to collaborate effectively with humans in complex domains. This continues to be a challenge despite the impressive performance of state of the art AI planning systems and Large Language Models (LLMs) because of the uncertainty associated with the tasks and their outcomes. Toward addressing this challenge, we present a hybrid framework that integrates the generic prediction capabilities of an LLM with the probabilistic sequential decision-making capability of Relational Dynamic Influence Diagram Language. For any given task, the robot reasons about the task and the capabilities of the human attempting to complete it; predicts potential failures due to lack of ability (in the human) or lack of relevant domain objects; and executes actions to prevent such failures or recover from them. Experimental evaluation in the VirtualHome 3D simulation environment demonstrates substantial improvement in performance compared with state of the art baselines.
Discovering Coordinated Joint Options via Inter-Agent Relative Dynamics
Dec 31, 2025Temporally extended actions improve the ability to explore and plan in single-agent settings. In multi-agent settings, the exponential growth of the joint state space with the number of agents makes coordinated behaviours even more valuable. Yet, this same exponential growth renders the design of multi-agent options particularly challenging. Existing multi-agent option discovery methods often sacrifice coordination by producing loosely coupled or fully independent behaviours. Toward addressing these limitations, we describe a novel approach for multi-agent option discovery. Specifically, we propose a joint-state abstraction that compresses the state space while preserving the information necessary to discover strongly coordinated behaviours. Our approach builds on the inductive bias that synchronisation over agent states provides a natural foundation for coordination in the absence of explicit objectives. We first approximate a fictitious state of maximal alignment with the team, the \textit{Fermat} state, and use it to define a measure of \textit{spreadness}, capturing team-level misalignment on each individual state dimension. Building on this representation, we then employ a neural graph Laplacian estimator to derive options that capture state synchronisation patterns between agents. We evaluate the resulting options across multiple scenarios in two multi-agent domains, showing that they yield stronger downstream coordination capabilities compared to alternative option discovery methods.
Generic-to-Specific Reasoning and Learning for Scalable Ad Hoc Teamwork
Aug 06, 2025AI agents deployed in assistive roles often have to collaborate with other agents (humans, AI systems) without prior coordination. Methods considered state of the art for such ad hoc teamwork often pursue a data-driven approach that needs a large labeled dataset of prior observations, lacks transparency, and makes it difficult to rapidly revise existing knowledge in response to changes. As the number of agents increases, the complexity of decision-making makes it difficult to collaborate effectively. This paper advocates leveraging the complementary strengths of knowledge-based and data-driven methods for reasoning and learning for ad hoc teamwork. For any given goal, our architecture enables each ad hoc agent to determine its actions through non-monotonic logical reasoning with: (a) prior commonsense domain-specific knowledge; (b) models learned and revised rapidly to predict the behavior of other agents; and (c) anticipated abstract future goals based on generic knowledge of similar situations in an existing foundation model. We experimentally evaluate our architecture's capabilities in VirtualHome, a realistic physics-based 3D simulation environment.
AdaptBot: Combining LLM with Knowledge Graphs and Human Input for Generic-to-Specific Task Decomposition and Knowledge Refinement
Feb 04, 2025Embodied agents assisting humans are often asked to complete a new task in a new scenario. An agent preparing a particular dish in the kitchen based on a known recipe may be asked to prepare a new dish or to perform cleaning tasks in the storeroom. There may not be sufficient resources, e.g., time or labeled examples, to train the agent for these new situations. Large Language Models (LLMs) trained on considerable knowledge across many domains are able to predict a sequence of abstract actions for such new tasks and scenarios, although it may not be possible for the agent to execute this action sequence due to task-, agent-, or domain-specific constraints. Our framework addresses these challenges by leveraging the generic predictions provided by LLM and the prior domain-specific knowledge encoded in a Knowledge Graph (KG), enabling an agent to quickly adapt to new tasks and scenarios. The robot also solicits and uses human input as needed to refine its existing knowledge. Based on experimental evaluation over cooking and cleaning tasks in simulation domains, we demonstrate that the interplay between LLM, KG, and human input leads to substantial performance gains compared with just using the LLM output.
Anticipate & Act : Integrating LLMs and Classical Planning for Efficient Task Execution in Household Environments
Feb 04, 2025



Assistive agents performing household tasks such as making the bed or cooking breakfast often compute and execute actions that accomplish one task at a time. However, efficiency can be improved by anticipating upcoming tasks and computing an action sequence that jointly achieves these tasks. State-of-the-art methods for task anticipation use data-driven deep networks and Large Language Models (LLMs), but they do so at the level of high-level tasks and/or require many training examples. Our framework leverages the generic knowledge of LLMs through a small number of prompts to perform high-level task anticipation, using the anticipated tasks as goals in a classical planning system to compute a sequence of finer-granularity actions that jointly achieve these goals. We ground and evaluate our framework's abilities in realistic scenarios in the VirtualHome environment and demonstrate a 31% reduction in execution time compared with a system that does not consider upcoming tasks.
Anticipate & Collab: Data-driven Task Anticipation and Knowledge-driven Planning for Human-robot Collaboration
Apr 04, 2024



An agent assisting humans in daily living activities can collaborate more effectively by anticipating upcoming tasks. Data-driven methods represent the state of the art in task anticipation, planning, and related problems, but these methods are resource-hungry and opaque. Our prior work introduced a proof of concept framework that used an LLM to anticipate 3 high-level tasks that served as goals for a classical planning system that computed a sequence of low-level actions for the agent to achieve these goals. This paper describes DaTAPlan, our framework that significantly extends our prior work toward human-robot collaboration. Specifically, DaTAPlan planner computes actions for an agent and a human to collaboratively and jointly achieve the tasks anticipated by the LLM, and the agent automatically adapts to unexpected changes in human action outcomes and preferences. We evaluate DaTAPlan capabilities in a realistic simulation environment, demonstrating accurate task anticipation, effective human-robot collaboration, and the ability to adapt to unexpected changes. Project website: https://dataplan-hrc.github.io
Relevance Score: A Landmark-Like Heuristic for Planning
Mar 12, 2024

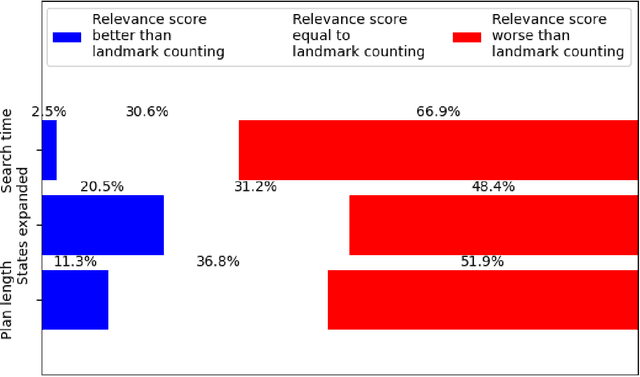
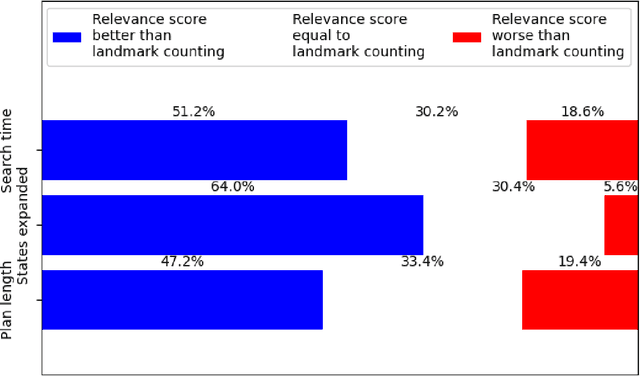
Landmarks are facts or actions that appear in all valid solutions of a planning problem. They have been used successfully to calculate heuristics that guide the search for a plan. We investigate an extension to this concept by defining a novel "relevance score" that helps identify facts or actions that appear in most but not all plans to achieve any given goal. We describe an approach to compute this relevance score and use it as a heuristic in the search for a plan. We experimentally compare the performance of our approach with that of a state of the art landmark-based heuristic planning approach using benchmark planning problems. While the original landmark-based heuristic leads to better performance on problems with well-defined landmarks, our approach substantially improves performance on problems that lack non-trivial landmarks.
CLIPGraphs: Multimodal Graph Networks to Infer Object-Room Affinities
Jun 02, 2023



This paper introduces a novel method for determining the best room to place an object in, for embodied scene rearrangement. While state-of-the-art approaches rely on large language models (LLMs) or reinforcement learned (RL) policies for this task, our approach, CLIPGraphs, efficiently combines commonsense domain knowledge, data-driven methods, and recent advances in multimodal learning. Specifically, it (a)encodes a knowledge graph of prior human preferences about the room location of different objects in home environments, (b) incorporates vision-language features to support multimodal queries based on images or text, and (c) uses a graph network to learn object-room affinities based on embeddings of the prior knowledge and the vision-language features. We demonstrate that our approach provides better estimates of the most appropriate location of objects from a benchmark set of object categories in comparison with state-of-the-art baselines
Knowledge-based Reasoning and Learning under Partial Observability in Ad Hoc Teamwork
Jun 01, 2023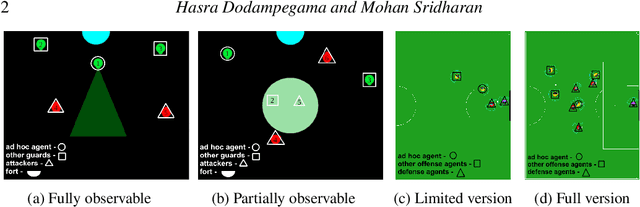

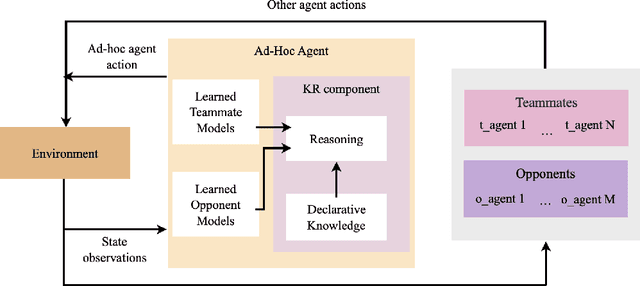
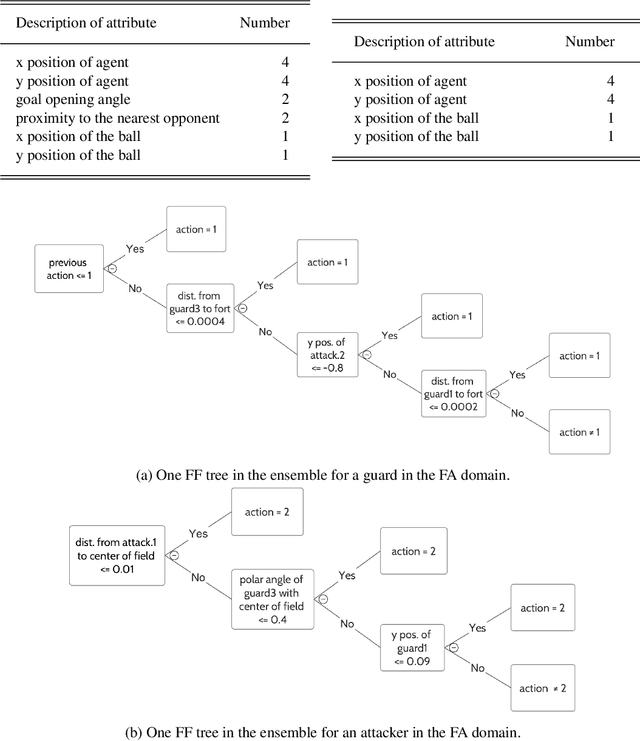
Ad hoc teamwork refers to the problem of enabling an agent to collaborate with teammates without prior coordination. Data-driven methods represent the state of the art in ad hoc teamwork. They use a large labeled dataset of prior observations to model the behavior of other agent types and to determine the ad hoc agent's behavior. These methods are computationally expensive, lack transparency, and make it difficult to adapt to previously unseen changes, e.g., in team composition. Our recent work introduced an architecture that determined an ad hoc agent's behavior based on non-monotonic logical reasoning with prior commonsense domain knowledge and predictive models of other agents' behavior that were learned from limited examples. In this paper, we substantially expand the architecture's capabilities to support: (a) online selection, adaptation, and learning of the models that predict the other agents' behavior; and (b) collaboration with teammates in the presence of partial observability and limited communication. We illustrate and experimentally evaluate the capabilities of our architecture in two simulated multiagent benchmark domains for ad hoc teamwork: Fort Attack and Half Field Offense. We show that the performance of our architecture is comparable or better than state of the art data-driven baselines in both simple and complex scenarios, particularly in the presence of limited training data, partial observability, and changes in team composition.
RAMP: A Benchmark for Evaluating Robotic Assembly Manipulation and Planning
May 16, 2023

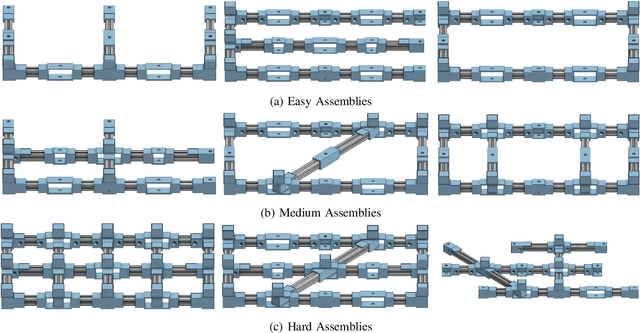

We introduce RAMP, an open-source robotics benchmark inspired by real-world industrial assembly tasks. RAMP consists of beams that a robot must assemble into specified goal configurations using pegs as fasteners. As such it assesses planning and execution capabilities, and poses challenges in perception, reasoning, manipulation, diagnostics, fault recovery and goal parsing. RAMP has been designed to be accessible and extensible. Parts are either 3D printed or otherwise constructed from materials that are readily obtainable. The part design and detailed instructions are publicly available. In order to broaden community engagement, RAMP incorporates fixtures such as April Tags which enable researchers to focus on individual sub-tasks of the assembly challenge if desired. We provide a full digital twin as well as rudimentary baselines to enable rapid progress. Our vision is for RAMP to form the substrate for a community-driven endeavour that evolves as capability matures.