 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocate 3D: Real-World Object Localization via Self-Supervised Learning in 3D
Apr 19, 2025We present LOCATE 3D, a model for localizing objects in 3D scenes from referring expressions like "the small coffee table between the sofa and the lamp." LOCATE 3D sets a new state-of-the-art on standard referential grounding benchmarks and showcases robust generalization capabilities. Notably, LOCATE 3D operates directly on sensor observation streams (posed RGB-D frames), enabling real-world deployment on robots and AR devices. Key to our approach is 3D-JEPA, a novel self-supervised learning (SSL) algorithm applicable to sensor point clouds. It takes as input a 3D pointcloud featurized using 2D foundation models (CLIP, DINO). Subsequently, masked prediction in latent space is employed as a pretext task to aid the self-supervised learning of contextualized pointcloud features. Once trained, the 3D-JEPA encoder is finetuned alongside a language-conditioned decoder to jointly predict 3D masks and bounding boxes. Additionally, we introduce LOCATE 3D DATASET, a new dataset for 3D referential grounding, spanning multiple capture setups with over 130K annotations. This enables a systematic study of generalization capabilities as well as a stronger model.
SparseLoc: Sparse Open-Set Landmark-based Global Localization for Autonomous Navigation
Mar 30, 2025



Global localization is a critical problem in autonomous navigation, enabling precise positioning without reliance on GPS. Modern global localization techniques often depend on dense LiDAR maps, which, while precise, require extensive storage and computational resources. Recent approaches have explored alternative methods, such as sparse maps and learned features, but they suffer from poor robustness and generalization. We propose SparseLoc, a global localization framework that leverages vision-language foundation models to generate sparse, semantic-topometric maps in a zero-shot manner. It combines this map representation with a Monte Carlo localization scheme enhanced by a novel late optimization strategy, ensuring improved pose estimation. By constructing compact yet highly discriminative maps and refining localization through a carefully designed optimization schedule, SparseLoc overcomes the limitations of existing techniques, offering a more efficient and robust solution for global localization. Our system achieves over a 5X improvement in localization accuracy compared to existing sparse mapping techniques. Despite utilizing only 1/500th of the points of dense mapping methods, it achieves comparable performance, maintaining an average global localization error below 5m and 2 degrees on KITTI sequences.
Anticipate & Act : Integrating LLMs and Classical Planning for Efficient Task Execution in Household Environments
Feb 04, 2025



Assistive agents performing household tasks such as making the bed or cooking breakfast often compute and execute actions that accomplish one task at a time. However, efficiency can be improved by anticipating upcoming tasks and computing an action sequence that jointly achieves these tasks. State-of-the-art methods for task anticipation use data-driven deep networks and Large Language Models (LLMs), but they do so at the level of high-level tasks and/or require many training examples. Our framework leverages the generic knowledge of LLMs through a small number of prompts to perform high-level task anticipation, using the anticipated tasks as goals in a classical planning system to compute a sequence of finer-granularity actions that jointly achieve these goals. We ground and evaluate our framework's abilities in realistic scenarios in the VirtualHome environment and demonstrate a 31% reduction in execution time compared with a system that does not consider upcoming tasks.
PickScan: Object discovery and reconstruction from handheld interactions
Nov 17, 2024



Reconstructing compositional 3D representations of scenes, where each object is represented with its own 3D model, is a highly desirable capability in robotics and augmented reality. However, most existing methods rely heavily on strong appearance priors for object discovery, therefore only working on those classes of objects on which the method has been trained, or do not allow for object manipulation, which is necessary to scan objects fully and to guide object discovery in challenging scenarios. We address these limitations with a novel interaction-guided and class-agnostic method based on object displacements that allows a user to move around a scene with an RGB-D camera, hold up objects, and finally outputs one 3D model per held-up object. Our main contribution to this end is a novel approach to detecting user-object interactions and extracting the masks of manipulated objects. On a custom-captured dataset, our pipeline discovers manipulated objects with 78.3% precision at 100% recall and reconstructs them with a mean chamfer distance of 0.90cm. Compared to Co-Fusion, the only comparable interaction-based and class-agnostic baseline, this corresponds to a reduction in chamfer distance of 73% while detecting 99% fewer false positives.
Gaussian Splatting Visual MPC for Granular Media Manipulation
Oct 13, 2024



Recent advancements in learned 3D representations have enabled significant progress in solving complex robotic manipulation tasks, particularly for rigid-body objects. However, manipulating granular materials such as beans, nuts, and rice, remains challenging due to the intricate physics of particle interactions, high-dimensional and partially observable state, inability to visually track individual particles in a pile, and the computational demands of accurate dynamics prediction. Current deep latent dynamics models often struggle to generalize in granular material manipulation due to a lack of inductive biases. In this work, we propose a novel approach that learns a visual dynamics model over Gaussian splatting representations of scenes and leverages this model for manipulating granular media via Model-Predictive Control. Our method enables efficient optimization for complex manipulation tasks on piles of granular media. We evaluate our approach in both simulated and real-world settings, demonstrating its ability to solve unseen planning tasks and generalize to new environments in a zero-shot transfer. We also show significant prediction and manipulation performance improvements compared to existing granular media manipulation methods.
ConceptAgent: LLM-Driven Precondition Grounding and Tree Search for Robust Task Planning and Execution
Oct 08, 2024



Robotic planning and execution in open-world environments is a complex problem due to the vast state spaces and high variability of task embodiment. Recent advances in perception algorithms, combined with Large Language Models (LLMs) for planning, offer promising solutions to these challenges, as the common sense reasoning capabilities of LLMs provide a strong heuristic for efficiently searching the action space. However, prior work fails to address the possibility of hallucinations from LLMs, which results in failures to execute the planned actions largely due to logical fallacies at high- or low-levels. To contend with automation failure due to such hallucinations, we introduce ConceptAgent, a natural language-driven robotic platform designed for task execution in unstructured environments. With a focus on scalability and reliability of LLM-based planning in complex state and action spaces, we present innovations designed to limit these shortcomings, including 1) Predicate Grounding to prevent and recover from infeasible actions, and 2) an embodied version of LLM-guided Monte Carlo Tree Search with self reflection. In simulation experiments, ConceptAgent achieved a 19% task completion rate across three room layouts and 30 easy level embodied tasks outperforming other state-of-the-art LLM-driven reasoning baselines that scored 10.26% and 8.11% on the same benchmark. Additionally, ablation studies on moderate to hard embodied tasks revealed a 20% increase in task completion from the baseline agent to the fully enhanced ConceptAgent, highlighting the individual and combined contributions of Predicate Grounding and LLM-guided Tree Search to enable more robust automation in complex state and action spaces.
Efficient 3D Instance Mapping and Localization with Neural Fields
Apr 01, 2024
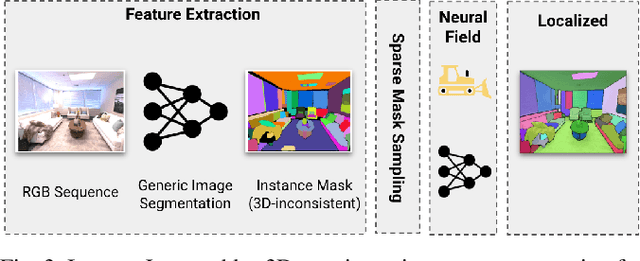


We tackle the problem of learning an implicit scene representation for 3D instance segmentation from a sequence of posed RGB images. Towards this, we introduce 3DIML, a novel framework that efficiently learns a label field that may be rendered from novel viewpoints to produce view-consistent instance segmentation masks. 3DIML significantly improves upon training and inference runtimes of existing implicit scene representation based methods. Opposed to prior art that optimizes a neural field in a self-supervised manner, requiring complicated training procedures and loss function design, 3DIML leverages a two-phase process. The first phase, InstanceMap, takes as input 2D segmentation masks of the image sequence generated by a frontend instance segmentation model, and associates corresponding masks across images to 3D labels. These almost view-consistent pseudolabel masks are then used in the second phase, InstanceLift, to supervise the training of a neural label field, which interpolates regions missed by InstanceMap and resolves ambiguities. Additionally, we introduce InstanceLoc, which enables near realtime localization of instance masks given a trained label field and an off-the-shelf image segmentation model by fusing outputs from both. We evaluate 3DIML on sequences from the Replica and ScanNet datasets and demonstrate 3DIML's effectiveness under mild assumptions for the image sequences. We achieve a large practical speedup over existing implicit scene representation methods with comparable quality, showcasing its potential to facilitate faster and more effective 3D scene understanding.
SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM
Dec 04, 2023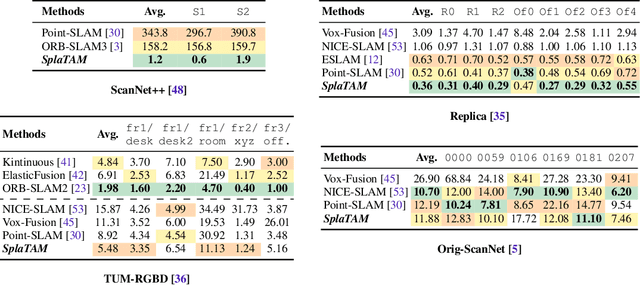
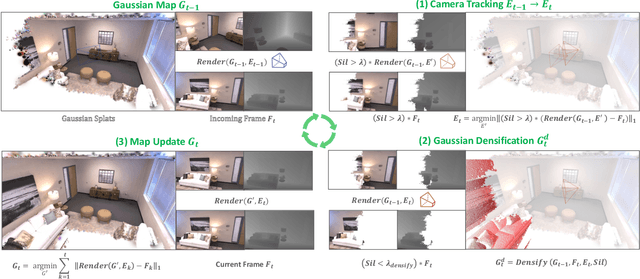
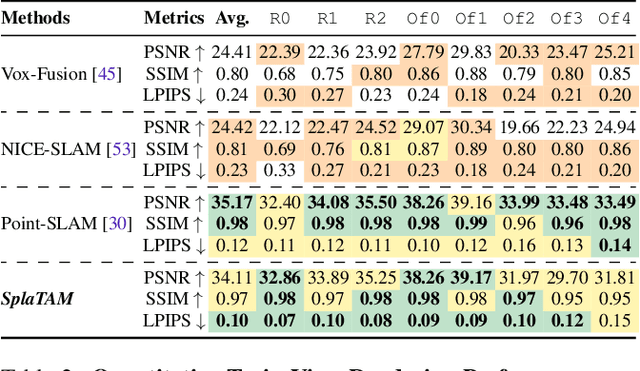

Dense simultaneous localization and mapping (SLAM) is pivotal for embodied scene understanding. Recent work has shown that 3D Gaussians enable high-quality reconstruction and real-time rendering of scenes using multiple posed cameras. In this light, we show for the first time that representing a scene by 3D Gaussians can enable dense SLAM using a single unposed monocular RGB-D camera. Our method, SplaTAM, addresses the limitations of prior radiance field-based representations, including fast rendering and optimization, the ability to determine if areas have been previously mapped, and structured map expansion by adding more Gaussians. We employ an online tracking and mapping pipeline while tailoring it to specifically use an underlying Gaussian representation and silhouette-guided optimization via differentiable rendering. Extensive experiments show that SplaTAM achieves up to 2X state-of-the-art performance in camera pose estimation, map construction, and novel-view synthesis, demonstrating its superiority over existing approaches, while allowing real-time rendering of a high-resolution dense 3D map.
Differentiable Visual Computing for Inverse Problems and Machine Learning
Nov 21, 2023Originally designed for applications in computer graphics, visual computing (VC) methods synthesize information about physical and virtual worlds, using prescribed algorithms optimized for spatial computing. VC is used to analyze geometry, physically simulate solids, fluids, and other media, and render the world via optical techniques. These fine-tuned computations that operate explicitly on a given input solve so-called forward problems, VC excels at. By contrast, deep learning (DL) allows for the construction of general algorithmic models, side stepping the need for a purely first principles-based approach to problem solving. DL is powered by highly parameterized neural network architectures -- universal function approximators -- and gradient-based search algorithms which can efficiently search that large parameter space for optimal models. This approach is predicated by neural network differentiability, the requirement that analytic derivatives of a given problem's task metric can be computed with respect to neural network's parameters. Neural networks excel when an explicit model is not known, and neural network training solves an inverse problem in which a model is computed from data.
STAMP: Differentiable Task and Motion Planning via Stein Variational Gradient Descent
Oct 03, 2023



Planning for many manipulation tasks, such as using tools or assembling parts, often requires both symbolic and geometric reasoning. Task and Motion Planning (TAMP) algorithms typically solve these problems by conducting a tree search over high-level task sequences while checking for kinematic and dynamic feasibility. While performant, most existing algorithms are highly inefficient as their time complexity grows exponentially with the number of possible actions and objects. Additionally, they only find a single solution to problems in which many feasible plans may exist. To address these limitations, we propose a novel algorithm called Stein Task and Motion Planning (STAMP) that leverages parallelization and differentiable simulation to efficiently search for multiple diverse plans. STAMP relaxes discrete-and-continuous TAMP problems into continuous optimization problems that can be solved using variational inference. Our algorithm builds upon Stein Variational Gradient Descent, a gradient-based variational inference algorithm, and parallelized differentiable physics simulators on the GPU to efficiently obtain gradients for inference. Further, we employ imitation learning to introduce action abstractions that reduce the inference problem to lower dimensions. We demonstrate our method on two TAMP problems and empirically show that STAMP is able to: 1) produce multiple diverse plans in parallel; and 2) search for plans more efficiently compared to existing TAMP baselines.