 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeGo-Drive: Language-enhanced Goal-oriented Closed-Loop End-to-End Autonomous Driving
Mar 29, 2024



Existing Vision-Language models (VLMs) estimate either long-term trajectory waypoints or a set of control actions as a reactive solution for closed-loop planning based on their rich scene comprehension. However, these estimations are coarse and are subjective to their "world understanding" which may generate sub-optimal decisions due to perception errors. In this paper, we introduce LeGo-Drive, which aims to address this issue by estimating a goal location based on the given language command as an intermediate representation in an end-to-end setting. The estimated goal might fall in a non-desirable region, like on top of a car for a parking-like command, leading to inadequate planning. Hence, we propose to train the architecture in an end-to-end manner, resulting in iterative refinement of both the goal and the trajectory collectively. We validate the effectiveness of our method through comprehensive experiments conducted in diverse simulated environments. We report significant improvements in standard autonomous driving metrics, with a goal reaching Success Rate of 81%. We further showcase the versatility of LeGo-Drive across different driving scenarios and linguistic inputs, underscoring its potential for practical deployment in autonomous vehicles and intelligent transportation systems.
Talk2BEV: Language-enhanced Bird's-eye View Maps for Autonomous Driving
Oct 03, 2023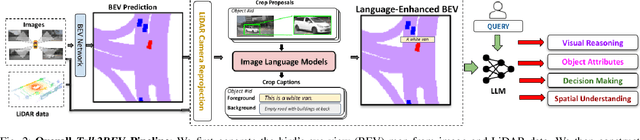
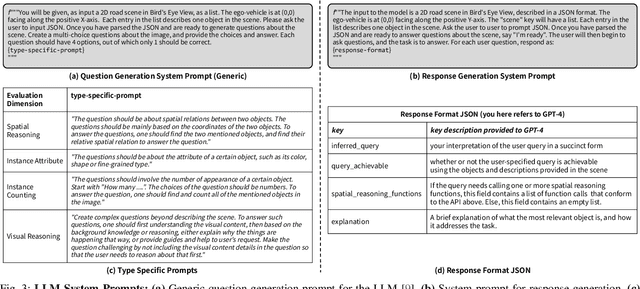

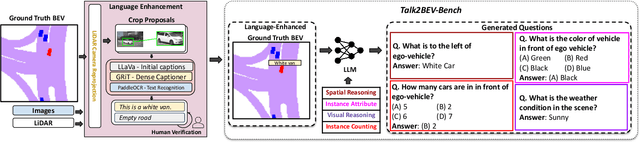
Talk2BEV is a large vision-language model (LVLM) interface for bird's-eye view (BEV) maps in autonomous driving contexts. While existing perception systems for autonomous driving scenarios have largely focused on a pre-defined (closed) set of object categories and driving scenarios, Talk2BEV blends recent advances in general-purpose language and vision models with BEV-structured map representations, eliminating the need for task-specific models. This enables a single system to cater to a variety of autonomous driving tasks encompassing visual and spatial reasoning, predicting the intents of traffic actors, and decision-making based on visual cues. We extensively evaluate Talk2BEV on a large number of scene understanding tasks that rely on both the ability to interpret free-form natural language queries, and in grounding these queries to the visual context embedded into the language-enhanced BEV map. To enable further research in LVLMs for autonomous driving scenarios, we develop and release Talk2BEV-Bench, a benchmark encompassing 1000 human-annotated BEV scenarios, with more than 20,000 questions and ground-truth responses from the NuScenes dataset.
UAP-BEV: Uncertainty Aware Planning using Bird's Eye View generated from Surround Monocular Images
Jun 08, 2023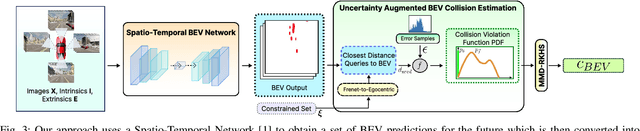

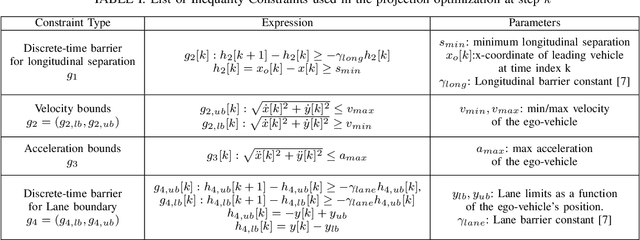
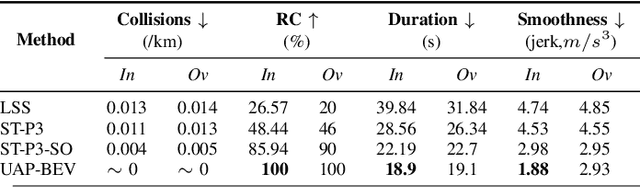
Autonomous driving requires accurate reasoning of the location of objects from raw sensor data. Recent end-to-end learning methods go from raw sensor data to a trajectory output via Bird's Eye View(BEV) segmentation as an interpretable intermediate representation. Motion planning over cost maps generated via Birds Eye View (BEV) segmentation has emerged as a prominent approach in autonomous driving. However, the current approaches have two critical gaps. First, the optimization process is simplistic and involves just evaluating a fixed set of trajectories over the cost map. The trajectory samples are not adapted based on their associated cost values. Second, the existing cost maps do not account for the uncertainty in the cost maps that can arise due to noise in RGB images, and BEV annotations. As a result, these approaches can struggle in challenging scenarios where there is abrupt cut-in, stopping, overtaking, merging, etc from the neighboring vehicles. In this paper, we propose UAP-BEV: A novel approach that models the noise in Spatio-Temporal BEV predictions to create an uncertainty-aware occupancy grid map. Using queries of the distance to the closest occupied cell, we obtain a sample estimate of the collision probability of the ego-vehicle. Subsequently, our approach uses gradient-free sampling-based optimization to compute low-cost trajectories over the cost map. Importantly, the sampling distribution is adapted based on the optimal cost values of the sampled trajectories. By explicitly modeling probabilistic collision avoidance in the BEV space, our approach is able to outperform the cost-map-based baselines in collision avoidance, route completion, time to completion, and smoothness. To further validate our method, we also show results on the real-world dataset NuScenes, where we report improvements in collision avoidance and smoothness.
Deconvolution and Restoration of Optical Endomicroscopy Images
Aug 28, 2018
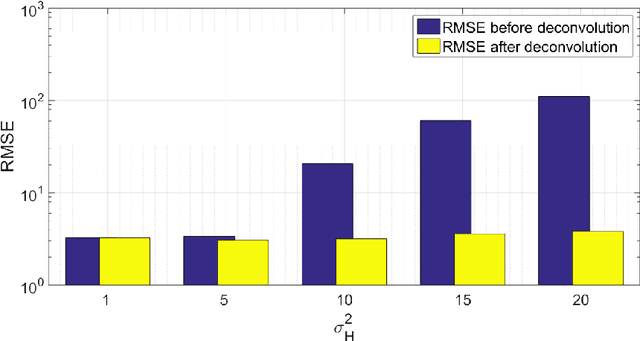
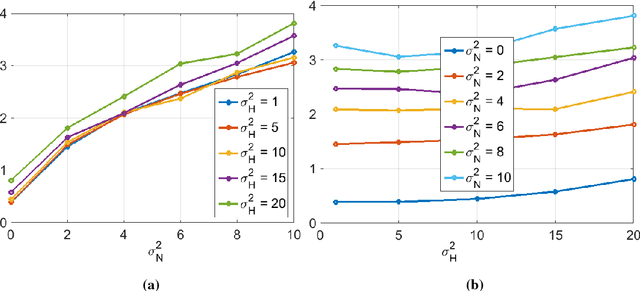
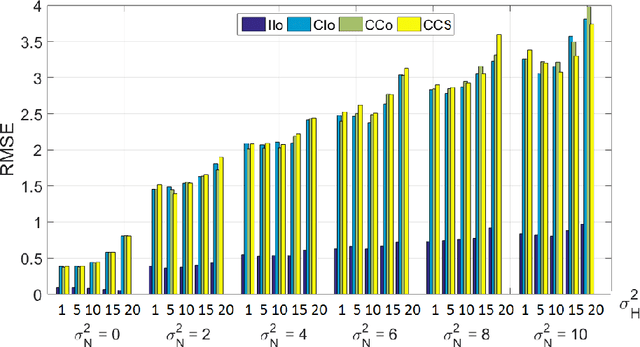
Optical endomicroscopy (OEM) is an emerging technology platform with preclinical and clinical imaging applications. Pulmonary OEM via fibre bundles has the potential to provide in vivo, in situ molecular signatures of disease such as infection and inflammation. However, enhancing the quality of data acquired by this technique for better visualization and subsequent analysis remains a challenging problem. Cross coupling between fiber cores and sparse sampling by imaging fiber bundles are the main reasons for image degradation, and poor detection performance (i.e., inflammation, bacteria, etc.). In this work, we address the problem of deconvolution and restoration of OEM data. We propose a hierarchical Bayesian model to solve this problem and compare three estimation algorithms to exploit the resulting joint posterior distribution. The first method is based on Markov chain Monte Carlo (MCMC) methods, however, it exhibits a relatively long computational time. The second and third algorithms deal with this issue and are based on a variational Bayes (VB) approach and an alternating direction method of multipliers (ADMM) algorithm respectively. Results on both synthetic and real datasets illustrate the effectiveness of the proposed methods for restoration of OEM images.