 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagine-2-Drive: High-Fidelity World Modeling in CARLA for Autonomous Vehicles
Nov 15, 2024
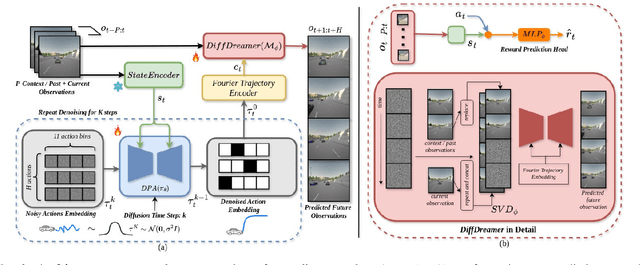
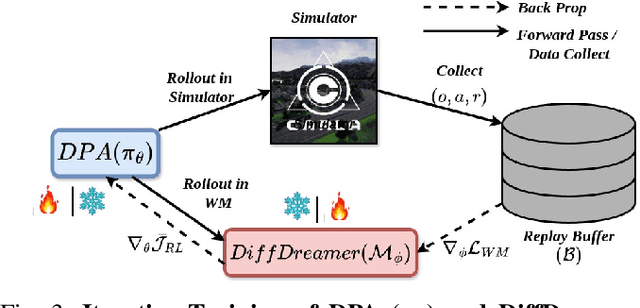
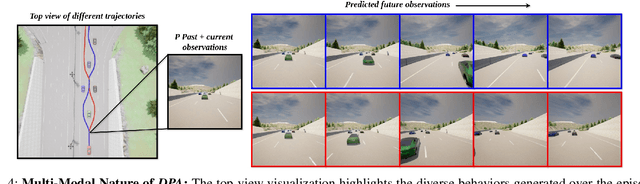
In autonomous driving with image based state space, accurate prediction of future events and modeling diverse behavioral modes are essential for safety and effective decision-making. World model-based Reinforcement Learning (WMRL) approaches offers a promising solution by simulating future states from current state and actions. However, utility of world models is often limited by typical RL policies being limited to deterministic or single gaussian distribution. By failing to capture the full spectrum of possible actions, reduces their adaptability in complex, dynamic environments. In this work, we introduce Imagine-2-Drive, a framework that consists of two components, VISTAPlan, a high-fidelity world model for accurate future prediction and Diffusion Policy Actor (DPA), a diffusion based policy to model multi-modal behaviors for trajectory prediction. We use VISTAPlan to simulate and evaluate trajectories from DPA and use Denoising Diffusion Policy Optimization (DDPO) to train DPA to maximize the cumulative sum of rewards over the trajectories. We analyze the benefits of each component and the framework as a whole in CARLA with standard driving metrics. As a consequence of our twin novelties- VISTAPlan and DPA, we significantly outperform the state of the art (SOTA) world models on standard driving metrics by 15% and 20% on Route Completion and Success Rate respectively.
LeGo-Drive: Language-enhanced Goal-oriented Closed-Loop End-to-End Autonomous Driving
Mar 29, 2024



Existing Vision-Language models (VLMs) estimate either long-term trajectory waypoints or a set of control actions as a reactive solution for closed-loop planning based on their rich scene comprehension. However, these estimations are coarse and are subjective to their "world understanding" which may generate sub-optimal decisions due to perception errors. In this paper, we introduce LeGo-Drive, which aims to address this issue by estimating a goal location based on the given language command as an intermediate representation in an end-to-end setting. The estimated goal might fall in a non-desirable region, like on top of a car for a parking-like command, leading to inadequate planning. Hence, we propose to train the architecture in an end-to-end manner, resulting in iterative refinement of both the goal and the trajectory collectively. We validate the effectiveness of our method through comprehensive experiments conducted in diverse simulated environments. We report significant improvements in standard autonomous driving metrics, with a goal reaching Success Rate of 81%. We further showcase the versatility of LeGo-Drive across different driving scenarios and linguistic inputs, underscoring its potential for practical deployment in autonomous vehicles and intelligent transportation systems.