 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagine-2-Drive: High-Fidelity World Modeling in CARLA for Autonomous Vehicles
Paper and Code
Nov 15, 2024
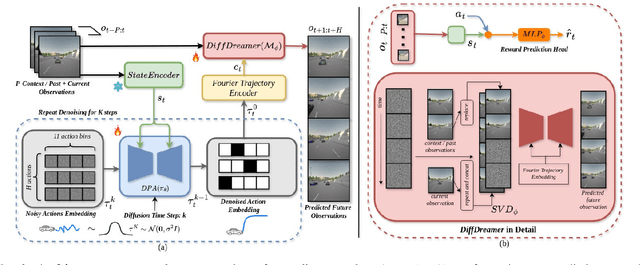
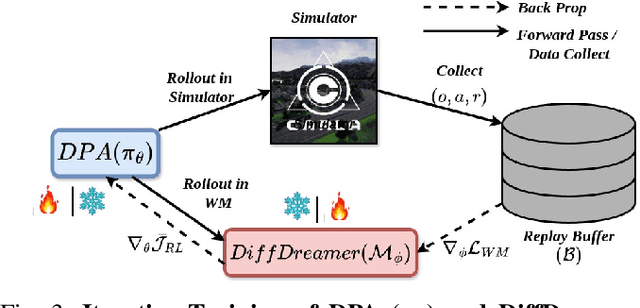
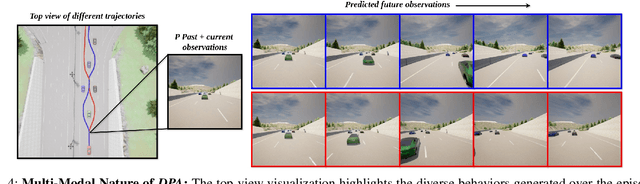
In autonomous driving with image based state space, accurate prediction of future events and modeling diverse behavioral modes are essential for safety and effective decision-making. World model-based Reinforcement Learning (WMRL) approaches offers a promising solution by simulating future states from current state and actions. However, utility of world models is often limited by typical RL policies being limited to deterministic or single gaussian distribution. By failing to capture the full spectrum of possible actions, reduces their adaptability in complex, dynamic environments. In this work, we introduce Imagine-2-Drive, a framework that consists of two components, VISTAPlan, a high-fidelity world model for accurate future prediction and Diffusion Policy Actor (DPA), a diffusion based policy to model multi-modal behaviors for trajectory prediction. We use VISTAPlan to simulate and evaluate trajectories from DPA and use Denoising Diffusion Policy Optimization (DDPO) to train DPA to maximize the cumulative sum of rewards over the trajectories. We analyze the benefits of each component and the framework as a whole in CARLA with standard driving metrics. As a consequence of our twin novelties- VISTAPlan and DPA, we significantly outperform the state of the art (SOTA) world models on standard driving metrics by 15% and 20% on Route Completion and Success Rate respectively.