 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Cycle-Consistent Anchor Points for Self-Supervised RGB-D Registration
Oct 16, 2025With the rise in consumer depth cameras, a wealth of unlabeled RGB-D data has become available. This prompts the question of how to utilize this data for geometric reasoning of scenes. While many RGB-D registration meth- ods rely on geometric and feature-based similarity, we take a different approach. We use cycle-consistent keypoints as salient points to enforce spatial coherence constraints during matching, improving correspondence accuracy. Additionally, we introduce a novel pose block that combines a GRU recurrent unit with transformation synchronization, blending historical and multi-view data. Our approach surpasses previous self- supervised registration methods on ScanNet and 3DMatch, even outperforming some older supervised methods. We also integrate our components into existing methods, showing their effectiveness.
* 8 pages, accepted at ICRA 2024 (International Conference on Robotics and Automation)
DG16M: A Large-Scale Dataset for Dual-Arm Grasping with Force-Optimized Grasps
Mar 11, 2025

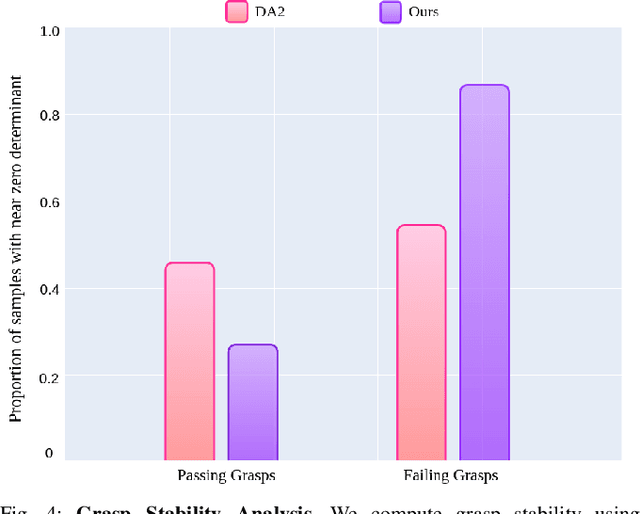

Dual-arm robotic grasping is crucial for handling large objects that require stable and coordinated manipulation. While single-arm grasping has been extensively studied, datasets tailored for dual-arm settings remain scarce. We introduce a large-scale dataset of 16 million dual-arm grasps, evaluated under improved force-closure constraints. Additionally, we develop a benchmark dataset containing 300 objects with approximately 30,000 grasps, evaluated in a physics simulation environment, providing a better grasp quality assessment for dual-arm grasp synthesis methods. Finally, we demonstrate the effectiveness of our dataset by training a Dual-Arm Grasp Classifier network that outperforms the state-of-the-art methods by 15\%, achieving higher grasp success rates and improved generalization across objects.
MetricGold: Leveraging Text-To-Image Latent Diffusion Models for Metric Depth Estimation
Nov 16, 2024
Recovering metric depth from a single image remains a fundamental challenge in computer vision, requiring both scene understanding and accurate scaling. While deep learning has advanced monocular depth estimation, current models often struggle with unfamiliar scenes and layouts, particularly in zero-shot scenarios and when predicting scale-ergodic metric depth. We present MetricGold, a novel approach that harnesses generative diffusion model's rich priors to improve metric depth estimation. Building upon recent advances in MariGold, DDVM and Depth Anything V2 respectively, our method combines latent diffusion, log-scaled metric depth representation, and synthetic data training. MetricGold achieves efficient training on a single RTX 3090 within two days using photo-realistic synthetic data from HyperSIM, VirtualKitti, and TartanAir. Our experiments demonstrate robust generalization across diverse datasets, producing sharper and higher quality metric depth estimates compared to existing approaches.
Imagine-2-Drive: High-Fidelity World Modeling in CARLA for Autonomous Vehicles
Nov 15, 2024
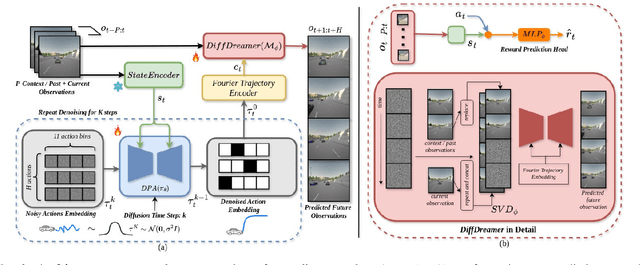
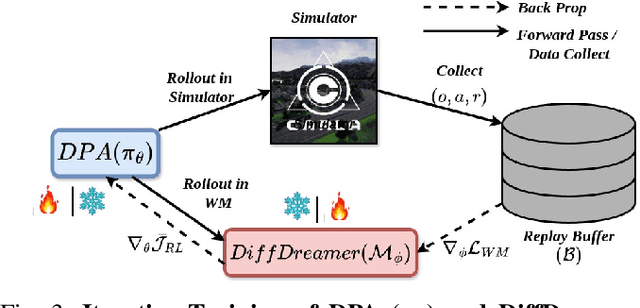
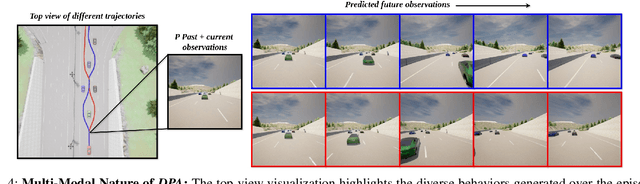
In autonomous driving with image based state space, accurate prediction of future events and modeling diverse behavioral modes are essential for safety and effective decision-making. World model-based Reinforcement Learning (WMRL) approaches offers a promising solution by simulating future states from current state and actions. However, utility of world models is often limited by typical RL policies being limited to deterministic or single gaussian distribution. By failing to capture the full spectrum of possible actions, reduces their adaptability in complex, dynamic environments. In this work, we introduce Imagine-2-Drive, a framework that consists of two components, VISTAPlan, a high-fidelity world model for accurate future prediction and Diffusion Policy Actor (DPA), a diffusion based policy to model multi-modal behaviors for trajectory prediction. We use VISTAPlan to simulate and evaluate trajectories from DPA and use Denoising Diffusion Policy Optimization (DDPO) to train DPA to maximize the cumulative sum of rewards over the trajectories. We analyze the benefits of each component and the framework as a whole in CARLA with standard driving metrics. As a consequence of our twin novelties- VISTAPlan and DPA, we significantly outperform the state of the art (SOTA) world models on standard driving metrics by 15% and 20% on Route Completion and Success Rate respectively.
DA-VIL: Adaptive Dual-Arm Manipulation with Reinforcement Learning and Variable Impedance Control
Oct 25, 2024



Dual-arm manipulation is an area of growing interest in the robotics community. Enabling robots to perform tasks that require the coordinated use of two arms, is essential for complex manipulation tasks such as handling large objects, assembling components, and performing human-like interactions. However, achieving effective dual-arm manipulation is challenging due to the need for precise coordination, dynamic adaptability, and the ability to manage interaction forces between the arms and the objects being manipulated. We propose a novel pipeline that combines the advantages of policy learning based on environment feedback and gradient-based optimization to learn controller gains required for the control outputs. This allows the robotic system to dynamically modulate its impedance in response to task demands, ensuring stability and dexterity in dual-arm operations. We evaluate our pipeline on a trajectory-tracking task involving a variety of large, complex objects with different masses and geometries. The performance is then compared to three other established methods for controlling dual-arm robots, demonstrating superior results.
Towards Global Localization using Multi-Modal Object-Instance Re-Identification
Sep 18, 2024Re-identification (ReID) is a critical challenge in computer vision, predominantly studied in the context of pedestrians and vehicles. However, robust object-instance ReID, which has significant implications for tasks such as autonomous exploration, long-term perception, and scene understanding, remains underexplored. In this work, we address this gap by proposing a novel dual-path object-instance re-identification transformer architecture that integrates multimodal RGB and depth information. By leveraging depth data, we demonstrate improvements in ReID across scenes that are cluttered or have varying illumination conditions. Additionally, we develop a ReID-based localization framework that enables accurate camera localization and pose identification across different viewpoints. We validate our methods using two custom-built RGB-D datasets, as well as multiple sequences from the open-source TUM RGB-D datasets. Our approach demonstrates significant improvements in both object instance ReID (mAP of 75.18) and localization accuracy (success rate of 83% on TUM-RGBD), highlighting the essential role of object ReID in advancing robotic perception. Our models, frameworks, and datasets have been made publicly available.
Constrained 6-DoF Grasp Generation on Complex Shapes for Improved Dual-Arm Manipulation
Apr 06, 2024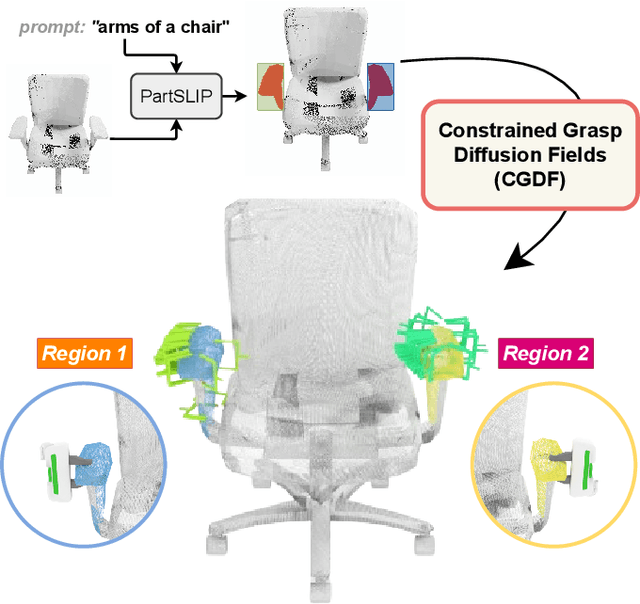
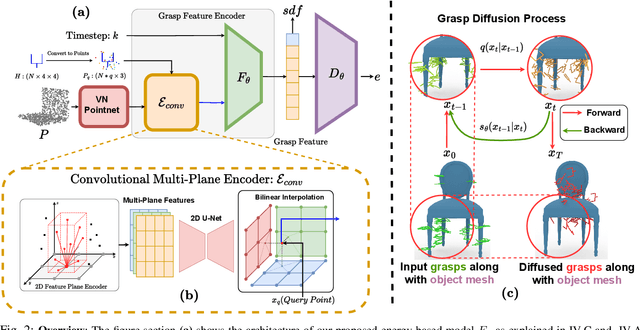
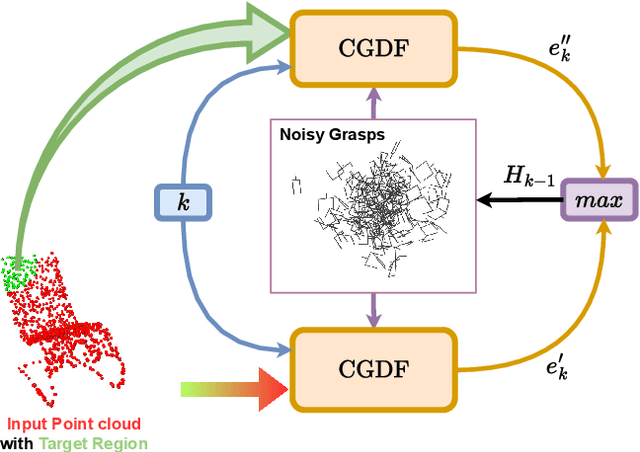
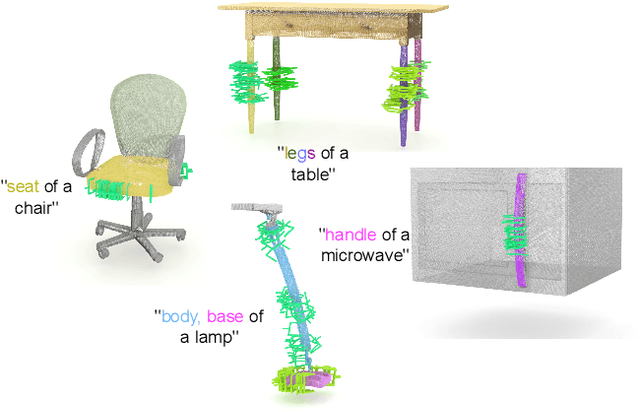
Efficiently generating grasp poses tailored to specific regions of an object is vital for various robotic manipulation tasks, especially in a dual-arm setup. This scenario presents a significant challenge due to the complex geometries involved, requiring a deep understanding of the local geometry to generate grasps efficiently on the specified constrained regions. Existing methods only explore settings involving table-top/small objects and require augmented datasets to train, limiting their performance on complex objects. We propose CGDF: Constrained Grasp Diffusion Fields, a diffusion-based grasp generative model that generalizes to objects with arbitrary geometries, as well as generates dense grasps on the target regions. CGDF uses a part-guided diffusion approach that enables it to get high sample efficiency in constrained grasping without explicitly training on massive constraint-augmented datasets. We provide qualitative and quantitative comparisons using analytical metrics and in simulation, in both unconstrained and constrained settings to show that our method can generalize to generate stable grasps on complex objects, especially useful for dual-arm manipulation settings, while existing methods struggle to do so.
DiffPrompter: Differentiable Implicit Visual Prompts for Semantic-Segmentation in Adverse Conditions
Oct 06, 2023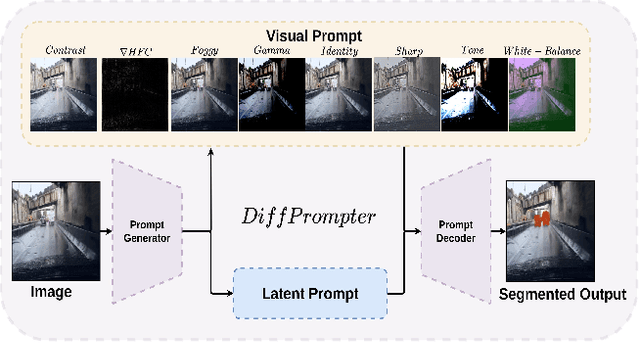



Semantic segmentation in adverse weather scenarios is a critical task for autonomous driving systems. While foundation models have shown promise, the need for specialized adaptors becomes evident for handling more challenging scenarios. We introduce DiffPrompter, a novel differentiable visual and latent prompting mechanism aimed at expanding the learning capabilities of existing adaptors in foundation models. Our proposed $\nabla$HFC image processing block excels particularly in adverse weather conditions, where conventional methods often fall short. Furthermore, we investigate the advantages of jointly training visual and latent prompts, demonstrating that this combined approach significantly enhances performance in out-of-distribution scenarios. Our differentiable visual prompts leverage parallel and series architectures to generate prompts, effectively improving object segmentation tasks in adverse conditions. Through a comprehensive series of experiments and evaluations, we provide empirical evidence to support the efficacy of our approach. Project page at https://diffprompter.github.io.
HyP-NeRF: Learning Improved NeRF Priors using a HyperNetwork
Jun 09, 2023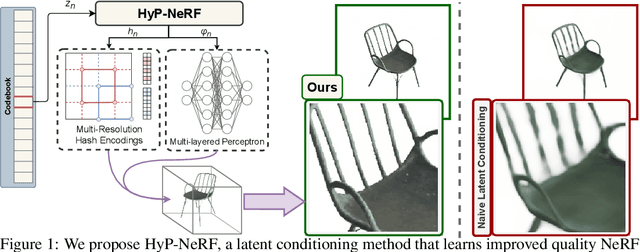

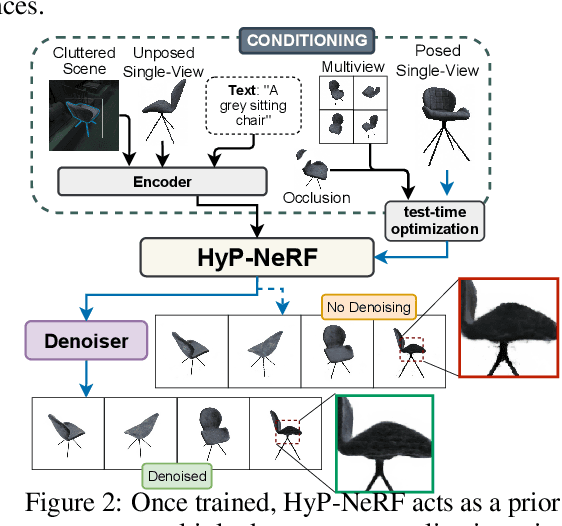

Neural Radiance Fields (NeRF) have become an increasingly popular representation to capture high-quality appearance and shape of scenes and objects. However, learning generalizable NeRF priors over categories of scenes or objects has been challenging due to the high dimensionality of network weight space. To address the limitations of existing work on generalization, multi-view consistency and to improve quality, we propose HyP-NeRF, a latent conditioning method for learning generalizable category-level NeRF priors using hypernetworks. Rather than using hypernetworks to estimate only the weights of a NeRF, we estimate both the weights and the multi-resolution hash encodings resulting in significant quality gains. To improve quality even further, we incorporate a denoise and finetune strategy that denoises images rendered from NeRFs estimated by the hypernetwork and finetunes it while retaining multiview consistency. These improvements enable us to use HyP-NeRF as a generalizable prior for multiple downstream tasks including NeRF reconstruction from single-view or cluttered scenes and text-to-NeRF. We provide qualitative comparisons and evaluate HyP-NeRF on three tasks: generalization, compression, and retrieval, demonstrating our state-of-the-art results.
GDIP: Gated Differentiable Image Processing for Object-Detection in Adverse Conditions
Sep 29, 2022
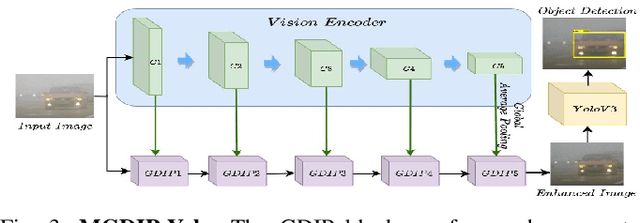
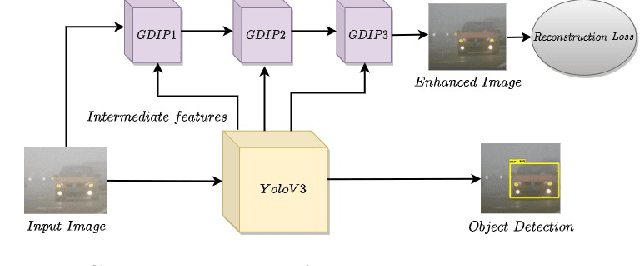
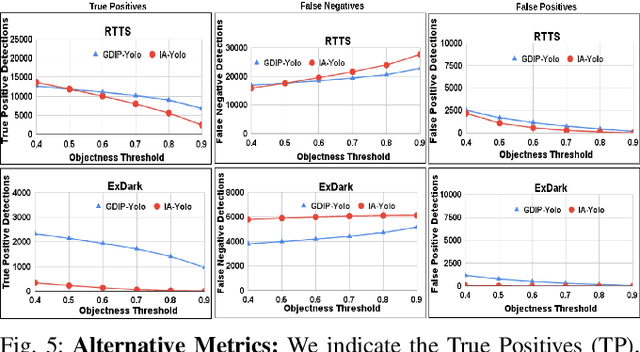
Detecting objects under adverse weather and lighting conditions is crucial for the safe and continuous operation of an autonomous vehicle, and remains an unsolved problem. We present a Gated Differentiable Image Processing (GDIP) block, a domain-agnostic network architecture, which can be plugged into existing object detection networks (e.g., Yolo) and trained end-to-end with adverse condition images such as those captured under fog and low lighting. Our proposed GDIP block learns to enhance images directly through the downstream object detection loss. This is achieved by learning parameters of multiple image pre-processing (IP) techniques that operate concurrently, with their outputs combined using weights learned through a novel gating mechanism. We further improve GDIP through a multi-stage guidance procedure for progressive image enhancement. Finally, trading off accuracy for speed, we propose a variant of GDIP that can be used as a regularizer for training Yolo, which eliminates the need for GDIP-based image enhancement during inference, resulting in higher throughput and plausible real-world deployment. We demonstrate significant improvement in detection performance over several state-of-the-art methods through quantitative and qualitative studies on synthetic datasets such as PascalVOC, and real-world foggy (RTTS) and low-lighting (ExDark) datasets.