 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Sensitive Abstractions for Reinforcement Learning with Parameterized Actions
Dec 23, 2025Real-world sequential decision-making often involves parameterized action spaces that require both, decisions regarding discrete actions and decisions about continuous action parameters governing how an action is executed. Existing approaches exhibit severe limitations in this setting -- planning methods demand hand-crafted action models, and standard reinforcement learning (RL) algorithms are designed for either discrete or continuous actions but not both, and the few RL methods that handle parameterized actions typically rely on domain-specific engineering and fail to exploit the latent structure of these spaces. This paper extends the scope of RL algorithms to long-horizon, sparse-reward settings with parameterized actions by enabling agents to autonomously learn both state and action abstractions online. We introduce algorithms that progressively refine these abstractions during learning, increasing fine-grained detail in the critical regions of the state-action space where greater resolution improves performance. Across several continuous-state, parameterized-action domains, our abstraction-driven approach enables TD($λ$) to achieve markedly higher sample efficiency than state-of-the-art baselines.
Discovering and Learning Probabilistic Models of Black-Box AI Capabilities
Dec 20, 2025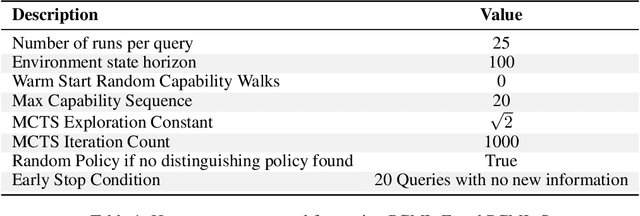
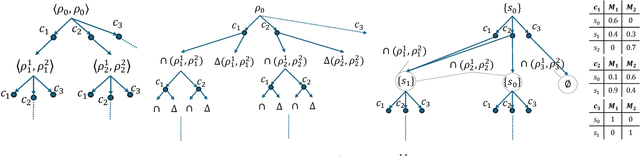
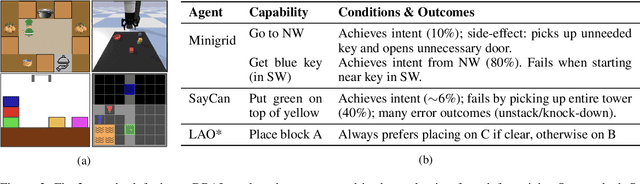
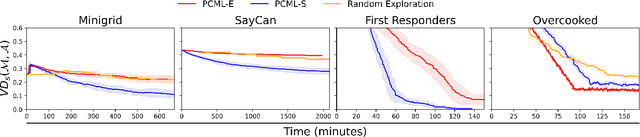
Black-box AI (BBAI) systems such as foundational models are increasingly being used for sequential decision making. To ensure that such systems are safe to operate and deploy, it is imperative to develop efficient methods that can provide a sound and interpretable representation of the BBAI's capabilities. This paper shows that PDDL-style representations can be used to efficiently learn and model an input BBAI's planning capabilities. It uses the Monte-Carlo tree search paradigm to systematically create test tasks, acquire data, and prune the hypothesis space of possible symbolic models. Learned models describe a BBAI's capabilities, the conditions under which they can be executed, and the possible outcomes of executing them along with their associated probabilities. Theoretical results show soundness, completeness and convergence of the learned models. Empirical results with multiple BBAI systems illustrate the scope, efficiency, and accuracy of the presented methods.
Styleclone: Face Stylization with Diffusion Based Data Augmentation
Aug 23, 2025We present StyleClone, a method for training image-to-image translation networks to stylize faces in a specific style, even with limited style images. Our approach leverages textual inversion and diffusion-based guided image generation to augment small style datasets. By systematically generating diverse style samples guided by both the original style images and real face images, we significantly enhance the diversity of the style dataset. Using this augmented dataset, we train fast image-to-image translation networks that outperform diffusion-based methods in speed and quality. Experiments on multiple styles demonstrate that our method improves stylization quality, better preserves source image content, and significantly accelerates inference. Additionally, we provide a systematic evaluation of the augmentation techniques and their impact on stylization performance.
RephraseTTS: Dynamic Length Text based Speech Insertion with Speaker Style Transfer
Aug 23, 2025



We propose a method for the task of text-conditioned speech insertion, i.e. inserting a speech sample in an input speech sample, conditioned on the corresponding complete text transcript. An example use case of the task would be to update the speech audio when corrections are done on the corresponding text transcript. The proposed method follows a transformer-based non-autoregressive approach that allows speech insertions of variable lengths, which are dynamically determined during inference, based on the text transcript and tempo of the available partial input. It is capable of maintaining the speaker's voice characteristics, prosody and other spectral properties of the available speech input. Results from our experiments and user study on LibriTTS show that our method outperforms baselines based on an existing adaptive text to speech method. We also provide numerous qualitative results to appreciate the quality of the output from the proposed method.
Autonomous Option Invention for Continual Hierarchical Reinforcement Learning and Planning
Dec 20, 2024Abstraction is key to scaling up reinforcement learning (RL). However, autonomously learning abstract state and action representations to enable transfer and generalization remains a challenging open problem. This paper presents a novel approach for inventing, representing, and utilizing options, which represent temporally extended behaviors, in continual RL settings. Our approach addresses streams of stochastic problems characterized by long horizons, sparse rewards, and unknown transition and reward functions. Our approach continually learns and maintains an interpretable state abstraction, and uses it to invent high-level options with abstract symbolic representations. These options meet three key desiderata: (1) composability for solving tasks effectively with lookahead planning, (2) reusability across problem instances for minimizing the need for relearning, and (3) mutual independence for reducing interference among options. Our main contributions are approaches for continually learning transferable, generalizable options with symbolic representations, and for integrating search techniques with RL to efficiently plan over these learned options to solve new problems. Empirical results demonstrate that the resulting approach effectively learns and transfers abstract knowledge across problem instances, achieving superior sample efficiency compared to state-of-the-art methods.
AI Planning: A Primer and Survey (Preliminary Report)
Dec 07, 2024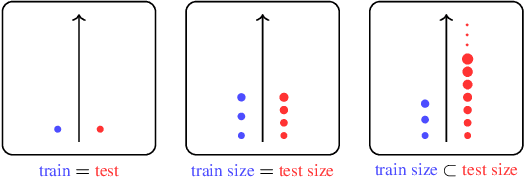
Automated decision-making is a fundamental topic that spans multiple sub-disciplines in AI: reinforcement learning (RL), AI planning (AP), foundation models, and operations research, among others. Despite recent efforts to ``bridge the gaps'' between these communities, there remain many insights that have not yet transcended the boundaries. Our goal in this paper is to provide a brief and non-exhaustive primer on ideas well-known in AP, but less so in other sub-disciplines. We do so by introducing the classical AP problem and representation, and extensions that handle uncertainty and time through the Markov Decision Process formalism. Next, we survey state-of-the-art techniques and ideas for solving AP problems, focusing on their ability to exploit problem structure. Lastly, we cover subfields within AP for learning structure from unstructured inputs and learning to generalise to unseen scenarios and situations.
$\forall$uto$\exists$$\lor\!\land$L: Autonomous Evaluation of LLMs for Truth Maintenance and Reasoning Tasks
Oct 11, 2024



This paper presents $\forall$uto$\exists$$\lor\!\land$L, a novel benchmark for scaling Large Language Model (LLM) assessment in formal tasks with clear notions of correctness, such as truth maintenance in translation and logical reasoning. $\forall$uto$\exists$$\lor\!\land$L is the first benchmarking paradigm that offers several key advantages necessary for scaling objective evaluation of LLMs without human labeling: (a) ability to evaluate LLMs of increasing sophistication by auto-generating tasks at different levels of difficulty; (b) auto-generation of ground truth that eliminates dependence on expensive and time-consuming human annotation; (c) the use of automatically generated, randomized datasets that mitigate the ability of successive LLMs to overfit to static datasets used in many contemporary benchmarks. Empirical analysis shows that an LLM's performance on $\forall$uto$\exists$$\lor\!\land$L is highly indicative of its performance on a diverse array of other benchmarks focusing on translation and reasoning tasks, making it a valuable autonomous evaluation paradigm in settings where hand-curated datasets can be hard to obtain and/or update.
Towards Global Localization using Multi-Modal Object-Instance Re-Identification
Sep 18, 2024Re-identification (ReID) is a critical challenge in computer vision, predominantly studied in the context of pedestrians and vehicles. However, robust object-instance ReID, which has significant implications for tasks such as autonomous exploration, long-term perception, and scene understanding, remains underexplored. In this work, we address this gap by proposing a novel dual-path object-instance re-identification transformer architecture that integrates multimodal RGB and depth information. By leveraging depth data, we demonstrate improvements in ReID across scenes that are cluttered or have varying illumination conditions. Additionally, we develop a ReID-based localization framework that enables accurate camera localization and pose identification across different viewpoints. We validate our methods using two custom-built RGB-D datasets, as well as multiple sequences from the open-source TUM RGB-D datasets. Our approach demonstrates significant improvements in both object instance ReID (mAP of 75.18) and localization accuracy (success rate of 83% on TUM-RGBD), highlighting the essential role of object ReID in advancing robotic perception. Our models, frameworks, and datasets have been made publicly available.
Belief-State Query Policies for Planning With Preferences Under Partial Observability
May 24, 2024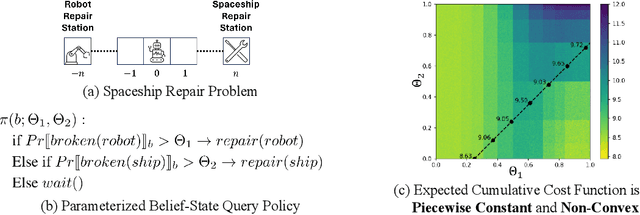
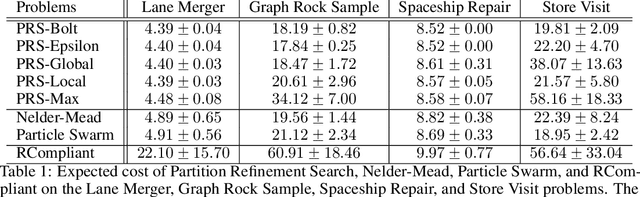
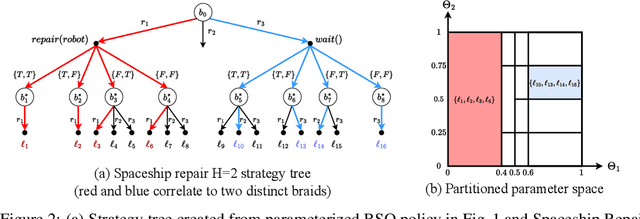
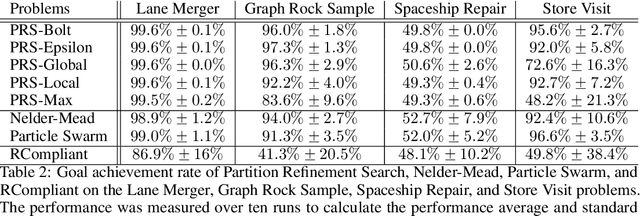
Planning in real-world settings often entails addressing partial observability while aligning with users' preferences. We present a novel framework for expressing users' preferences about agent behavior in a partially observable setting using parameterized belief-state query (BSQ) preferences in the setting of goal-oriented partially observable Markov decision processes (gPOMDPs). We present the first formal analysis of such preferences and prove that while the expected value of a BSQ preference is not a convex function w.r.t its parameters, it is piecewise constant and yields an implicit discrete parameter search space that is finite for finite horizons. This theoretical result leads to novel algorithms that optimize gPOMDP agent behavior while guaranteeing user preference compliance. Theoretical analysis proves that our algorithms converge to the optimal preference-compliant behavior in the limit. Empirical results show that BSQ preferences provide a computationally feasible approach for planning with preferences in partially observable settings.
Using Explainable AI and Hierarchical Planning for Outreach with Robots
Mar 31, 2024

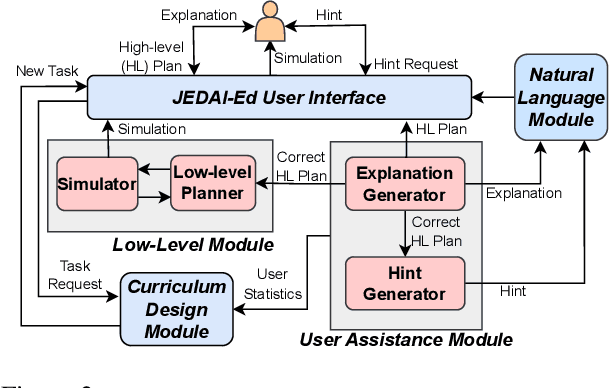

Understanding how robots plan and execute tasks is crucial in today's world, where they are becoming more prevalent in our daily lives. However, teaching non-experts the complexities of robot planning can be challenging. This work presents an open-source platform that simplifies the process using a visual interface that completely abstracts the complex internals of hierarchical planning that robots use for performing task and motion planning. Using the principles developed in the field of explainable AI, this intuitive platform enables users to create plans for robots to complete tasks, and provides helpful hints and natural language explanations for errors. The platform also has a built-in simulator to demonstrate how robots execute submitted plans. This platform's efficacy was tested in a user study on university students with little to no computer science background. Our results show that this platform is highly effective in teaching novice users the intuitions of robot task planning.