 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering and Learning Probabilistic Models of Black-Box AI Capabilities
Dec 20, 2025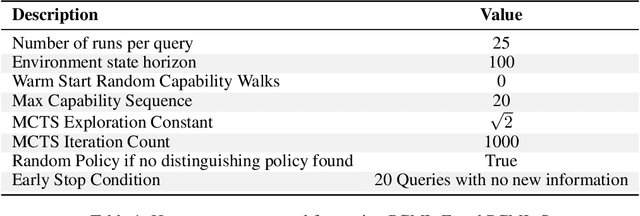
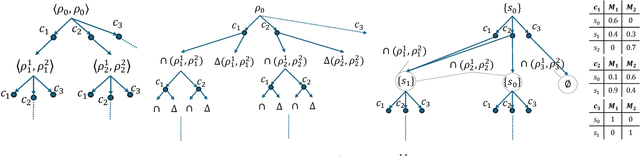
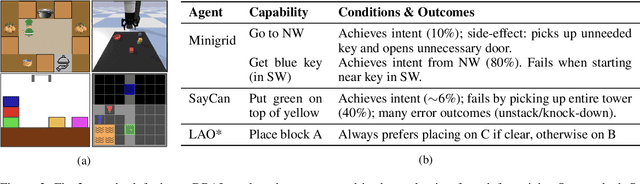
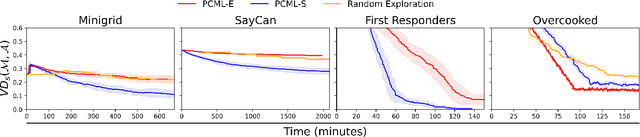
Black-box AI (BBAI) systems such as foundational models are increasingly being used for sequential decision making. To ensure that such systems are safe to operate and deploy, it is imperative to develop efficient methods that can provide a sound and interpretable representation of the BBAI's capabilities. This paper shows that PDDL-style representations can be used to efficiently learn and model an input BBAI's planning capabilities. It uses the Monte-Carlo tree search paradigm to systematically create test tasks, acquire data, and prune the hypothesis space of possible symbolic models. Learned models describe a BBAI's capabilities, the conditions under which they can be executed, and the possible outcomes of executing them along with their associated probabilities. Theoretical results show soundness, completeness and convergence of the learned models. Empirical results with multiple BBAI systems illustrate the scope, efficiency, and accuracy of the presented methods.
AI Planning: A Primer and Survey (Preliminary Report)
Dec 07, 2024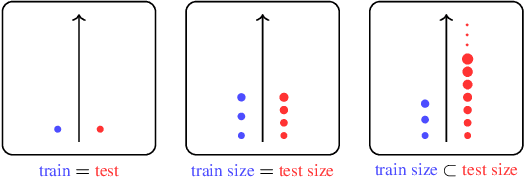
Automated decision-making is a fundamental topic that spans multiple sub-disciplines in AI: reinforcement learning (RL), AI planning (AP), foundation models, and operations research, among others. Despite recent efforts to ``bridge the gaps'' between these communities, there remain many insights that have not yet transcended the boundaries. Our goal in this paper is to provide a brief and non-exhaustive primer on ideas well-known in AP, but less so in other sub-disciplines. We do so by introducing the classical AP problem and representation, and extensions that handle uncertainty and time through the Markov Decision Process formalism. Next, we survey state-of-the-art techniques and ideas for solving AP problems, focusing on their ability to exploit problem structure. Lastly, we cover subfields within AP for learning structure from unstructured inputs and learning to generalise to unseen scenarios and situations.
Using Explainable AI and Hierarchical Planning for Outreach with Robots
Mar 31, 2024

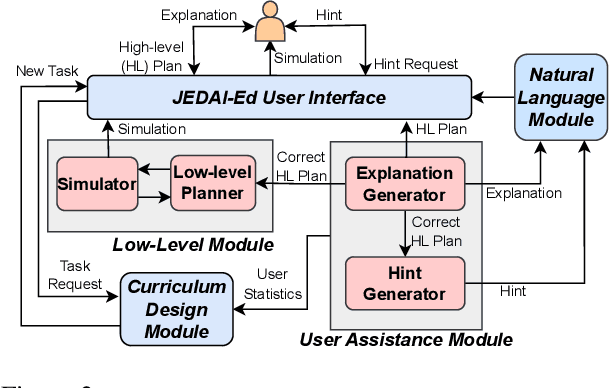

Understanding how robots plan and execute tasks is crucial in today's world, where they are becoming more prevalent in our daily lives. However, teaching non-experts the complexities of robot planning can be challenging. This work presents an open-source platform that simplifies the process using a visual interface that completely abstracts the complex internals of hierarchical planning that robots use for performing task and motion planning. Using the principles developed in the field of explainable AI, this intuitive platform enables users to create plans for robots to complete tasks, and provides helpful hints and natural language explanations for errors. The platform also has a built-in simulator to demonstrate how robots execute submitted plans. This platform's efficacy was tested in a user study on university students with little to no computer science background. Our results show that this platform is highly effective in teaching novice users the intuitions of robot task planning.
Can LLMs Converse Formally? Automatically Assessing LLMs in Translating and Interpreting Formal Specifications
Mar 27, 2024

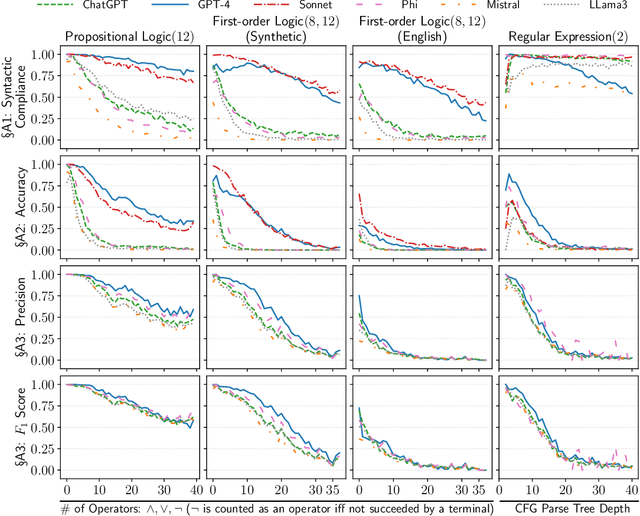
Stakeholders often describe system requirements using natural language which are then converted to formal syntax by a domain-expert leading to increased design costs. This paper assesses the capabilities of Large Language Models (LLMs) in converting between natural language descriptions and formal specifications. Existing work has evaluated the capabilities of LLMs in generating formal syntax such as source code but such experiments are typically hand-crafted and use problems that are likely to be in the training set of LLMs, and often require human-annotated datasets. We propose an approach that can use two copies of an LLM in conjunction with an off-the-shelf verifier to automatically evaluate its translation abilities without any additional human input. Our approach generates formal syntax using language grammars to automatically generate a dataset. We conduct an empirical evaluation to measure the accuracy of this translation task and show that SOTA LLMs cannot adequately solve this task, limiting their current utility in the design of complex systems.
From Reals to Logic and Back: Inventing Symbolic Vocabularies, Actions, and Models for Planning from Raw Data
Feb 23, 2024



Hand-crafted, logic-based state and action representations have been widely used to overcome the intractable computational complexity of long-horizon robot planning problems, including task and motion planning problems. However, creating such representations requires experts with strong intuitions and detailed knowledge about the robot and the tasks it may need to accomplish in a given setting. Removing this dependency on human intuition is a highly active research area. This paper presents the first approach for autonomously learning generalizable, logic-based relational representations for abstract states and actions starting from unannotated high-dimensional, real-valued robot trajectories. The learned representations constitute auto-invented PDDL-like domain models. Empirical results in deterministic settings show that powerful abstract representations can be learned from just a handful of robot trajectories; the learned relational representations include but go beyond classical, intuitive notions of high-level actions; and that the learned models allow planning algorithms to scale to tasks that were previously beyond the scope of planning without hand-crafted abstractions.
Epistemic Exploration for Generalizable Planning and Learning in Non-Stationary Settings
Feb 13, 2024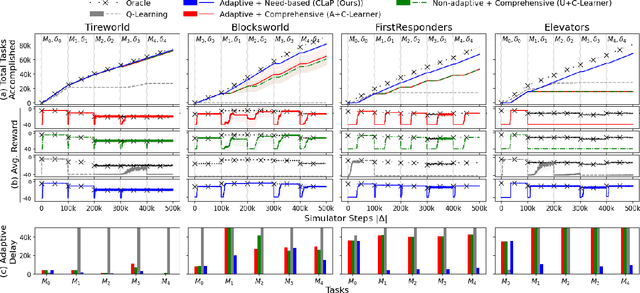
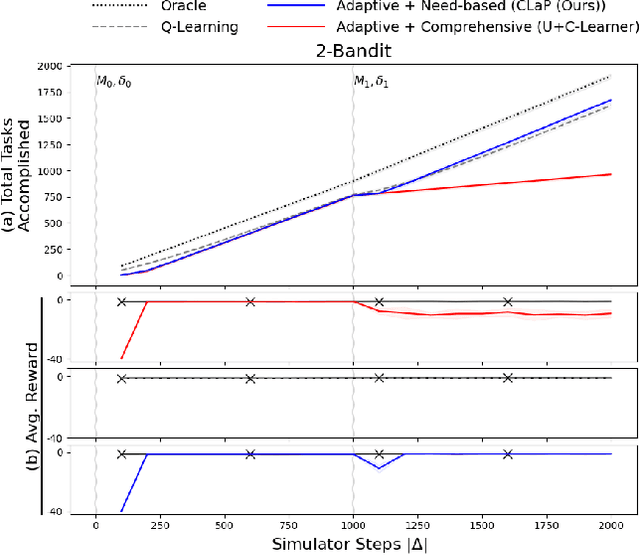
This paper introduces a new approach for continual planning and model learning in non-stationary stochastic environments expressed using relational representations. Such capabilities are essential for the deployment of sequential decision-making systems in the uncertain, constantly evolving real world. Working in such practical settings with unknown (and non-stationary) transition systems and changing tasks, the proposed framework models gaps in the agent's current state of knowledge and uses them to conduct focused, investigative explorations. Data collected using these explorations is used for learning generalizable probabilistic models for solving the current task despite continual changes in the environment dynamics. Empirical evaluations on several benchmark domains show that this approach significantly outperforms planning and RL baselines in terms of sample complexity in non-stationary settings. Theoretical results show that the system reverts to exhibit desirable convergence properties when stationarity holds.
Autonomous Capability Assessment of Black-Box Sequential Decision-Making Systems
Jun 07, 2023It is essential for users to understand what their AI systems can and can't do in order to use them safely. However, the problem of enabling users to assess AI systems with evolving sequential decision making (SDM) capabilities is relatively understudied. This paper presents a new approach for modeling the capabilities of black-box AI systems that can plan and act, along with the possible effects and requirements for executing those capabilities in stochastic settings. We present an active-learning approach that can effectively interact with a black-box SDM system and learn an interpretable probabilistic model describing its capabilities. Theoretical analysis of the approach identifies the conditions under which the learning process is guaranteed to converge to the correct model of the agent; empirical evaluations on different agents and simulated scenarios show that this approach is few-shot generalizable and can effectively describe the capabilities of arbitrary black-box SDM agents in a sample-efficient manner.
Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks
Apr 16, 2022

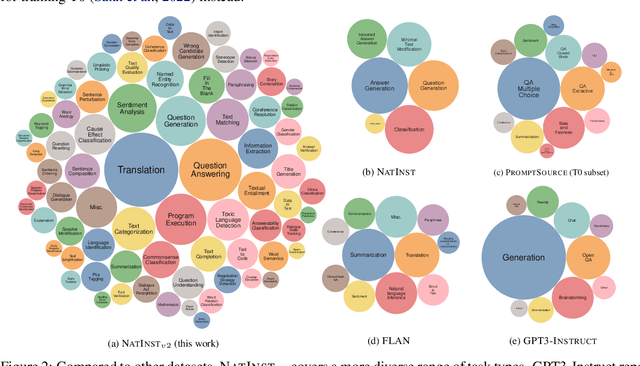
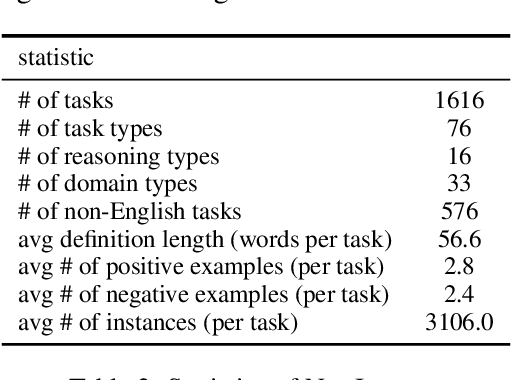
How can we measure the generalization of models to a variety of unseen tasks when provided with their language instructions? To facilitate progress in this goal, we introduce Natural-Instructions v2, a collection of 1,600+ diverse language tasks and their expert written instructions. More importantly, the benchmark covers 70+ distinct task types, such as tagging, in-filling, and rewriting. This benchmark is collected with contributions of NLP practitioners in the community and through an iterative peer review process to ensure their quality. This benchmark enables large-scale evaluation of cross-task generalization of the models -- training on a subset of tasks and evaluating on the remaining unseen ones. For instance, we are able to rigorously quantify generalization as a function of various scaling parameters, such as the number of observed tasks, the number of instances, and model sizes. As a by-product of these experiments. we introduce Tk-Instruct, an encoder-decoder Transformer that is trained to follow a variety of in-context instructions (plain language task definitions or k-shot examples) which outperforms existing larger models on our benchmark. We hope this benchmark facilitates future progress toward more general-purpose language understanding models.
Differential Assessment of Black-Box AI Agents
Mar 24, 2022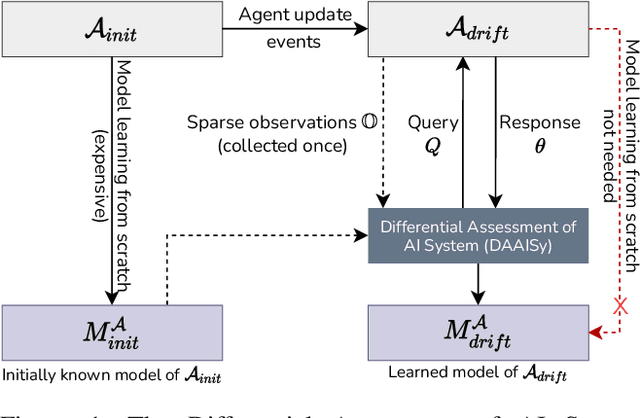


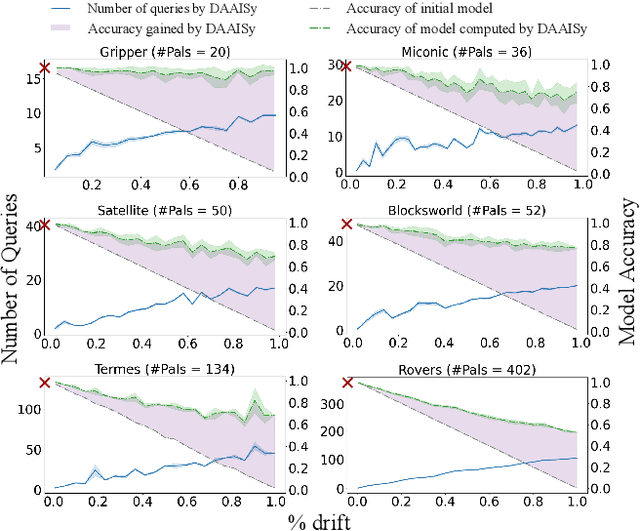
Much of the research on learning symbolic models of AI agents focuses on agents with stationary models. This assumption fails to hold in settings where the agent's capabilities may change as a result of learning, adaptation, or other post-deployment modifications. Efficient assessment of agents in such settings is critical for learning the true capabilities of an AI system and for ensuring its safe usage. In this work, we propose a novel approach to differentially assess black-box AI agents that have drifted from their previously known models. As a starting point, we consider the fully observable and deterministic setting. We leverage sparse observations of the drifted agent's current behavior and knowledge of its initial model to generate an active querying policy that selectively queries the agent and computes an updated model of its functionality. Empirical evaluation shows that our approach is much more efficient than re-learning the agent model from scratch. We also show that the cost of differential assessment using our method is proportional to the amount of drift in the agent's functionality.
JEDAI Explains Decision-Making AI
Oct 31, 2021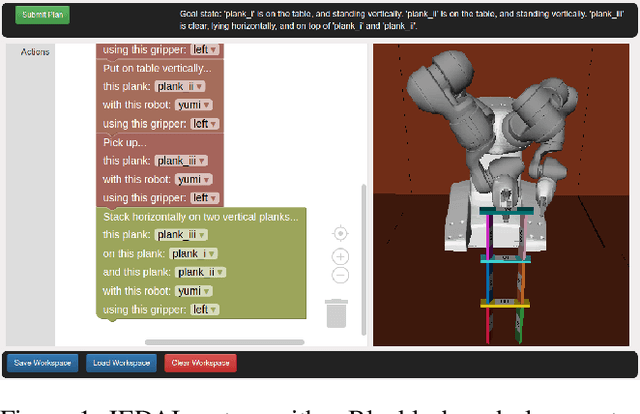
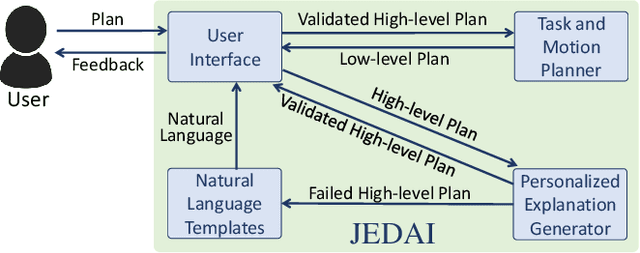
This paper presents JEDAI, an AI system designed for outreach and educational efforts aimed at non-AI experts. JEDAI features a novel synthesis of research ideas from integrated task and motion planning and explainable AI. JEDAI helps users create high-level, intuitive plans while ensuring that they will be executable by the robot. It also provides users customized explanations about errors and helps improve their understanding of AI planning as well as the limits and capabilities of the underlying robot system.