 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Distillation to Hybrid xLSTM Architectures
Mar 16, 2026There have been numerous attempts to distill quadratic attention-based large language models (LLMs) into sub-quadratic linearized architectures. However, despite extensive research, such distilled models often fail to match the performance of their teacher LLMs on various downstream tasks. We set out the goal of lossless distillation, which we define in terms of tolerance-corrected Win-and-Tie rates between student and teacher on sets of tasks. To this end, we introduce an effective distillation pipeline for xLSTM-based students. We propose an additional merging stage, where individually linearized experts are combined into a single model. We show the effectiveness of this pipeline by distilling base and instruction-tuned models from the Llama, Qwen, and Olmo families. In many settings, our xLSTM-based students recover most of the teacher's performance, and even exceed it on some downstream tasks. Our contributions are an important step towards more energy-efficient and cost-effective replacements for transformer-based LLMs.
Analyzing and Improving Cross-lingual Knowledge Transfer for Machine Translation
Jan 07, 2026Multilingual machine translation systems aim to make knowledge accessible across languages, yet learning effective cross-lingual representations remains challenging. These challenges are especially pronounced for low-resource languages, where limited parallel data constrains generalization and transfer. Understanding how multilingual models share knowledge across languages requires examining the interaction between representations, data availability, and training strategies. In this thesis, we study cross-lingual knowledge transfer in neural models and develop methods to improve robustness and generalization in multilingual settings, using machine translation as a central testbed. We analyze how similarity between languages influences transfer, how retrieval and auxiliary supervision can strengthen low-resource translation, and how fine-tuning on parallel data can introduce unintended trade-offs in large language models. We further examine the role of language diversity during training and show that increasing translation coverage improves generalization and reduces off-target behavior. Together, this work highlights how modeling choices and data composition shape multilingual learning and offers insights toward more inclusive and resilient multilingual NLP systems.
The Effect of Language Diversity When Fine-Tuning Large Language Models for Translation
May 19, 2025Prior research diverges on language diversity in LLM fine-tuning: Some studies report benefits while others find no advantages. Through controlled fine-tuning experiments across 132 translation directions, we systematically resolve these disparities. We find that expanding language diversity during fine-tuning improves translation quality for both unsupervised and -- surprisingly -- supervised pairs, despite less diverse models being fine-tuned exclusively on these supervised pairs. However, benefits plateau or decrease beyond a certain diversity threshold. We show that increased language diversity creates more language-agnostic representations. These representational adaptations help explain the improved performance in models fine-tuned with greater diversity.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Can LLMs Really Learn to Translate a Low-Resource Language from One Grammar Book?
Sep 27, 2024



Extremely low-resource (XLR) languages lack substantial corpora for training NLP models, motivating the use of all available resources such as dictionaries and grammar books. Machine Translation from One Book (Tanzer et al., 2024) suggests prompting long-context LLMs with one grammar book enables English-Kalamang translation, an unseen XLR language - a noteworthy case of linguistic knowledge helping an NLP task. We investigate whether the book's grammatical explanations or its parallel examples are most effective for learning XLR translation, finding almost all improvement stems from the parallel examples. Further, we find similar results for Nepali, a seen low-resource language, and achieve performance comparable to an LLM with a grammar book by simply fine-tuning an encoder-decoder translation model. We then investigate where grammar books help by testing two linguistic tasks, grammaticality judgment and gloss prediction, and we explore what kind of grammatical knowledge helps by introducing a typological feature prompt that achieves leading results on these more relevant tasks. We thus emphasise the importance of task-appropriate data for XLR languages: parallel examples for translation, and grammatical data for linguistic tasks. As we find no evidence that long-context LLMs can make effective use of grammatical explanations for XLR translation, we suggest data collection for multilingual XLR tasks such as translation is best focused on parallel data over linguistic description.
Data Contamination Report from the 2024 CONDA Shared Task
Jul 31, 2024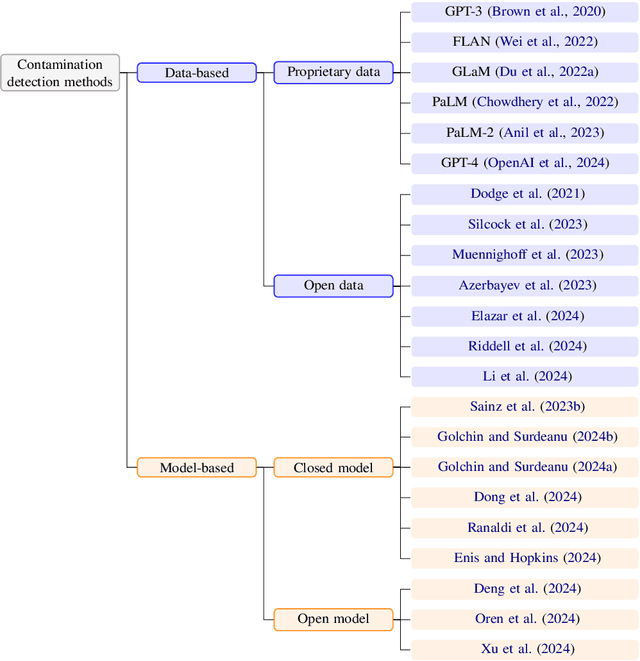
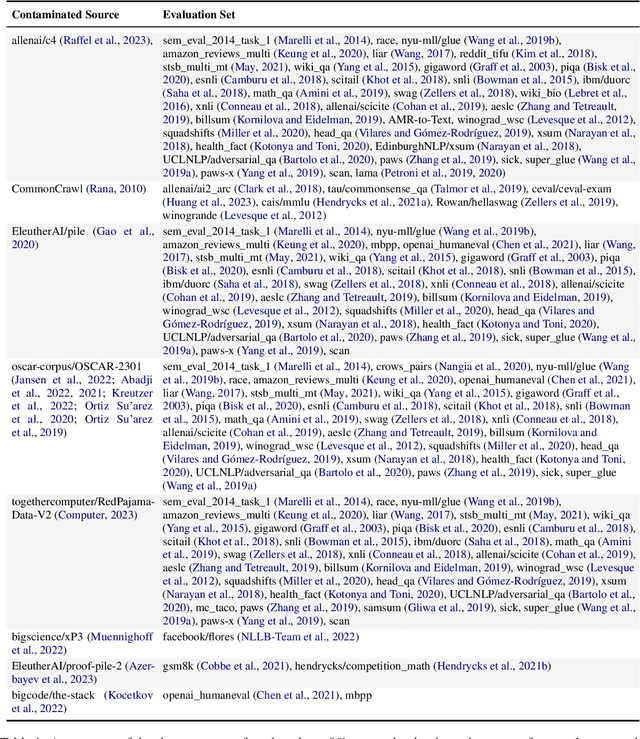
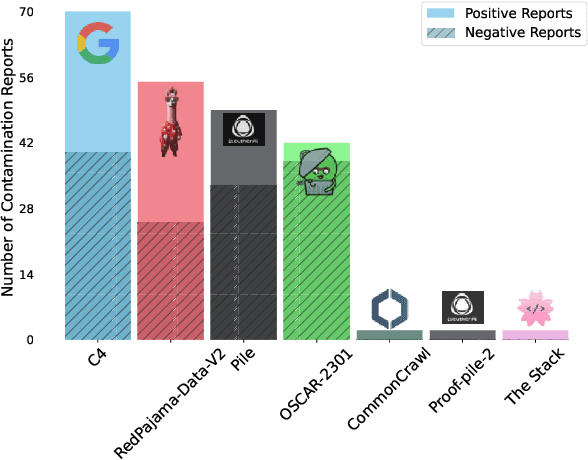
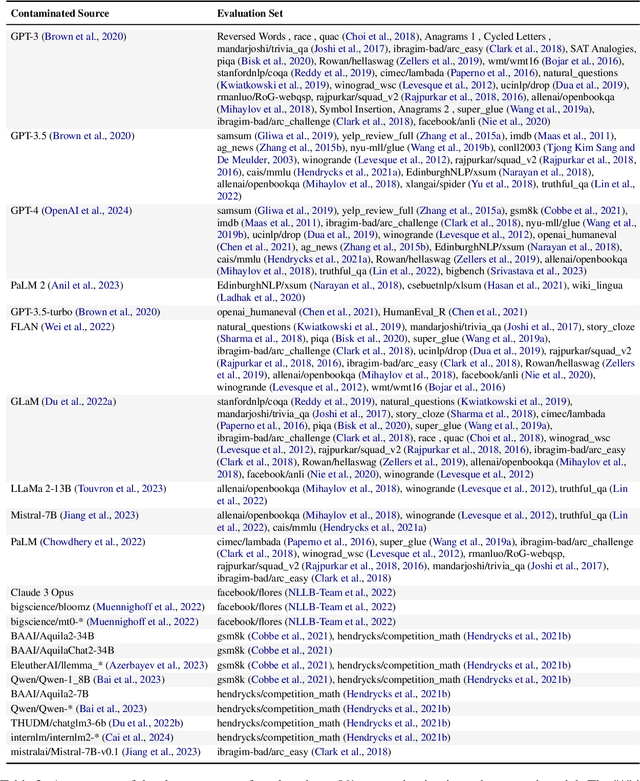
The 1st Workshop on Data Contamination (CONDA 2024) focuses on all relevant aspects of data contamination in natural language processing, where data contamination is understood as situations where evaluation data is included in pre-training corpora used to train large scale models, compromising evaluation results. The workshop fostered a shared task to collect evidence on data contamination in current available datasets and models. The goal of the shared task and associated database is to assist the community in understanding the extent of the problem and to assist researchers in avoiding reporting evaluation results on known contaminated resources. The shared task provides a structured, centralized public database for the collection of contamination evidence, open to contributions from the community via GitHub pool requests. This first compilation paper is based on 566 reported entries over 91 contaminated sources from a total of 23 contributors. The details of the individual contamination events are available in the platform. The platform continues to be online, open to contributions from the community.
The Fine-Tuning Paradox: Boosting Translation Quality Without Sacrificing LLM Abilities
May 30, 2024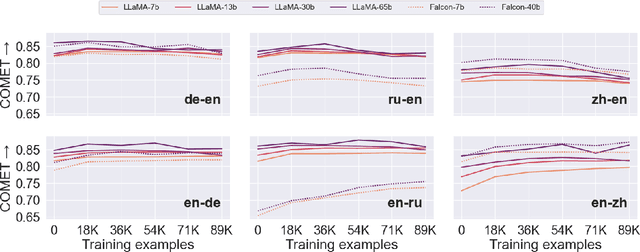

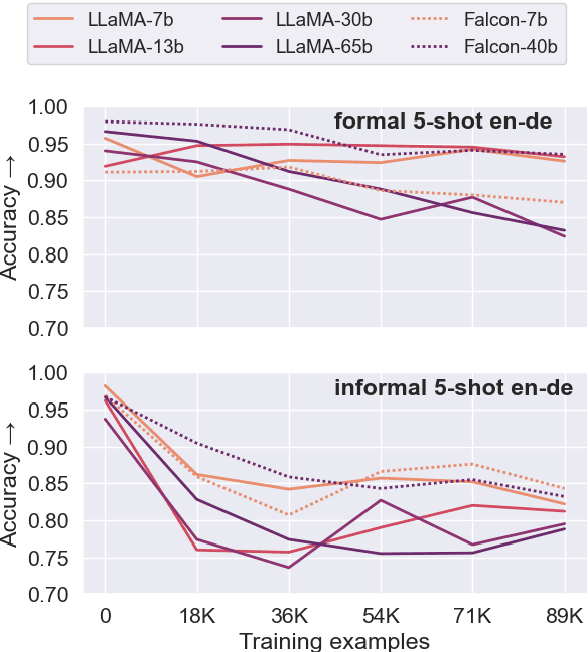
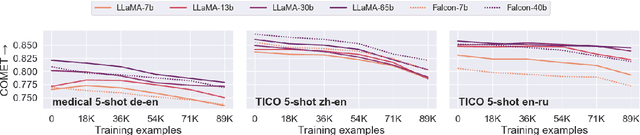
Fine-tuning large language models (LLMs) for machine translation has shown improvements in overall translation quality. However, it is unclear what is the impact of fine-tuning on desirable LLM behaviors that are not present in neural machine translation models, such as steerability, inherent document-level translation abilities, and the ability to produce less literal translations. We perform an extensive translation evaluation on the LLaMA and Falcon family of models with model size ranging from 7 billion up to 65 billion parameters. Our results show that while fine-tuning improves the general translation quality of LLMs, several abilities degrade. In particular, we observe a decline in the ability to perform formality steering, to produce technical translations through few-shot examples, and to perform document-level translation. On the other hand, we observe that the model produces less literal translations after fine-tuning on parallel data. We show that by including monolingual data as part of the fine-tuning data we can maintain the abilities while simultaneously enhancing overall translation quality. Our findings emphasize the need for fine-tuning strategies that preserve the benefits of LLMs for machine translation.
How Far Can 100 Samples Go? Unlocking Overall Zero-Shot Multilingual Translation via Tiny Multi-Parallel Data
Jan 22, 2024Zero-shot translation is an open problem, aiming to translate between language pairs unseen during training in Multilingual Machine Translation (MMT). A common, albeit resource-consuming, solution is to mine as many translation directions as possible to add to the parallel corpus. In this paper, we show that the zero-shot capability of an English-centric model can be easily enhanced by fine-tuning with a very small amount of multi-parallel data. For example, on the EC30 dataset, we show that up to +21.7 ChrF non-English overall improvements (870 directions) can be achieved by using only 100 multi-parallel samples, meanwhile preserving capability in English-centric directions. We further study the size effect of fine-tuning data and its transfer capabilities. Surprisingly, our empirical analysis shows that comparable overall improvements can be achieved even through fine-tuning in a small, randomly sampled direction set (10\%). Also, the resulting non-English performance is quite close to the upper bound (complete translation). Due to its high efficiency and practicality, we encourage the community 1) to consider the use of the fine-tuning method as a strong baseline for zero-shot translation and 2) to construct more comprehensive and high-quality multi-parallel data to cover real-world demand.
Multilingual k-Nearest-Neighbor Machine Translation
Oct 23, 2023



k-nearest-neighbor machine translation has demonstrated remarkable improvements in machine translation quality by creating a datastore of cached examples. However, these improvements have been limited to high-resource language pairs, with large datastores, and remain a challenge for low-resource languages. In this paper, we address this issue by combining representations from multiple languages into a single datastore. Our results consistently demonstrate substantial improvements not only in low-resource translation quality (up to +3.6 BLEU), but also for high-resource translation quality (up to +0.5 BLEU). Our experiments show that it is possible to create multilingual datastores that are a quarter of the size, achieving a 5.3x speed improvement, by using linguistic similarities for datastore creation.