 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Does LLM Refinement Actually Improve? A Systematic Study on Document-Level Literary Translation
May 13, 2026Iterative self-refinement is a simple inference-time strategy for machine translation: an LLM revises its own translation over multiple inference-time passes. Yet document-scale refinement remains poorly understood: 1) which pipelines work best, 2) what quality dimensions improve, and 3) how refiners behave. In this paper, we present a systematic study of document-level literary translation, covering nine LLMs and seven language pairs. Across nine translation-refinement granularity combinations and five refinement strategies, we find a robust recipe: document-level MT followed by segment-level refinement yields strong and stable improvements. In contrast, document-level refinement often makes fewer edits and leads to smaller or less reliable gains. Beyond granularity, A simple general refinement prompt consistently outperforms error-specific prompting and evaluate-then-refine schemes. Our large-scale human evaluation shows that refinement gains come primarily from fluency, style, and terminology, with limited and less consistent improvements in adequacy. Experiments varying model strength reveal refinement projects outputs toward the refiner's distribution rather than performing targeted error repair. These findings clarify the mechanisms and limitations of current refinement approaches.
The Fine-Tuning Paradox: Boosting Translation Quality Without Sacrificing LLM Abilities
May 30, 2024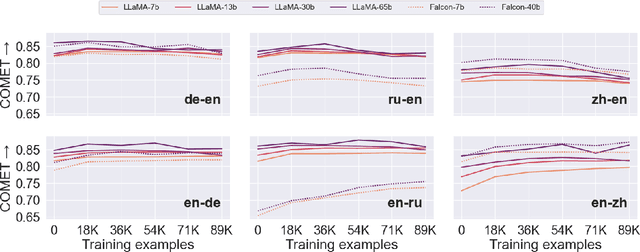

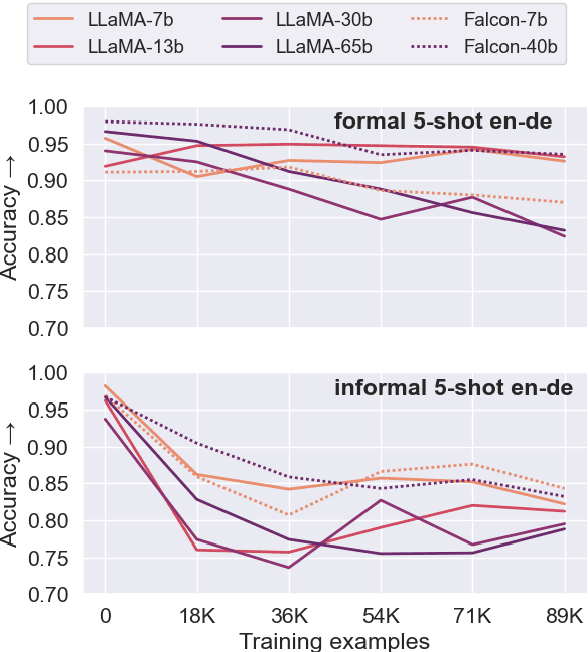
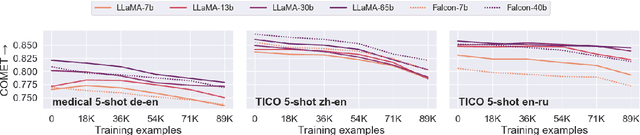
Fine-tuning large language models (LLMs) for machine translation has shown improvements in overall translation quality. However, it is unclear what is the impact of fine-tuning on desirable LLM behaviors that are not present in neural machine translation models, such as steerability, inherent document-level translation abilities, and the ability to produce less literal translations. We perform an extensive translation evaluation on the LLaMA and Falcon family of models with model size ranging from 7 billion up to 65 billion parameters. Our results show that while fine-tuning improves the general translation quality of LLMs, several abilities degrade. In particular, we observe a decline in the ability to perform formality steering, to produce technical translations through few-shot examples, and to perform document-level translation. On the other hand, we observe that the model produces less literal translations after fine-tuning on parallel data. We show that by including monolingual data as part of the fine-tuning data we can maintain the abilities while simultaneously enhancing overall translation quality. Our findings emphasize the need for fine-tuning strategies that preserve the benefits of LLMs for machine translation.
Sockeye 3: Fast Neural Machine Translation with PyTorch
Jul 12, 2022
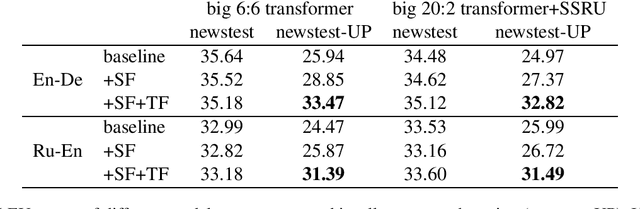

Sockeye 3 is the latest version of the Sockeye toolkit for Neural Machine Translation (NMT). Now based on PyTorch, Sockeye 3 provides faster model implementations and more advanced features with a further streamlined codebase. This enables broader experimentation with faster iteration, efficient training of stronger and faster models, and the flexibility to move new ideas quickly from research to production. When running comparable models, Sockeye 3 is up to 126% faster than other PyTorch implementations on GPUs and up to 292% faster on CPUs. Sockeye 3 is open source software released under the Apache 2.0 license.
The Devil is in the Details: On the Pitfalls of Vocabulary Selection in Neural Machine Translation
May 13, 2022



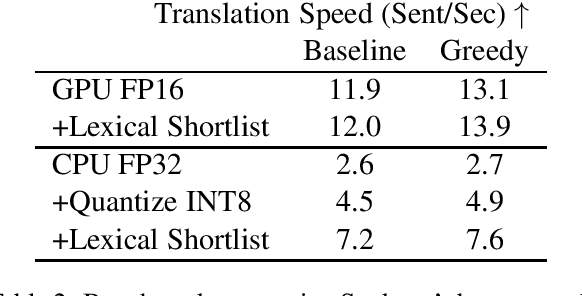
Vocabulary selection, or lexical shortlisting, is a well-known technique to improve latency of Neural Machine Translation models by constraining the set of allowed output words during inference. The chosen set is typically determined by separately trained alignment model parameters, independent of the source-sentence context at inference time. While vocabulary selection appears competitive with respect to automatic quality metrics in prior work, we show that it can fail to select the right set of output words, particularly for semantically non-compositional linguistic phenomena such as idiomatic expressions, leading to reduced translation quality as perceived by humans. Trading off latency for quality by increasing the size of the allowed set is often not an option in real-world scenarios. We propose a model of vocabulary selection, integrated into the neural translation model, that predicts the set of allowed output words from contextualized encoder representations. This restores translation quality of an unconstrained system, as measured by human evaluations on WMT newstest2020 and idiomatic expressions, at an inference latency competitive with alignment-based selection using aggressive thresholds, thereby removing the dependency on separately trained alignment models.
Generating Synthetic Data for Task-Oriented Semantic Parsing with Hierarchical Representations
Nov 03, 2020
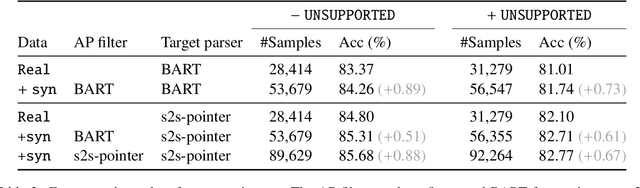
Modern conversational AI systems support natural language understanding for a wide variety of capabilities. While a majority of these tasks can be accomplished using a simple and flat representation of intents and slots, more sophisticated capabilities require complex hierarchical representations supported by semantic parsing. State-of-the-art semantic parsers are trained using supervised learning with data labeled according to a hierarchical schema which might be costly to obtain or not readily available for a new domain. In this work, we explore the possibility of generating synthetic data for neural semantic parsing using a pretrained denoising sequence-to-sequence model (i.e., BART). Specifically, we first extract masked templates from the existing labeled utterances, and then fine-tune BART to generate synthetic utterances conditioning on the extracted templates. Finally, we use an auxiliary parser (AP) to filter the generated utterances. The AP guarantees the quality of the generated data. We show the potential of our approach when evaluating on the Facebook TOP dataset for navigation domain.
From English To Foreign Languages: Transferring Pre-trained Language Models
Feb 18, 2020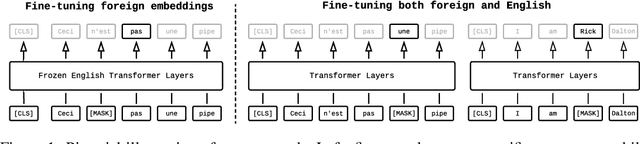

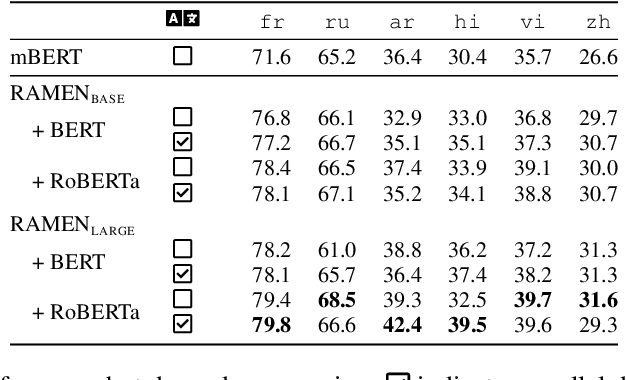
Pre-trained models have demonstrated their effectiveness in many downstream natural language processing (NLP) tasks. The availability of multilingual pre-trained models enables zero-shot transfer of NLP tasks from high resource languages to low resource ones. However, recent research in improving pre-trained models focuses heavily on English. While it is possible to train the latest neural architectures for other languages from scratch, it is undesirable due to the required amount of compute. In this work, we tackle the problem of transferring an existing pre-trained model from English to other languages under a limited computational budget. With a single GPU, our approach can obtain a foreign BERT base model within a day and a foreign BERT large within two days. Furthermore, evaluating our models on six languages, we demonstrate that our models are better than multilingual BERT on two zero-shot tasks: natural language inference and dependency parsing.
Zero-shot Dependency Parsing with Pre-trained Multilingual Sentence Representations
Oct 12, 2019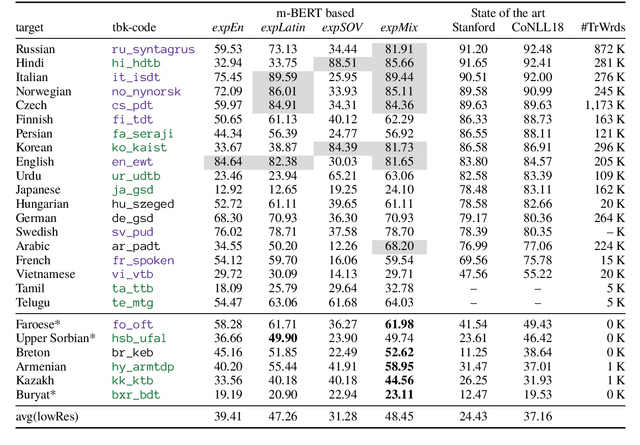
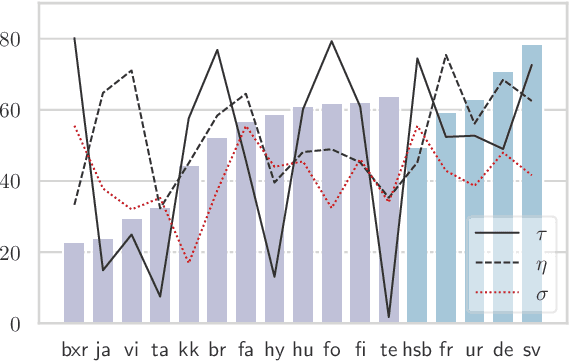
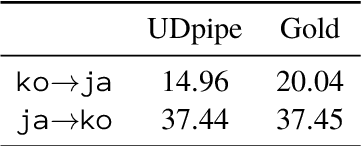
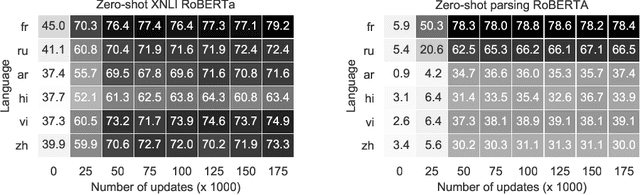
We investigate whether off-the-shelf deep bidirectional sentence representations trained on a massively multilingual corpus (multilingual BERT) enable the development of an unsupervised universal dependency parser. This approach only leverages a mix of monolingual corpora in many languages and does not require any translation data making it applicable to low-resource languages. In our experiments we outperform the best CoNLL 2018 language-specific systems in all of the shared task's six truly low-resource languages while using a single system. However, we also find that (i) parsing accuracy still varies dramatically when changing the training languages and (ii) in some target languages zero-shot transfer fails under all tested conditions, raising concerns on the 'universality' of the whole approach.
The Importance of Being Recurrent for Modeling Hierarchical Structure
Aug 28, 2018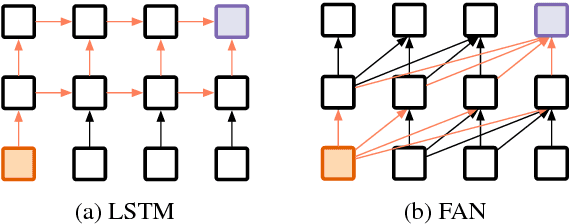

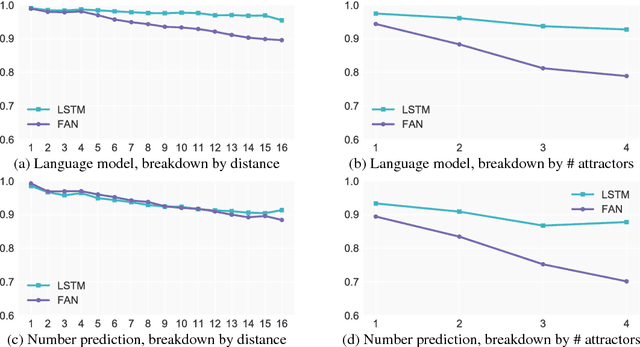

Recent work has shown that recurrent neural networks (RNNs) can implicitly capture and exploit hierarchical information when trained to solve common natural language processing tasks such as language modeling (Linzen et al., 2016) and neural machine translation (Shi et al., 2016). In contrast, the ability to model structured data with non-recurrent neural networks has received little attention despite their success in many NLP tasks (Gehring et al., 2017; Vaswani et al., 2017). In this work, we compare the two architectures---recurrent versus non-recurrent---with respect to their ability to model hierarchical structure and find that recurrency is indeed important for this purpose.
Inducing Grammars with and for Neural Machine Translation
May 28, 2018
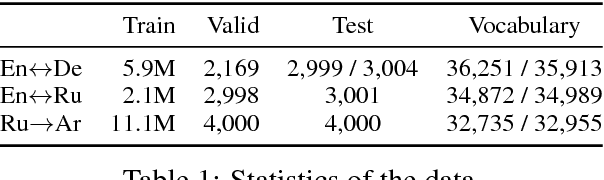
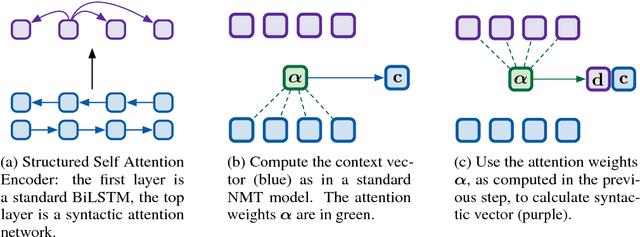
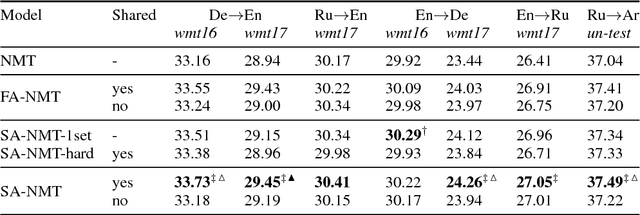
Machine translation systems require semantic knowledge and grammatical understanding. Neural machine translation (NMT) systems often assume this information is captured by an attention mechanism and a decoder that ensures fluency. Recent work has shown that incorporating explicit syntax alleviates the burden of modeling both types of knowledge. However, requiring parses is expensive and does not explore the question of what syntax a model needs during translation. To address both of these issues we introduce a model that simultaneously translates while inducing dependency trees. In this way, we leverage the benefits of structure while investigating what syntax NMT must induce to maximize performance. We show that our dependency trees are 1. language pair dependent and 2. improve translation quality.
Examining Cooperation in Visual Dialog Models
Dec 04, 2017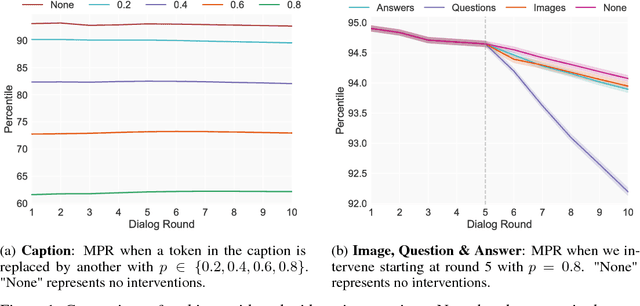
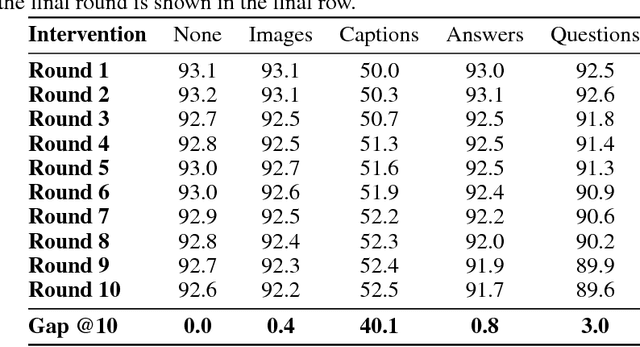
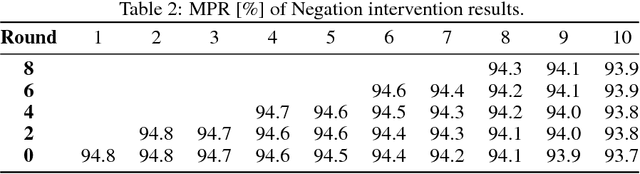

In this work we propose a blackbox intervention method for visual dialog models, with the aim of assessing the contribution of individual linguistic or visual components. Concretely, we conduct structured or randomized interventions that aim to impair an individual component of the model, and observe changes in task performance. We reproduce a state-of-the-art visual dialog model and demonstrate that our methodology yields surprising insights, namely that both dialog and image information have minimal contributions to task performance. The intervention method presented here can be applied as a sanity check for the strength and robustness of each component in visual dialog systems.