Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining Cooperation in Visual Dialog Models
Paper and Code
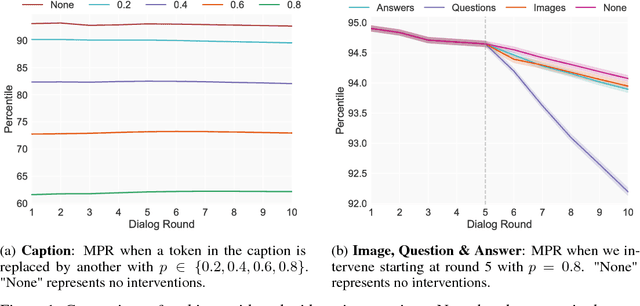
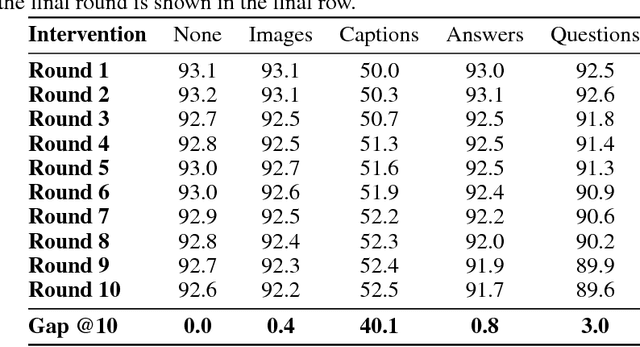
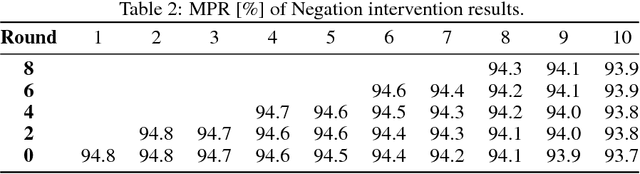

In this work we propose a blackbox intervention method for visual dialog models, with the aim of assessing the contribution of individual linguistic or visual components. Concretely, we conduct structured or randomized interventions that aim to impair an individual component of the model, and observe changes in task performance. We reproduce a state-of-the-art visual dialog model and demonstrate that our methodology yields surprising insights, namely that both dialog and image information have minimal contributions to task performance. The intervention method presented here can be applied as a sanity check for the strength and robustness of each component in visual dialog systems.
* 9 pages, 5 figures, 2 tables, code at
http://github.com/danakianfar/Examining-Cooperation-in-VDM/
View paper on