 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLie Group Decompositions for Equivariant Neural Networks
Oct 17, 2023Invariance and equivariance to geometrical transformations have proven to be very useful inductive biases when training (convolutional) neural network models, especially in the low-data regime. Much work has focused on the case where the symmetry group employed is compact or abelian, or both. Recent work has explored enlarging the class of transformations used to the case of Lie groups, principally through the use of their Lie algebra, as well as the group exponential and logarithm maps. The applicability of such methods to larger transformation groups is limited by the fact that depending on the group of interest $G$, the exponential map may not be surjective. Further limitations are encountered when $G$ is neither compact nor abelian. Using the structure and geometry of Lie groups and their homogeneous spaces, we present a framework by which it is possible to work with such groups primarily focusing on the Lie groups $G = \text{GL}^{+}(n, \mathbb{R})$ and $G = \text{SL}(n, \mathbb{R})$, as well as their representation as affine transformations $\mathbb{R}^{n} \rtimes G$. Invariant integration as well as a global parametrization is realized by decomposing the `larger` groups into subgroups and submanifolds which can be handled individually. Under this framework, we show how convolution kernels can be parametrized to build models equivariant with respect to affine transformations. We evaluate the robustness and out-of-distribution generalisation capability of our model on the standard affine-invariant benchmark classification task, where we outperform all previous equivariant models as well as all Capsule Network proposals.
Examining Cooperation in Visual Dialog Models
Dec 04, 2017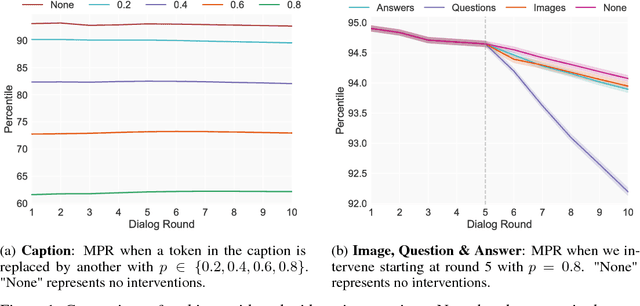
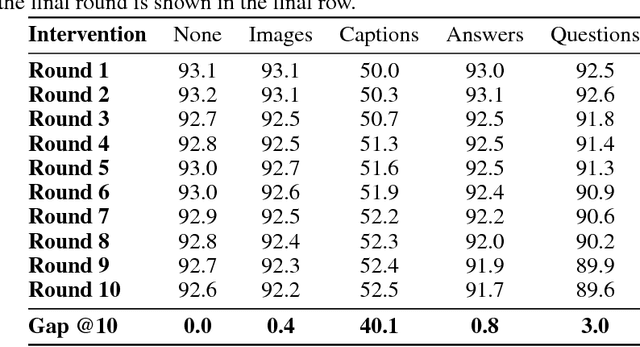
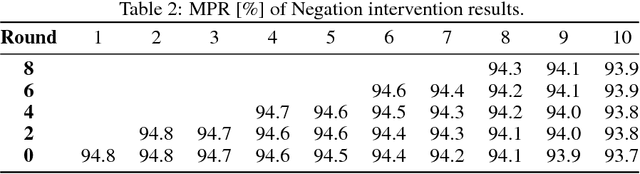

In this work we propose a blackbox intervention method for visual dialog models, with the aim of assessing the contribution of individual linguistic or visual components. Concretely, we conduct structured or randomized interventions that aim to impair an individual component of the model, and observe changes in task performance. We reproduce a state-of-the-art visual dialog model and demonstrate that our methodology yields surprising insights, namely that both dialog and image information have minimal contributions to task performance. The intervention method presented here can be applied as a sanity check for the strength and robustness of each component in visual dialog systems.