 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Interpretable Spatial Operations in a Rich 3D Blocks World
Dec 24, 2017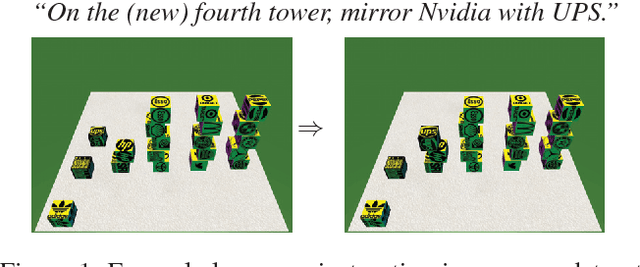


In this paper, we study the problem of mapping natural language instructions to complex spatial actions in a 3D blocks world. We first introduce a new dataset that pairs complex 3D spatial operations to rich natural language descriptions that require complex spatial and pragmatic interpretations such as "mirroring", "twisting", and "balancing". This dataset, built on the simulation environment of Bisk, Yuret, and Marcu (2016), attains language that is significantly richer and more complex, while also doubling the size of the original dataset in the 2D environment with 100 new world configurations and 250,000 tokens. In addition, we propose a new neural architecture that achieves competitive results while automatically discovering an inventory of interpretable spatial operations (Figure 5)
Unsupervised Neural Hidden Markov Models
Sep 28, 2016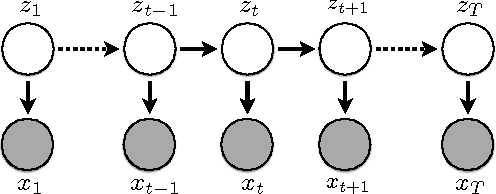

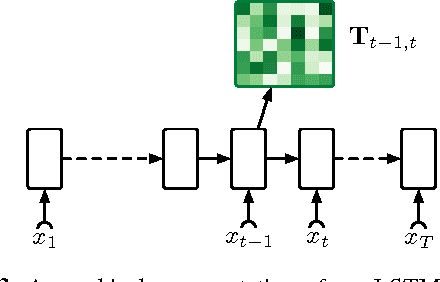
In this work, we present the first results for neuralizing an Unsupervised Hidden Markov Model. We evaluate our approach on tag in- duction. Our approach outperforms existing generative models and is competitive with the state-of-the-art though with a simpler model easily extended to include additional context.
Extracting Biomolecular Interactions Using Semantic Parsing of Biomedical Text
Dec 04, 2015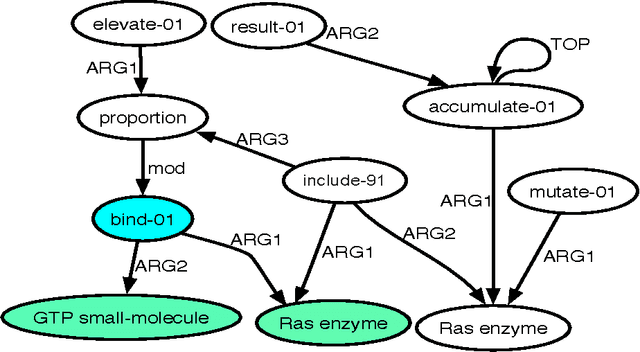
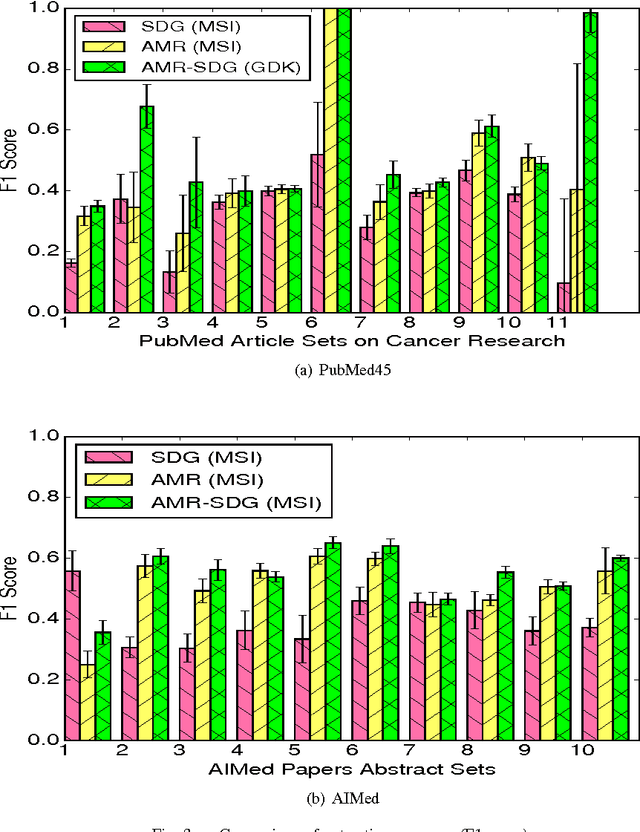
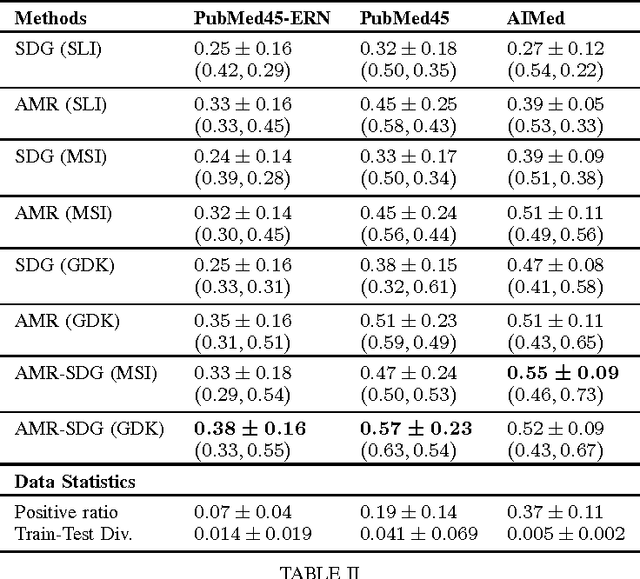
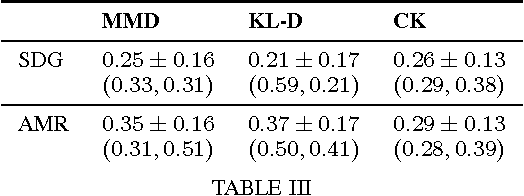
We advance the state of the art in biomolecular interaction extraction with three contributions: (i) We show that deep, Abstract Meaning Representations (AMR) significantly improve the accuracy of a biomolecular interaction extraction system when compared to a baseline that relies solely on surface- and syntax-based features; (ii) In contrast with previous approaches that infer relations on a sentence-by-sentence basis, we expand our framework to enable consistent predictions over sets of sentences (documents); (iii) We further modify and expand a graph kernel learning framework to enable concurrent exploitation of automatically induced AMR (semantic) and dependency structure (syntactic) representations. Our experiments show that our approach yields interaction extraction systems that are more robust in environments where there is a significant mismatch between training and test conditions.
Using Syntax-Based Machine Translation to Parse English into Abstract Meaning Representation
Apr 28, 2015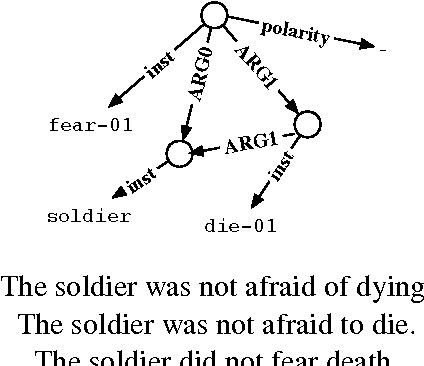



We present a parser for Abstract Meaning Representation (AMR). We treat English-to-AMR conversion within the framework of string-to-tree, syntax-based machine translation (SBMT). To make this work, we transform the AMR structure into a form suitable for the mechanics of SBMT and useful for modeling. We introduce an AMR-specific language model and add data and features drawn from semantic resources. Our resulting AMR parser improves upon state-of-the-art results by 7 Smatch points.
Induction of Word and Phrase Alignments for Automatic Document Summarization
Jul 04, 2009Current research in automatic single document summarization is dominated by two effective, yet naive approaches: summarization by sentence extraction, and headline generation via bag-of-words models. While successful in some tasks, neither of these models is able to adequately capture the large set of linguistic devices utilized by humans when they produce summaries. One possible explanation for the widespread use of these models is that good techniques have been developed to extract appropriate training data for them from existing document/abstract and document/headline corpora. We believe that future progress in automatic summarization will be driven both by the development of more sophisticated, linguistically informed models, as well as a more effective leveraging of document/abstract corpora. In order to open the doors to simultaneously achieving both of these goals, we have developed techniques for automatically producing word-to-word and phrase-to-phrase alignments between documents and their human-written abstracts. These alignments make explicit the correspondences that exist in such document/abstract pairs, and create a potentially rich data source from which complex summarization algorithms may learn. This paper describes experiments we have carried out to analyze the ability of humans to perform such alignments, and based on these analyses, we describe experiments for creating them automatically. Our model for the alignment task is based on an extension of the standard hidden Markov model, and learns to create alignments in a completely unsupervised fashion. We describe our model in detail and present experimental results that show that our model is able to learn to reliably identify word- and phrase-level alignments in a corpus of <document,abstract> pairs.
Learning as Search Optimization: Approximate Large Margin Methods for Structured Prediction
Jul 04, 2009
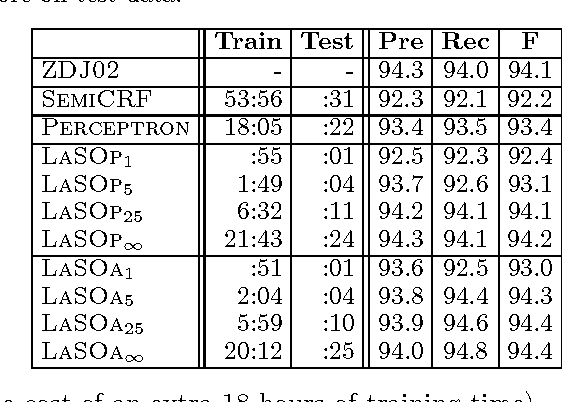

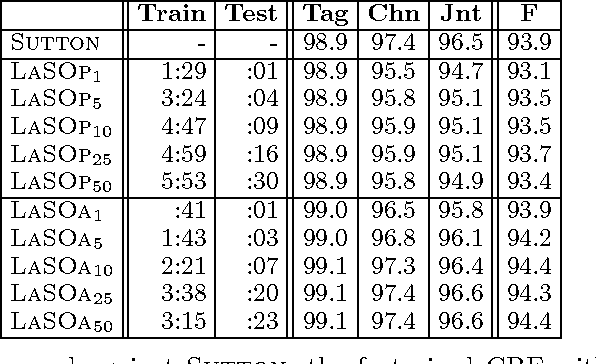
Mappings to structured output spaces (strings, trees, partitions, etc.) are typically learned using extensions of classification algorithms to simple graphical structures (eg., linear chains) in which search and parameter estimation can be performed exactly. Unfortunately, in many complex problems, it is rare that exact search or parameter estimation is tractable. Instead of learning exact models and searching via heuristic means, we embrace this difficulty and treat the structured output problem in terms of approximate search. We present a framework for learning as search optimization, and two parameter updates with convergence theorems and bounds. Empirical evidence shows that our integrated approach to learning and decoding can outperform exact models at smaller computational cost.
A Bayesian Model for Supervised Clustering with the Dirichlet Process Prior
Jul 04, 2009
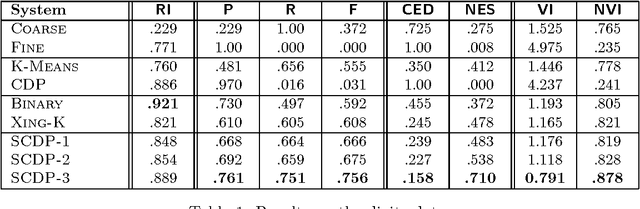

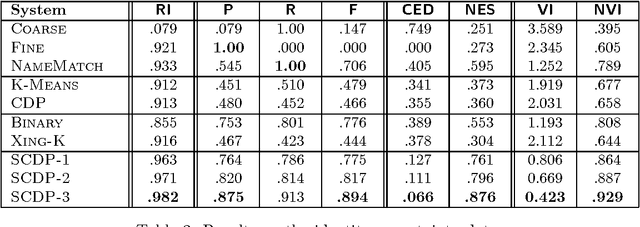
We develop a Bayesian framework for tackling the supervised clustering problem, the generic problem encountered in tasks such as reference matching, coreference resolution, identity uncertainty and record linkage. Our clustering model is based on the Dirichlet process prior, which enables us to define distributions over the countably infinite sets that naturally arise in this problem. We add supervision to our model by positing the existence of a set of unobserved random variables (we call these "reference types") that are generic across all clusters. Inference in our framework, which requires integrating over infinitely many parameters, is solved using Markov chain Monte Carlo techniques. We present algorithms for both conjugate and non-conjugate priors. We present a simple--but general--parameterization of our model based on a Gaussian assumption. We evaluate this model on one artificial task and three real-world tasks, comparing it against both unsupervised and state-of-the-art supervised algorithms. Our results show that our model is able to outperform other models across a variety of tasks and performance metrics.
A Large-Scale Exploration of Effective Global Features for a Joint Entity Detection and Tracking Model
Jul 04, 2009

Entity detection and tracking (EDT) is the task of identifying textual mentions of real-world entities in documents, extending the named entity detection and coreference resolution task by considering mentions other than names (pronouns, definite descriptions, etc.). Like NE tagging and coreference resolution, most solutions to the EDT task separate out the mention detection aspect from the coreference aspect. By doing so, these solutions are limited to using only local features for learning. In contrast, by modeling both aspects of the EDT task simultaneously, we are able to learn using highly complex, non-local features. We develop a new joint EDT model and explore the utility of many features, demonstrating their effectiveness on this task.
A Noisy-Channel Model for Document Compression
Jul 04, 2009
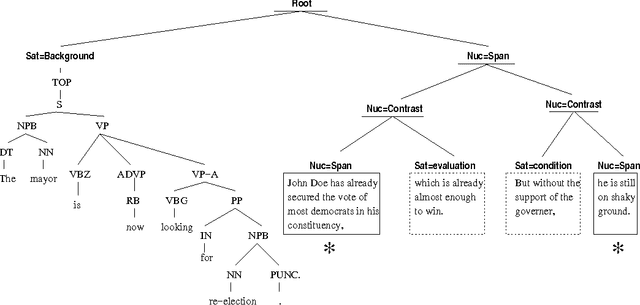

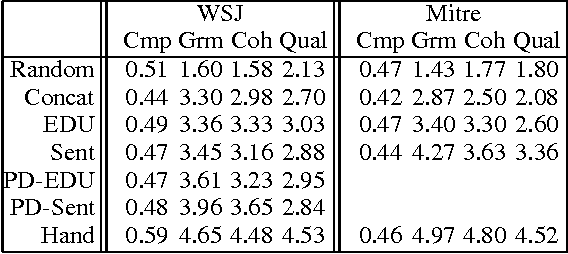
We present a document compression system that uses a hierarchical noisy-channel model of text production. Our compression system first automatically derives the syntactic structure of each sentence and the overall discourse structure of the text given as input. The system then uses a statistical hierarchical model of text production in order to drop non-important syntactic and discourse constituents so as to generate coherent, grammatical document compressions of arbitrary length. The system outperforms both a baseline and a sentence-based compression system that operates by simplifying sequentially all sentences in a text. Our results support the claim that discourse knowledge plays an important role in document summarization.
Search-based Structured Prediction
Jul 04, 2009
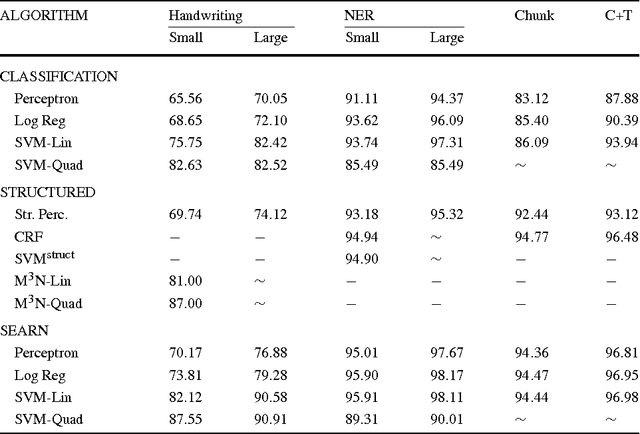


We present Searn, an algorithm for integrating search and learning to solve complex structured prediction problems such as those that occur in natural language, speech, computational biology, and vision. Searn is a meta-algorithm that transforms these complex problems into simple classification problems to which any binary classifier may be applied. Unlike current algorithms for structured learning that require decomposition of both the loss function and the feature functions over the predicted structure, Searn is able to learn prediction functions for any loss function and any class of features. Moreover, Searn comes with a strong, natural theoretical guarantee: good performance on the derived classification problems implies good performance on the structured prediction problem.