 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMARTER: A Data-efficient Framework to Improve Toxicity Detection with Explanation via Self-augmenting Large Language Models
Sep 18, 2025WARNING: This paper contains examples of offensive materials. Toxic content has become pervasive on social media platforms. We introduce SMARTER, a data-efficient two-stage framework for explainable content moderation using Large Language Models (LLMs). In Stage 1, we leverage LLMs' own outputs to generate synthetic explanations for both correct and incorrect labels, enabling alignment via preference optimization with minimal human supervision. In Stage 2, we refine explanation quality through cross-model training, allowing weaker models to align stylistically and semantically with stronger ones. Experiments on three benchmark tasks -- HateXplain, Latent Hate, and Implicit Hate -- demonstrate that SMARTER enables LLMs to achieve up to a 13.5% macro-F1 improvement over standard few-shot baselines while using only a fraction of the full training data. Our framework offers a scalable strategy for low-resource settings by harnessing LLMs' self-improving capabilities for both classification and explanation.
An Interdisciplinary Approach to Human-Centered Machine Translation
Jun 16, 2025Machine Translation (MT) tools are widely used today, often in contexts where professional translators are not present. Despite progress in MT technology, a gap persists between system development and real-world usage, particularly for non-expert users who may struggle to assess translation reliability. This paper advocates for a human-centered approach to MT, emphasizing the alignment of system design with diverse communicative goals and contexts of use. We survey the literature in Translation Studies and Human-Computer Interaction to recontextualize MT evaluation and design to address the diverse real-world scenarios in which MT is used today.
A Necessary Step toward Faithfulness: Measuring and Improving Consistency in Free-Text Explanations
May 25, 2025



Faithful free-text explanations are important to ensure transparency in high-stakes AI decision-making contexts, but they are challenging to generate by language models and assess by humans. In this paper, we present a measure for Prediction-EXplanation (PEX) consistency, by extending the concept of weight of evidence. This measure quantifies how much a free-text explanation supports or opposes a prediction, serving as an important aspect of explanation faithfulness. Our analysis reveals that more than 62% explanations generated by large language models lack this consistency. We show that applying direct preference optimization improves the consistency of generated explanations across three model families, with improvement ranging from 43.1% to 292.3%. Furthermore, we demonstrate that optimizing this consistency measure can improve explanation faithfulness by up to 9.7%.
Effort-aware Fairness: Incorporating a Philosophy-informed, Human-centered Notion of Effort into Algorithmic Fairness Metrics
May 25, 2025



Although popularized AI fairness metrics, e.g., demographic parity, have uncovered bias in AI-assisted decision-making outcomes, they do not consider how much effort one has spent to get to where one is today in the input feature space. However, the notion of effort is important in how Philosophy and humans understand fairness. We propose a philosophy-informed way to conceptualize and evaluate Effort-aware Fairness (EaF) based on the concept of Force, or temporal trajectory of predictive features coupled with inertia. In addition to our theoretical formulation of EaF metrics, our empirical contributions include: 1/ a pre-registered human subjects experiment, which demonstrates that for both stages of the (individual) fairness evaluation process, people consider the temporal trajectory of a predictive feature more than its aggregate value; 2/ pipelines to compute Effort-aware Individual/Group Fairness in the criminal justice and personal finance contexts. Our work may enable AI model auditors to uncover and potentially correct unfair decisions against individuals who spent significant efforts to improve but are still stuck with systemic/early-life disadvantages outside their control.
Which Demographic Features Are Relevant for Individual Fairness Evaluation of U.S. Recidivism Risk Assessment Tools?
May 15, 2025Despite its U.S. constitutional foundation, the technical ``individual fairness'' criterion has not been operationalized in state or federal statutes/regulations. We conduct a human subjects experiment to address this gap, evaluating which demographic features are relevant for individual fairness evaluation of recidivism risk assessment (RRA) tools. Our analyses conclude that the individual similarity function should consider age and sex, but it should ignore race.
Language Models Predict Empathy Gaps Between Social In-groups and Out-groups
Mar 02, 2025Studies of human psychology have demonstrated that people are more motivated to extend empathy to in-group members than out-group members (Cikara et al., 2011). In this study, we investigate how this aspect of intergroup relations in humans is replicated by LLMs in an emotion intensity prediction task. In this task, the LLM is given a short description of an experience a person had that caused them to feel a particular emotion; the LLM is then prompted to predict the intensity of the emotion the person experienced on a numerical scale. By manipulating the group identities assigned to the LLM's persona (the "perceiver") and the person in the narrative (the "experiencer"), we measure how predicted emotion intensities differ between in-group and out-group settings. We observe that LLMs assign higher emotion intensity scores to in-group members than out-group members. This pattern holds across all three types of social groupings we tested: race/ethnicity, nationality, and religion. We perform an in-depth analysis on Llama-3.1-8B, the model which exhibited strongest intergroup bias among those tested.
Can Hallucination Correction Improve Video-Language Alignment?
Feb 20, 2025Large Vision-Language Models often generate hallucinated content that is not grounded in its visual inputs. While prior work focuses on mitigating hallucinations, we instead explore leveraging hallucination correction as a training objective to improve video-language alignment. We introduce HACA, a self-training framework learning to correct hallucinations in descriptions that do not align with the video content. By identifying and correcting inconsistencies, HACA enhances the model's ability to align video and textual representations for spatio-temporal reasoning. Our experimental results show consistent gains in video-caption binding and text-to-video retrieval tasks, demonstrating that hallucination correction-inspired tasks serve as an effective strategy for improving vision and language alignment.
My LLM might Mimic AAE -- But When Should it?
Feb 06, 2025
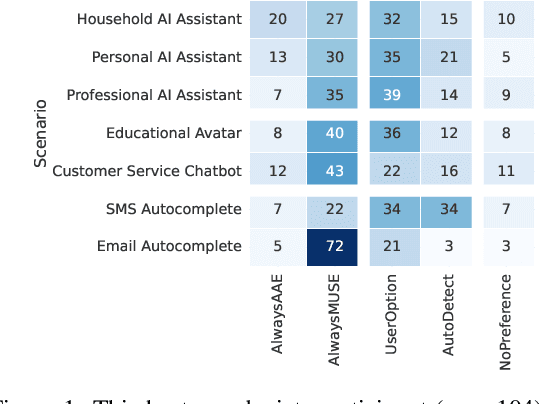


We examine the representation of African American English (AAE) in large language models (LLMs), exploring (a) the perceptions Black Americans have of how effective these technologies are at producing authentic AAE, and (b) in what contexts Black Americans find this desirable. Through both a survey of Black Americans ($n=$ 104) and annotation of LLM-produced AAE by Black Americans ($n=$ 228), we find that Black Americans favor choice and autonomy in determining when AAE is appropriate in LLM output. They tend to prefer that LLMs default to communicating in Mainstream U.S. English in formal settings, with greater interest in AAE production in less formal settings. When LLMs were appropriately prompted and provided in context examples, our participants found their outputs to have a level of AAE authenticity on par with transcripts of Black American speech. Select code and data for our project can be found here: https://github.com/smelliecat/AAEMime.git
TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies
Dec 13, 2024Although large vision-language-action (VLA) models pretrained on extensive robot datasets offer promising generalist policies for robotic learning, they still struggle with spatial-temporal dynamics in interactive robotics, making them less effective in handling complex tasks, such as manipulation. In this work, we introduce visual trace prompting, a simple yet effective approach to facilitate VLA models' spatial-temporal awareness for action prediction by encoding state-action trajectories visually. We develop a new TraceVLA model by finetuning OpenVLA on our own collected dataset of 150K robot manipulation trajectories using visual trace prompting. Evaluations of TraceVLA across 137 configurations in SimplerEnv and 4 tasks on a physical WidowX robot demonstrate state-of-the-art performance, outperforming OpenVLA by 10% on SimplerEnv and 3.5x on real-robot tasks and exhibiting robust generalization across diverse embodiments and scenarios. To further validate the effectiveness and generality of our method, we present a compact VLA model based on 4B Phi-3-Vision, pretrained on the Open-X-Embodiment and finetuned on our dataset, rivals the 7B OpenVLA baseline while significantly improving inference efficiency.
Causal Effect of Group Diversity on Redundancy and Coverage in Peer-Reviewing
Nov 18, 2024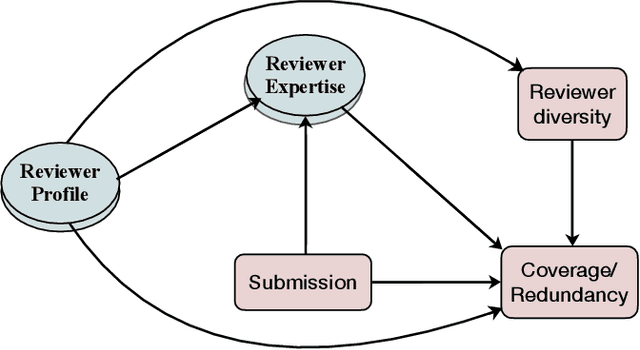

A large host of scientific journals and conferences solicit peer reviews from multiple reviewers for the same submission, aiming to gather a broader range of perspectives and mitigate individual biases. In this work, we reflect on the role of diversity in the slate of reviewers assigned to evaluate a submitted paper as a factor in diversifying perspectives and improving the utility of the peer-review process. We propose two measures for assessing review utility: review coverage -- reviews should cover most contents of the paper -- and review redundancy -- reviews should add information not already present in other reviews. We hypothesize that reviews from diverse reviewers will exhibit high coverage and low redundancy. We conduct a causal study of different measures of reviewer diversity on review coverage and redundancy using observational data from a peer-reviewed conference with approximately 5,000 submitted papers. Our study reveals disparate effects of different diversity measures on review coverage and redundancy. Our study finds that assigning a group of reviewers that are topically diverse, have different seniority levels, or have distinct publication networks leads to broader coverage of the paper or review criteria, but we find no evidence of an increase in coverage for reviewer slates with reviewers from diverse organizations or geographical locations. Reviewers from different organizations, seniority levels, topics, or publications networks (all except geographical diversity) lead to a decrease in redundancy in reviews. Furthermore, publication network-based diversity alone also helps bring in varying perspectives (that is, low redundancy), even within specific review criteria. Our study adopts a group decision-making perspective for reviewer assignments in peer review and suggests dimensions of diversity that can help guide the reviewer assignment process.