 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Heterogeneous Ensemble for Multi-Center COVID-19 Classification from Chest CT Scans
Mar 15, 2026The COVID-19 pandemic exposed critical limitations in diagnostic workflows: RT-PCR tests suffer from slow turnaround times and high false-negative rates, while CT-based screening offers faster complementary diagnosis but requires expert radiological interpretation. Deploying automated CT analysis across multiple hospital centres introduces further challenges, as differences in scanner hardware, acquisition protocols, and patient populations cause substantial domain shift that degrades single-model performance. To address these challenges, we present a heterogeneous ensemble of nine models spanning three inference paradigms: (1) a self-supervised DINOv2 Vision Transformer with slice-level sigmoid aggregation, (2) a RadImageNet-pretrained DenseNet-121 with slice-level sigmoid averaging, and (3) seven Gated Attention Multiple Instance Learning models using EfficientNet-B3, ConvNeXt-Tiny, and EfficientNetV2-S backbones with scan-level softmax classification. Ensemble diversity is further enhanced through random-seed variation and Stochastic Weight Averaging. We address severe overfitting, reducing the validation-to-training loss ratio from 35x to less than 3x, through a combination of Focal Loss, embedding-level Mixup, and domain-aware augmentation. Model outputs are fused via score-weighted probability averaging and calibrated with per-source threshold optimization. The final ensemble achieves an average macro F1 of 0.9280 across four hospital centres, outperforming the best single model (F1=0.8969) by +0.031, demonstrating that heterogeneous architectures combined with source-aware calibration are essential for robust multi-site medical image classification.
Bringing together invertible UNets with invertible attention modules for memory-efficient diffusion models
Apr 15, 2025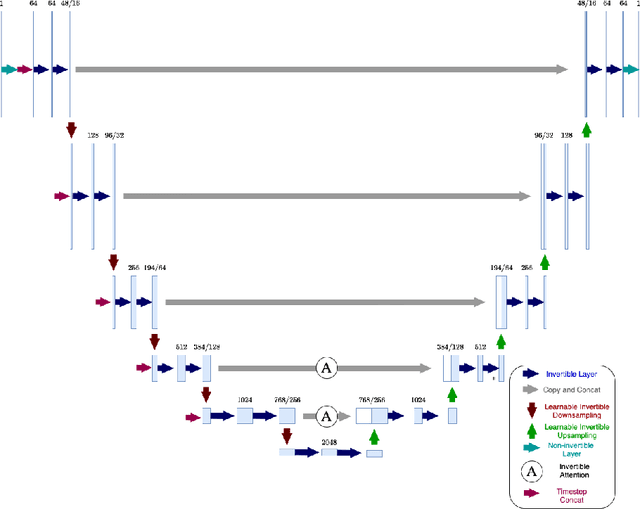
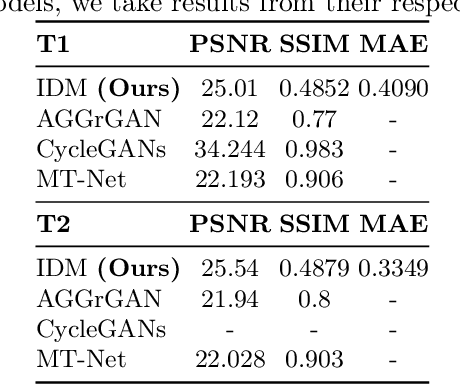
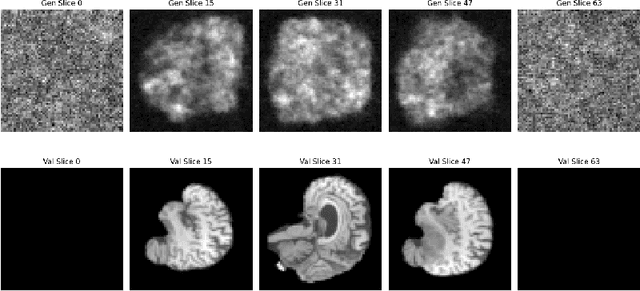
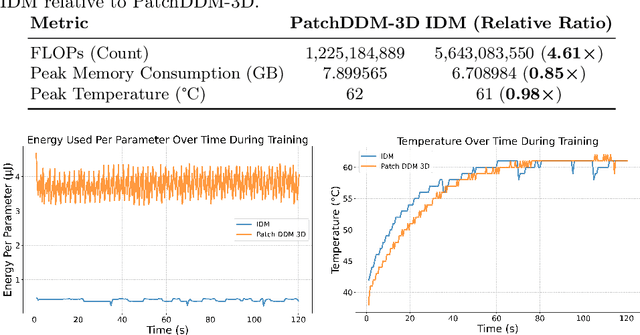
Diffusion models have recently gained state of the art performance on many image generation tasks. However, most models require significant computational resources to achieve this. This becomes apparent in the application of medical image synthesis due to the 3D nature of medical datasets like CT-scans, MRIs, electron microscope, etc. In this paper we propose a novel architecture for a single GPU memory-efficient training for diffusion models for high dimensional medical datasets. The proposed model is built by using an invertible UNet architecture with invertible attention modules. This leads to the following two contributions: 1. denoising diffusion models and thus enabling memory usage to be independent of the dimensionality of the dataset, and 2. reducing the energy usage during training. While this new model can be applied to a multitude of image generation tasks, we showcase its memory-efficiency on the 3D BraTS2020 dataset leading to up to 15\% decrease in peak memory consumption during training with comparable results to SOTA while maintaining the image quality.
My LLM might Mimic AAE -- But When Should it?
Feb 06, 2025
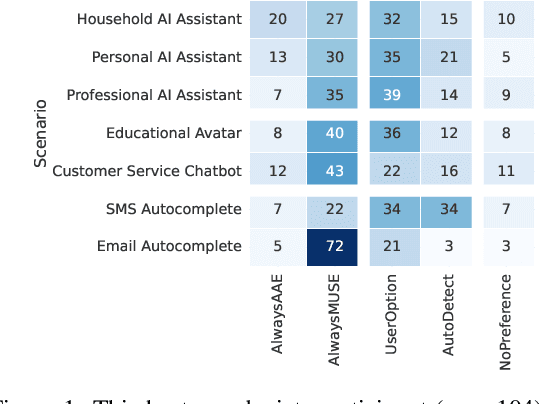


We examine the representation of African American English (AAE) in large language models (LLMs), exploring (a) the perceptions Black Americans have of how effective these technologies are at producing authentic AAE, and (b) in what contexts Black Americans find this desirable. Through both a survey of Black Americans ($n=$ 104) and annotation of LLM-produced AAE by Black Americans ($n=$ 228), we find that Black Americans favor choice and autonomy in determining when AAE is appropriate in LLM output. They tend to prefer that LLMs default to communicating in Mainstream U.S. English in formal settings, with greater interest in AAE production in less formal settings. When LLMs were appropriately prompted and provided in context examples, our participants found their outputs to have a level of AAE authenticity on par with transcripts of Black American speech. Select code and data for our project can be found here: https://github.com/smelliecat/AAEMime.git
Improving Deep Generative Models on Many-To-One Image-to-Image Translation
Feb 22, 2024



Deep generative models have been applied to multiple applications in image-to-image translation. Generative Adversarial Networks and Diffusion Models have presented impressive results, setting new state-of-the-art results on these tasks. Most methods have symmetric setups across the different domains in a dataset. These methods assume that all domains have either multiple modalities or only one modality. However, there are many datasets that have a many-to-one relationship between two domains. In this work, we first introduce a Colorized MNIST dataset and a Color-Recall score that can provide a simple benchmark for evaluating models on many-to-one translation. We then introduce a new asymmetric framework to improve existing deep generative models on many-to-one image-to-image translation. We apply this framework to StarGAN V2 and show that in both unsupervised and semi-supervised settings, the performance of this new model improves on many-to-one image-to-image translation.
Birds' Eye View: Measuring Behavior and Posture of Chickens as a Metric for Their Well-Being
Apr 29, 2022
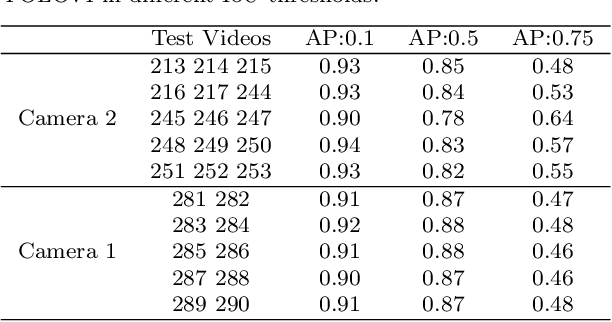

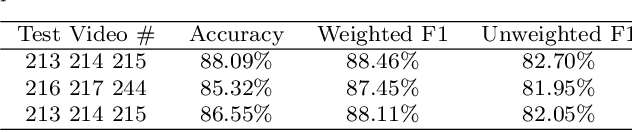
Chicken well-being is important for ensuring food security and better nutrition for a growing global human population. In this research, we represent behavior and posture as a metric to measure chicken well-being. With the objective of detecting chicken posture and behavior in a pen, we employ two algorithms: Mask R-CNN for instance segmentation and YOLOv4 in combination with ResNet50 for classification. Our results indicate a weighted F1 score of 88.46% for posture and behavior detection using Mask R-CNN and an average of 91% accuracy in behavior detection and 86.5% average accuracy in posture detection using YOLOv4. These experiments are conducted under uncontrolled scenarios for both posture and behavior measurements. These metrics establish a strong foundation to obtain a decent indication of individual and group behaviors and postures. Such outcomes would help improve the overall well-being of the chickens. The dataset used in this research is collected in-house and will be made public after the publication as it would serve as a very useful resource for future research. To the best of our knowledge no other research work has been conducted in this specific setup used for this work involving multiple behaviors and postures simultaneously.
Comparison and Analysis of Image-to-Image Generative Adversarial Networks: A Survey
Dec 23, 2021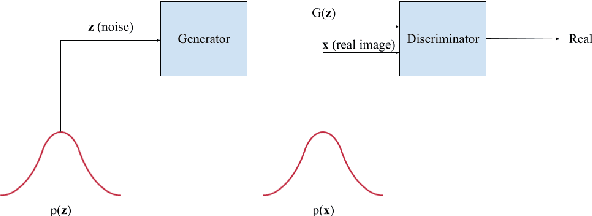
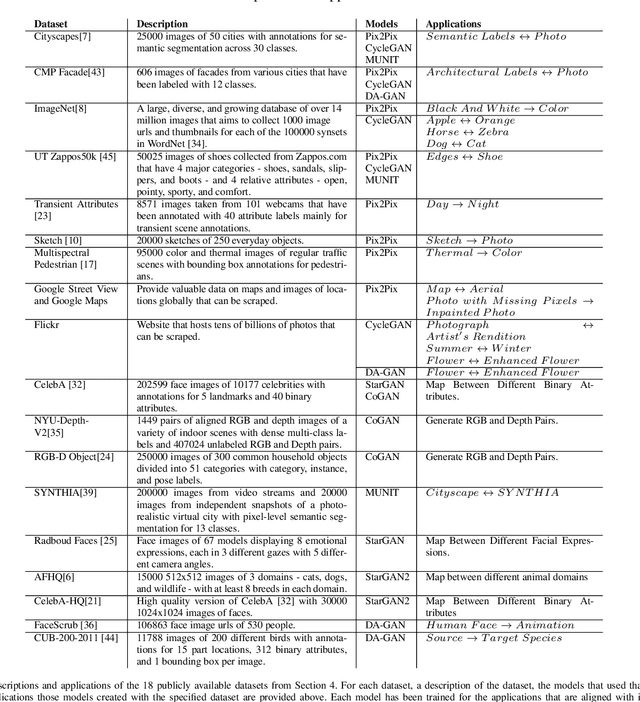
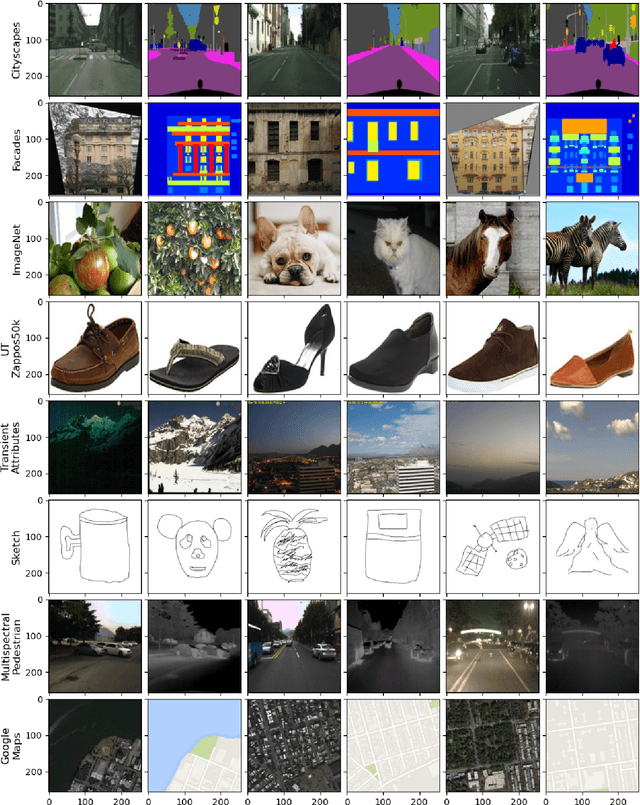
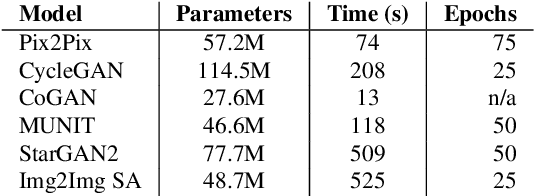
Generative Adversarial Networks (GANs) have recently introduced effective methods of performing Image-to-Image translations. These models can be applied and generalized to a variety of domains in Image-to-Image translation without changing any parameters. In this paper, we survey and analyze eight Image-to-Image Generative Adversarial Networks: Pix2Px, CycleGAN, CoGAN, StarGAN, MUNIT, StarGAN2, DA-GAN, and Self Attention GAN. Each of these models presented state-of-the-art results and introduced new techniques to build Image-to-Image GANs. In addition to a survey of the models, we also survey the 18 datasets they were trained on and the 9 metrics they were evaluated on. Finally, we present results of a controlled experiment for 6 of these models on a common set of metrics and datasets. The results were mixed and showed that on certain datasets, tasks, and metrics some models outperformed others. The last section of this paper discusses those results and establishes areas of future research. As researchers continue to innovate new Image-to-Image GANs, it is important that they gain a good understanding of the existing methods, datasets, and metrics. This paper provides a comprehensive overview and discussion to help build this foundation.
TeliNet: Classifying CT scan images for COVID-19 diagnosis
Aug 17, 2021
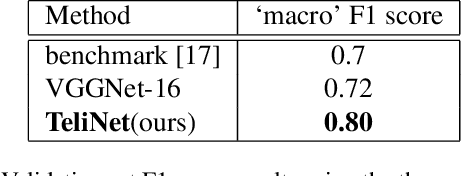

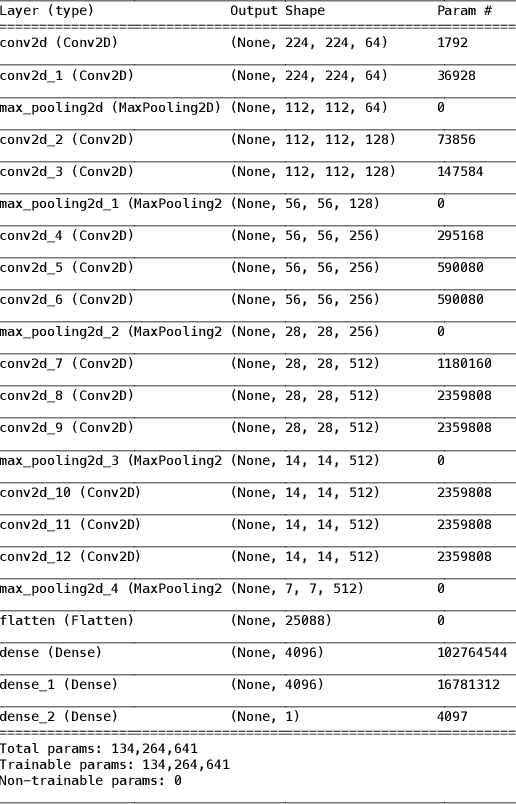
COVID-19 has led to hundreds of millions of cases and millions of deaths worldwide since its onset. The fight against this pandemic is on-going on multiple fronts. While vaccinations are picking up speed, there are still billions of unvaccinated people. In this fight against the virus, diagnosis of the disease and isolation of the patients to prevent any spread play a huge role. Machine Learning approaches have assisted in the diagnosis of COVID-19 cases by analyzing chest X-rays and CT-scan images of patients. To push algorithm development and research in this direction of radiological diagnosis, a challenge to classify CT-scan series was organized in conjunction with ICCV, 2021. In this research we present a simple and shallow Convolutional Neural Network based approach, TeliNet, to classify these CT-scan images of COVID-19 patients presented as part of this competition. Our results outperform the F1 `macro' score of the competition benchmark and VGGNet approaches. Our proposed solution is also more lightweight in comparison to the other methods.
* 7 pages, 4 figures, ICCVW
Resilience of Autonomous Vehicle Object Category Detection to Universal Adversarial Perturbations
Jul 10, 2021

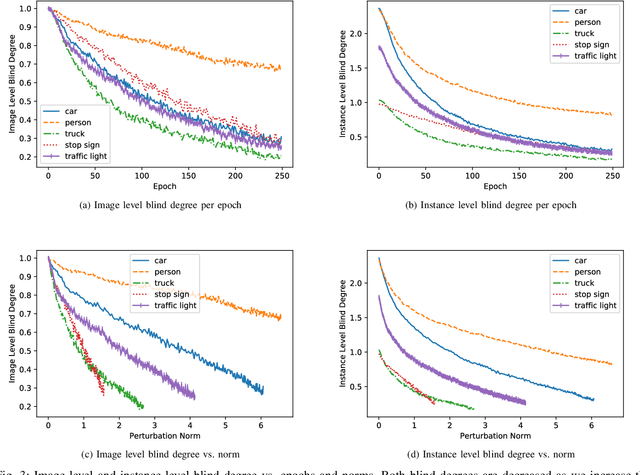
Due to the vulnerability of deep neural networks to adversarial examples, numerous works on adversarial attacks and defenses have been burgeoning over the past several years. However, there seem to be some conventional views regarding adversarial attacks and object detection approaches that most researchers take for granted. In this work, we bring a fresh perspective on those procedures by evaluating the impact of universal perturbations on object detection at a class-level. We apply it to a carefully curated data set related to autonomous driving. We use Faster-RCNN object detector on images of five different categories: person, car, truck, stop sign and traffic light from the COCO data set, while carefully perturbing the images using Universal Dense Object Suppression algorithm. Our results indicate that person, car, traffic light, truck and stop sign are resilient in that order (most to least) to universal perturbations. To the best of our knowledge, this is the first time such a ranking has been established which is significant for the security of the data sets pertaining to autonomous vehicles and object detection in general.
Face Detection in Repeated Settings
Mar 20, 2019
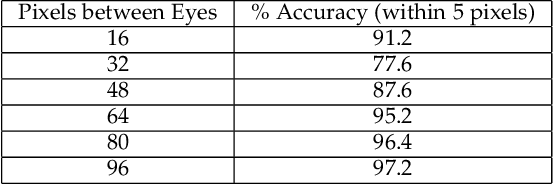

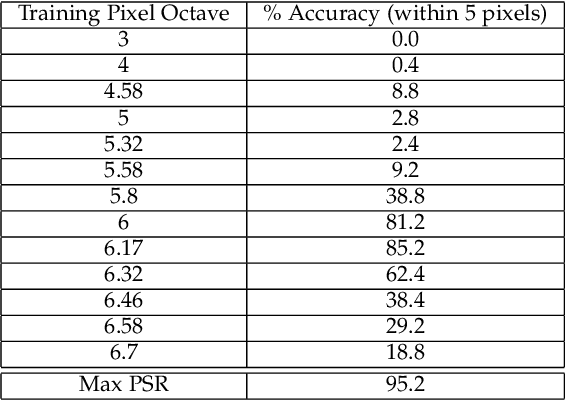
Face detection is an important first step before face verification and recognition. In unconstrained settings it is still an open challenge because of the variation in pose, lighting, scale, background and location. However, for the purposes of verification we can have a control on background and location. Images are primarily captured in places such as the entrance to a sensitive building, in front of a door or some location where the background does not change. We present a correlation based face detection algorithm to detect faces in such settings, where we control the location, and leave lighting, pose, and scale uncontrolled. In these scenarios the results indicate that our algorithm is easy and fast to train, outperforms Viola and Jones face detection accuracy and is faster to test.