 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEFT: Detection Embeddings for Tracking
Feb 03, 2021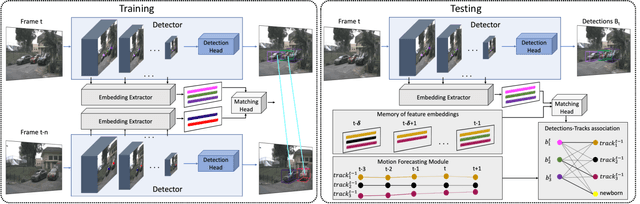
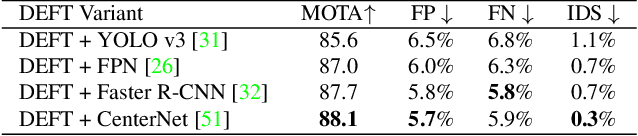

Most modern multiple object tracking (MOT) systems follow the tracking-by-detection paradigm, consisting of a detector followed by a method for associating detections into tracks. There is a long history in tracking of combining motion and appearance features to provide robustness to occlusions and other challenges, but typically this comes with the trade-off of a more complex and slower implementation. Recent successes on popular 2D tracking benchmarks indicate that top-scores can be achieved using a state-of-the-art detector and relatively simple associations relying on single-frame spatial offsets -- notably outperforming contemporary methods that leverage learned appearance features to help re-identify lost tracks. In this paper, we propose an efficient joint detection and tracking model named DEFT, or "Detection Embeddings for Tracking." Our approach relies on an appearance-based object matching network jointly-learned with an underlying object detection network. An LSTM is also added to capture motion constraints. DEFT has comparable accuracy and speed to the top methods on 2D online tracking leaderboards while having significant advantages in robustness when applied to more challenging tracking data. DEFT raises the bar on the nuScenes monocular 3D tracking challenge, more than doubling the performance of the previous top method. Code is publicly available.
Face Detection in Repeated Settings
Mar 20, 2019
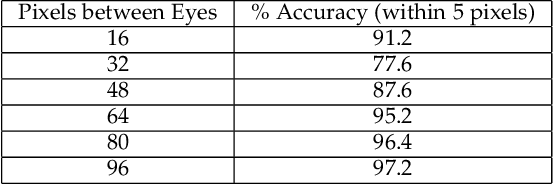

Face detection is an important first step before face verification and recognition. In unconstrained settings it is still an open challenge because of the variation in pose, lighting, scale, background and location. However, for the purposes of verification we can have a control on background and location. Images are primarily captured in places such as the entrance to a sensitive building, in front of a door or some location where the background does not change. We present a correlation based face detection algorithm to detect faces in such settings, where we control the location, and leave lighting, pose, and scale uncontrolled. In these scenarios the results indicate that our algorithm is easy and fast to train, outperforms Viola and Jones face detection accuracy and is faster to test.