 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes Good Multilingual Reasoning? Disentangling Reasoning Traces with Measurable Features
Apr 06, 2026Large Reasoning Models (LRMs) still exhibit large performance gaps between English and other languages, yet much current work assumes these gaps can be closed simply by making reasoning in every language resemble English reasoning. This work challenges this assumption by asking instead: what actually characterizes effective reasoning in multilingual settings, and to what extent do English-derived reasoning features genuinely help in other languages? We first define a suite of measurable reasoning features spanning multilingual alignment, reasoning step, and reasoning flow aspects of reasoning traces, and use logistic regression to quantify how each feature associates with final answer accuracy. We further train sparse autoencoders over multilingual traces to automatically discover latent reasoning concepts that instantiate or extend these features. Finally, we use the features as test-time selection policies to examine whether they can steer models toward stronger multilingual reasoning. Across two mathematical reasoning benchmarks, four LRMs, and 10 languages, we find that most features are positively associated with accuracy, but the strength of association varies considerably across languages and can even reverse in some. Our findings challenge English-centric reward designs and point toward adaptive objectives that accommodate language-specific reasoning patterns, with concrete implications for multilingual benchmark and reward design.
Data Kernel Perspective Space Performance Guarantees for Synthetic Data from Transformer Models
Feb 04, 2026Scarcity of labeled training data remains the long pole in the tent for building performant language technology and generative AI models. Transformer models -- particularly LLMs -- are increasingly being used to mitigate the data scarcity problem via synthetic data generation. However, because the models are black boxes, the properties of the synthetic data are difficult to predict. In practice it is common for language technology engineers to 'fiddle' with the LLM temperature setting and hope that what comes out the other end improves the downstream model. Faced with this uncertainty, here we propose Data Kernel Perspective Space (DKPS) to provide the foundation for mathematical analysis yielding concrete statistical guarantees for the quality of the outputs of transformer models. We first show the mathematical derivation of DKPS and how it provides performance guarantees. Next we show how DKPS performance guarantees can elucidate performance of a downstream task, such as neural machine translation models or LLMs trained using Contrastive Preference Optimization (CPO). Limitations of the current work and future research are also discussed.
FACTUM: Mechanistic Detection of Citation Hallucination in Long-Form RAG
Jan 09, 2026Retrieval-Augmented Generation (RAG) models are critically undermined by citation hallucinations, a deceptive failure where a model confidently cites a source that fails to support its claim. Existing work often attributes hallucination to a simple over-reliance on the model's parametric knowledge. We challenge this view and introduce FACTUM (Framework for Attesting Citation Trustworthiness via Underlying Mechanisms), a framework of four mechanistic scores measuring the distinct contributions of a model's attention and FFN pathways, and the alignment between them. Our analysis reveals two consistent signatures of correct citation: a significantly stronger contribution from the model's parametric knowledge and greater use of the attention sink for information synthesis. Crucially, we find the signature of a correct citation is not static but evolves with model scale. For example, the signature of a correct citation for the Llama-3.2-3B model is marked by higher pathway alignment, whereas for the Llama-3.1-8B model, it is characterized by lower alignment, where pathways contribute more distinct, orthogonal information. By capturing this complex, evolving signature, FACTUM outperforms state-of-the-art baselines by up to 37.5% in AUC. Our findings reframe citation hallucination as a complex, scale-dependent interplay between internal mechanisms, paving the way for more nuanced and reliable RAG systems.
Linguistic Nepotism: Trading-off Quality for Language Preference in Multilingual RAG
Sep 17, 2025Multilingual Retrieval-Augmented Generation (mRAG) systems enable language models to answer knowledge-intensive queries with citation-supported responses across languages. While such systems have been proposed, an open questions is whether the mixture of different document languages impacts generation and citation in unintended ways. To investigate, we introduce a controlled methodology using model internals to measure language preference while holding other factors such as document relevance constant. Across eight languages and six open-weight models, we find that models preferentially cite English sources when queries are in English, with this bias amplified for lower-resource languages and for documents positioned mid-context. Crucially, we find that models sometimes trade-off document relevance for language preference, indicating that citation choices are not always driven by informativeness alone. Our findings shed light on how language models leverage multilingual context and influence citation behavior.
Scalable Controllable Accented TTS
Aug 10, 2025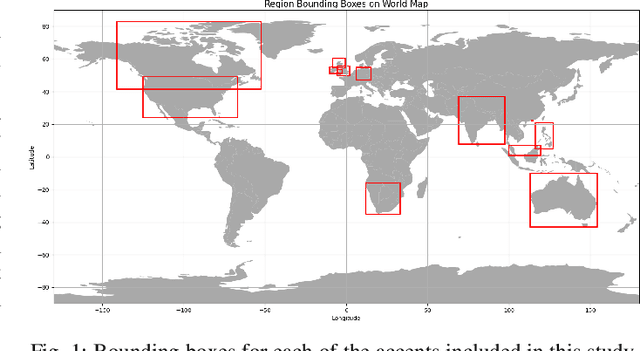
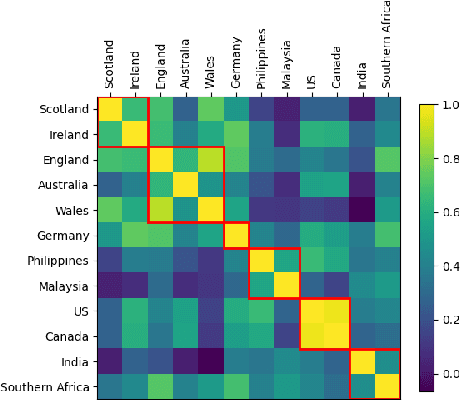
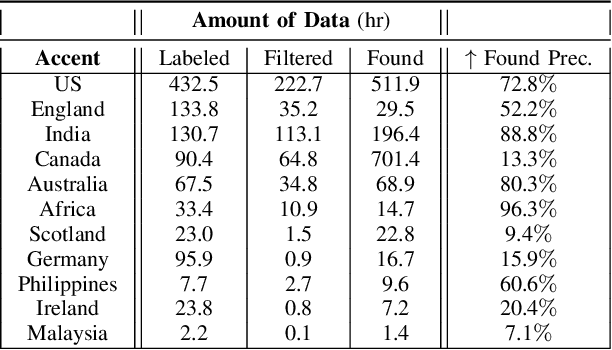

We tackle the challenge of scaling accented TTS systems, expanding their capabilities to include much larger amounts of training data and a wider variety of accent labels, even for accents that are poorly represented or unlabeled in traditional TTS datasets. To achieve this, we employ two strategies: 1. Accent label discovery via a speech geolocation model, which automatically infers accent labels from raw speech data without relying solely on human annotation; 2. Timbre augmentation through kNN voice conversion to increase data diversity and model robustness. These strategies are validated on CommonVoice, where we fine-tune XTTS-v2 for accented TTS with accent labels discovered or enhanced using geolocation. We demonstrate that the resulting accented TTS model not only outperforms XTTS-v2 fine-tuned on self-reported accent labels in CommonVoice, but also existing accented TTS benchmarks.
An Interdisciplinary Approach to Human-Centered Machine Translation
Jun 16, 2025Machine Translation (MT) tools are widely used today, often in contexts where professional translators are not present. Despite progress in MT technology, a gap persists between system development and real-world usage, particularly for non-expert users who may struggle to assess translation reliability. This paper advocates for a human-centered approach to MT, emphasizing the alignment of system design with diverse communicative goals and contexts of use. We survey the literature in Translation Studies and Human-Computer Interaction to recontextualize MT evaluation and design to address the diverse real-world scenarios in which MT is used today.
Should I Share this Translation? Evaluating Quality Feedback for User Reliance on Machine Translation
May 30, 2025As people increasingly use AI systems in work and daily life, feedback mechanisms that help them use AI responsibly are urgently needed, particularly in settings where users are not equipped to assess the quality of AI predictions. We study a realistic Machine Translation (MT) scenario where monolingual users decide whether to share an MT output, first without and then with quality feedback. We compare four types of quality feedback: explicit feedback that directly give users an assessment of translation quality using 1) error highlights and 2) LLM explanations, and implicit feedback that helps users compare MT inputs and outputs through 3) backtranslation and 4) question-answer (QA) tables. We find that all feedback types, except error highlights, significantly improve both decision accuracy and appropriate reliance. Notably, implicit feedback, especially QA tables, yields significantly greater gains than explicit feedback in terms of decision accuracy, appropriate reliance, and user perceptions, receiving the highest ratings for helpfulness and trust, and the lowest for mental burden.
AskQE: Question Answering as Automatic Evaluation for Machine Translation
Apr 15, 2025How can a monolingual English speaker determine whether an automatic translation in French is good enough to be shared? Existing MT error detection and quality estimation (QE) techniques do not address this practical scenario. We introduce AskQE, a question generation and answering framework designed to detect critical MT errors and provide actionable feedback, helping users decide whether to accept or reject MT outputs even without the knowledge of the target language. Using ContraTICO, a dataset of contrastive synthetic MT errors in the COVID-19 domain, we explore design choices for AskQE and develop an optimized version relying on LLaMA-3 70B and entailed facts to guide question generation. We evaluate the resulting system on the BioMQM dataset of naturally occurring MT errors, where AskQE has higher Kendall's Tau correlation and decision accuracy with human ratings compared to other QE metrics.
Uncertainty Distillation: Teaching Language Models to Express Semantic Confidence
Mar 18, 2025

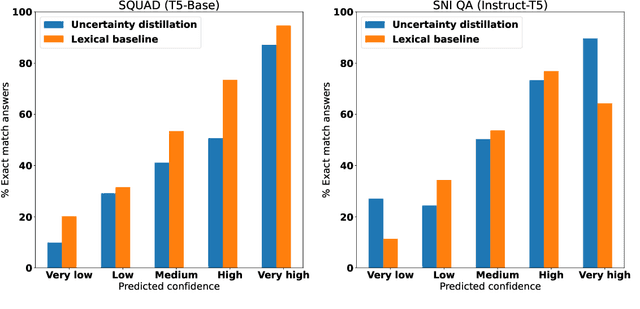

As large language models (LLMs) are increasingly used for factual question-answering, it becomes more important for LLMs to have the capability to communicate the likelihood that their answer is correct. For these verbalized expressions of uncertainty to be meaningful, they should reflect the error rates at the expressed level of confidence. However, when prompted to express confidence, the error rates of current LLMs are inconsistent with their communicated confidences, highlighting the need for uncertainty quantification methods. Many prior methods calculate lexical uncertainty, estimating a model's confidence in the specific string it generated. In some cases, however, it may be more useful to estimate semantic uncertainty, or the model's confidence in the answer regardless of how it is verbalized. We propose a simple procedure, uncertainty distillation, to teach an LLM to verbalize calibrated semantic confidences. Using held-out data to map initial uncertainty estimates to meaningful probabilities, we create examples annotated with verbalized probabilities for supervised fine-tuning. We demonstrate our method yields verbalized confidences that correlate with observed error rates with a small fine-tuned language model as well as with larger instruction-tuned models, and find that our semantic uncertainty correlates well with lexical uncertainty on short answers.
Less is More for Synthetic Speech Detection in the Wild
Feb 08, 2025



Driven by advances in self-supervised learning for speech, state-of-the-art synthetic speech detectors have achieved low error rates on popular benchmarks such as ASVspoof. However, prior benchmarks do not address the wide range of real-world variability in speech. Are reported error rates realistic in real-world conditions? To assess detector failure modes and robustness under controlled distribution shifts, we introduce ShiftySpeech, a benchmark with more than 3000 hours of synthetic speech from 7 domains, 6 TTS systems, 12 vocoders, and 3 languages. We found that all distribution shifts degraded model performance, and contrary to prior findings, training on more vocoders, speakers, or with data augmentation did not guarantee better generalization. In fact, we found that training on less diverse data resulted in better generalization, and that a detector fit using samples from a single carefully selected vocoder and a single speaker achieved state-of-the-art results on the challenging In-the-Wild benchmark.