 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Distillation: Teaching Language Models to Express Semantic Confidence
Mar 18, 2025

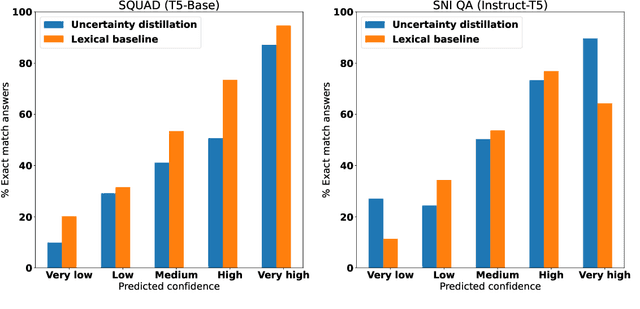

As large language models (LLMs) are increasingly used for factual question-answering, it becomes more important for LLMs to have the capability to communicate the likelihood that their answer is correct. For these verbalized expressions of uncertainty to be meaningful, they should reflect the error rates at the expressed level of confidence. However, when prompted to express confidence, the error rates of current LLMs are inconsistent with their communicated confidences, highlighting the need for uncertainty quantification methods. Many prior methods calculate lexical uncertainty, estimating a model's confidence in the specific string it generated. In some cases, however, it may be more useful to estimate semantic uncertainty, or the model's confidence in the answer regardless of how it is verbalized. We propose a simple procedure, uncertainty distillation, to teach an LLM to verbalize calibrated semantic confidences. Using held-out data to map initial uncertainty estimates to meaningful probabilities, we create examples annotated with verbalized probabilities for supervised fine-tuning. We demonstrate our method yields verbalized confidences that correlate with observed error rates with a small fine-tuned language model as well as with larger instruction-tuned models, and find that our semantic uncertainty correlates well with lexical uncertainty on short answers.
Can Optimization Trajectories Explain Multi-Task Transfer?
Aug 26, 2024Despite the widespread adoption of multi-task training in deep learning, little is understood about how multi-task learning (MTL) affects generalization. Prior work has conjectured that the negative effects of MTL are due to optimization challenges that arise during training, and many optimization methods have been proposed to improve multi-task performance. However, recent work has shown that these methods fail to consistently improve multi-task generalization. In this work, we seek to improve our understanding of these failures by empirically studying how MTL impacts the optimization of tasks, and whether this impact can explain the effects of MTL on generalization. We show that MTL results in a generalization gap-a gap in generalization at comparable training loss-between single-task and multi-task trajectories early into training. However, we find that factors of the optimization trajectory previously proposed to explain generalization gaps in single-task settings cannot explain the generalization gaps between single-task and multi-task models. Moreover, we show that the amount of gradient conflict between tasks is correlated with negative effects to task optimization, but is not predictive of generalization. Our work sheds light on the underlying causes for failures in MTL and, importantly, raises questions about the role of general purpose multi-task optimization algorithms.
Where does In-context Translation Happen in Large Language Models
Mar 07, 2024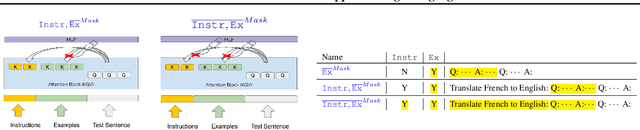

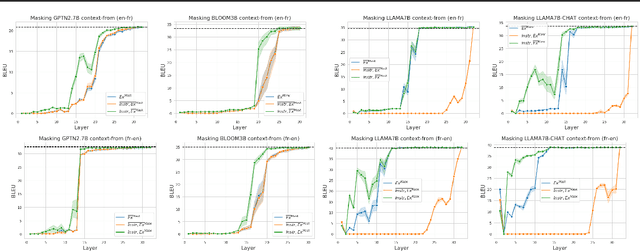

Self-supervised large language models have demonstrated the ability to perform Machine Translation (MT) via in-context learning, but little is known about where the model performs the task with respect to prompt instructions and demonstration examples. In this work, we attempt to characterize the region where large language models transition from in-context learners to translation models. Through a series of layer-wise context-masking experiments on \textsc{GPTNeo2.7B}, \textsc{Bloom3B}, \textsc{Llama7b} and \textsc{Llama7b-chat}, we demonstrate evidence of a "task recognition" point where the translation task is encoded into the input representations and attention to context is no longer necessary. We further observe correspondence between the low performance when masking out entire layers, and the task recognition layers. Taking advantage of this redundancy results in 45\% computational savings when prompting with 5 examples, and task recognition achieved at layer 14 / 32. Our layer-wise fine-tuning experiments indicate that the most effective layers for MT fine-tuning are the layers critical to task recognition.
Do Text-to-Text Multi-Task Learners Suffer from Task Conflict?
Dec 13, 2022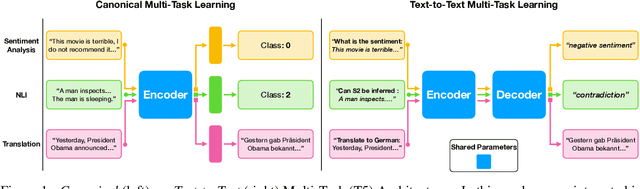
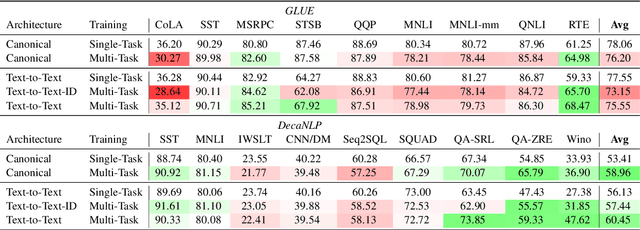
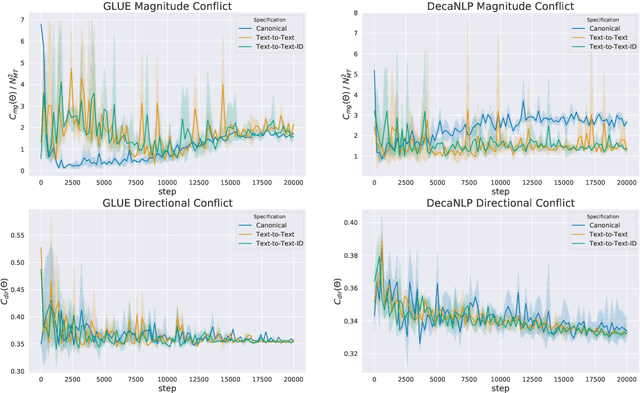

Traditional multi-task learning architectures train a single model across multiple tasks through a shared encoder followed by task-specific decoders. Learning these models often requires specialized training algorithms that address task-conflict in the shared parameter updates, which otherwise can lead to negative transfer. A new type of multi-task learning within NLP homogenizes multi-task architectures as a shared encoder and language model decoder, which does surprisingly well across a range of diverse tasks. Does this new architecture suffer from task-conflicts that require specialized training algorithms? We study how certain factors in the shift towards text-to-text models affects multi-task conflict and negative transfer, finding that both directional conflict and transfer are surprisingly constant across architectures.
Ensemble Distillation for Structured Prediction: Calibrated, Accurate, Fast---Choose Three
Oct 13, 2020



Modern neural networks do not always produce well-calibrated predictions, even when trained with a proper scoring function such as cross-entropy. In classification settings, simple methods such as isotonic regression or temperature scaling may be used in conjunction with a held-out dataset to calibrate model outputs. However, extending these methods to structured prediction is not always straightforward or effective; furthermore, a held-out calibration set may not always be available. In this paper, we study ensemble distillation as a general framework for producing well-calibrated structured prediction models while avoiding the prohibitive inference-time cost of ensembles. We validate this framework on two tasks: named-entity recognition and machine translation. We find that, across both tasks, ensemble distillation produces models which retain much of, and occasionally improve upon, the performance and calibration benefits of ensembles, while only requiring a single model during test-time.
Sources of Transfer in Multilingual Named Entity Recognition
May 02, 2020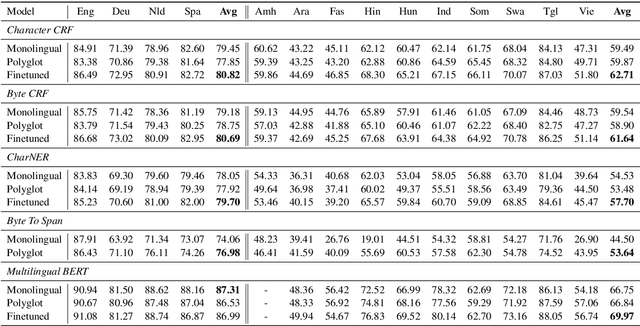
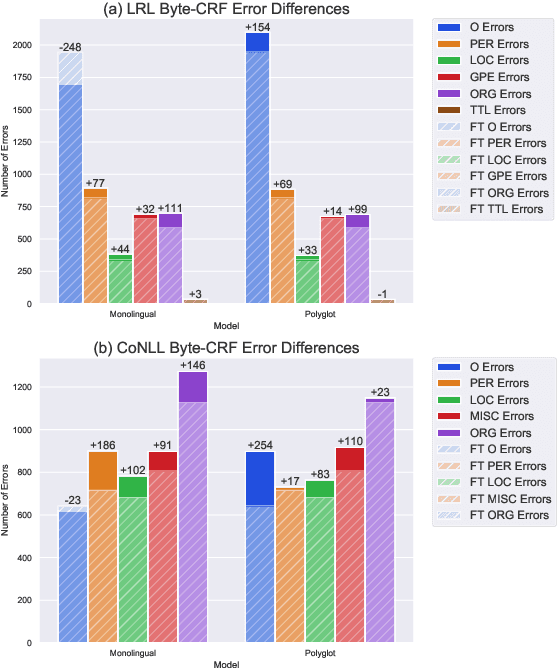
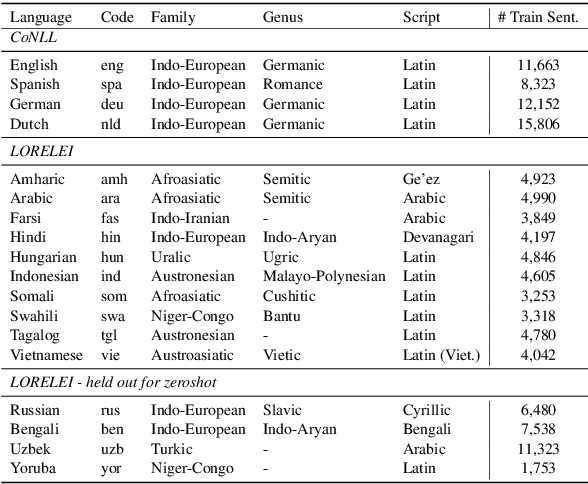

Named-entities are inherently multilingual, and annotations in any given language may be limited. This motivates us to consider polyglot named-entity recognition (NER), where one model is trained using annotated data drawn from more than one language. However, a straightforward implementation of this simple idea does not always work in practice: naive training of NER models using annotated data drawn from multiple languages consistently underperforms models trained on monolingual data alone, despite having access to more training data. The starting point of this paper is a simple solution to this problem, in which polyglot models are fine-tuned on monolingual data to consistently and significantly outperform their monolingual counterparts. To explain this phenomena, we explore the sources of multilingual transfer in polyglot NER models and examine the weight structure of polyglot models compared to their monolingual counterparts. We find that polyglot models efficiently share many parameters across languages and that fine-tuning may utilize a large number of those parameters.