 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Distillation: Teaching Language Models to Express Semantic Confidence
Paper and Code
Mar 18, 2025

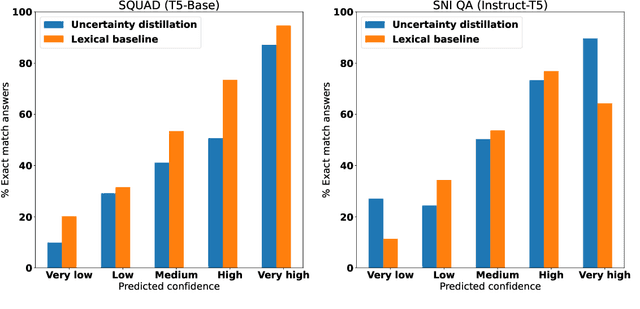

As large language models (LLMs) are increasingly used for factual question-answering, it becomes more important for LLMs to have the capability to communicate the likelihood that their answer is correct. For these verbalized expressions of uncertainty to be meaningful, they should reflect the error rates at the expressed level of confidence. However, when prompted to express confidence, the error rates of current LLMs are inconsistent with their communicated confidences, highlighting the need for uncertainty quantification methods. Many prior methods calculate lexical uncertainty, estimating a model's confidence in the specific string it generated. In some cases, however, it may be more useful to estimate semantic uncertainty, or the model's confidence in the answer regardless of how it is verbalized. We propose a simple procedure, uncertainty distillation, to teach an LLM to verbalize calibrated semantic confidences. Using held-out data to map initial uncertainty estimates to meaningful probabilities, we create examples annotated with verbalized probabilities for supervised fine-tuning. We demonstrate our method yields verbalized confidences that correlate with observed error rates with a small fine-tuned language model as well as with larger instruction-tuned models, and find that our semantic uncertainty correlates well with lexical uncertainty on short answers.