 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInducing Artificial Uncertainty in Language Models
May 13, 2026In safety-critical applications, language models should be able to characterize their uncertainty with meaningful probabilities. Many uncertainty quantification approaches require supervised data; however, finding suitable unseen challenging data is increasingly difficult for large language models trained on vast amounts of scraped data. If the model is consistently (and correctly) confident in its predictions, the uncertainty quantification method may consistently overestimate confidence on new and unfamiliar data. Finding data which exhibits enough uncertainty to train supervised uncertainty quantification methods for high-performance models may therefore be challenging, and will increase in difficulty as LLMs saturate datasets. To address this issue, we first introduce the problem of inducing artificial uncertainty in language models, then investigate methods of inducing artificial uncertainty on trivially easy data in the absence of challenging data at training time. We use probes trained to recognize artificial uncertainty on the original model, and find that these probes trained on artificial uncertainty outperform probes trained without artificial uncertainty in recognizing real uncertainty, achieving notably higher calibration on hard data with minimal loss of performance on easy data.
ProSDD: Learning Prosodic Representations for Speech Deepfake Detection against Expressive and Emotional Attacks
Apr 14, 2026Speech deepfake detection (SDD) systems perform well on standard benchmarks datasets but often fail to generalize to expressive and emotional spoofing attacks. Many methods rely on spoof-heavy training data, learning dataset-specific artifacts rather than transferable cues of natural speech. In contrast, humans internalize variability in real speech and detect fakes as deviations from it. We introduce ProSDD, a two-stage framework that enriches model embeddings through supervised masked prediction of speaker-conditioned prosodic variation based on pitch, voice activity, and energy. Stage I learns prosodic variability from real speech, and Stage II jointly optimizes this objective with spoof classification. ProSDD consistently outperforms baselines under both ASVspoof 2019 and 2024 training, reducing ASVspoof 2024 EER from 25.43% to 16.14% (2019-trained) and from 39.62% to 7.38% (2024-trained), while achieving 50% relative reductions on EmoFake and EmoSpoof-TTS.
Integrated Spoofing-Robust Automatic Speaker Verification via a Three-Class Formulation and LLR
Mar 14, 2026Spoofing-robust automatic speaker verification (SASV) aims to integrate automatic speaker verification (ASV) and countermeasure (CM). A popular solution is fusion of independent ASV and CM scores. To better modeling SASV, some frameworks integrate ASV and CM within a single network. However, these solutions are typically bi-encoder based, offer limited interpretability, and cannot be readily adapted to new evaluation parameters without retraining. Based on this, we propose a unified end-to-end framework via a three-class formulation that enables log-likelihood ratio (LLR) inference from class logits for a more interpretable decision pipeline. Experiments show comparable performance to existing methods on ASVSpoof5 and better results on SpoofCeleb. The visualization and analysis also prove that the three-class reformulation provides more interpretability.
Can LLMs Help Localize Fake Words in Partially Fake Speech?
Mar 11, 2026Large language models (LLMs), trained on large-scale text, have recently attracted significant attention for their strong performance across many tasks. Motivated by this, we investigate whether a text-trained LLM can help localize fake words in partially fake speech, where only specific words within a speech are edited. We build a speech LLM to perform fake word localization via next token prediction. Experiments and analyses on AV-Deepfake1M and PartialEdit indicates that the model frequently leverages editing-style pattern learned from the training data, particularly word-level polarity substitutions for those two databases we discussed, as cues for localizing fake words. Although such particular patterns provide useful information in an in-domain scenario, how to avoid over-reliance on such particular pattern and improve generalization to unseen editing styles remains an open question.
Universal Speech Content Factorization
Mar 09, 2026We propose Universal Speech Content Factorization (USCF), a simple and invertible linear method for extracting a low-rank speech representation in which speaker timbre is suppressed while phonetic content is preserved. USCF extends Speech Content Factorization, a closed-set voice conversion (VC) method, to an open-set setting by learning a universal speech-to-content mapping via least-squares optimization and deriving speaker-specific transformations from only a few seconds of target speech. We show through embedding analysis that USCF effectively removes speaker-dependent variation. As a zero-shot VC system, USCF achieves competitive intelligibility, naturalness, and speaker similarity compared to methods that require substantially more target-speaker data or additional neural training. Finally, we demonstrate that as a training-efficient timbre-disentangled speech feature, USCF features can serve as the acoustic representation for training timbre-prompted text-to-speech models. Speech samples and code are publicly available.
CommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
Content Anonymization for Privacy in Long-form Audio
Oct 14, 2025Voice anonymization techniques have been found to successfully obscure a speaker's acoustic identity in short, isolated utterances in benchmarks such as the VoicePrivacy Challenge. In practice, however, utterances seldom occur in isolation: long-form audio is commonplace in domains such as interviews, phone calls, and meetings. In these cases, many utterances from the same speaker are available, which pose a significantly greater privacy risk: given multiple utterances from the same speaker, an attacker could exploit an individual's vocabulary, syntax, and turns of phrase to re-identify them, even when their voice is completely disguised. To address this risk, we propose new content anonymization approaches. Our approach performs a contextual rewriting of the transcripts in an ASR-TTS pipeline to eliminate speaker-specific style while preserving meaning. We present results in a long-form telephone conversation setting demonstrating the effectiveness of a content-based attack on voice-anonymized speech. Then we show how the proposed content-based anonymization methods can mitigate this risk while preserving speech utility. Overall, we find that paraphrasing is an effective defense against content-based attacks and recommend that stakeholders adopt this step to ensure anonymity in long-form audio.
Context-Aware Language Models for Forecasting Market Impact from Sequences of Financial News
Sep 15, 2025



Financial news plays a critical role in the information diffusion process in financial markets and is a known driver of stock prices. However, the information in each news article is not necessarily self-contained, often requiring a broader understanding of the historical news coverage for accurate interpretation. Further, identifying and incorporating the most relevant contextual information presents significant challenges. In this work, we explore the value of historical context in the ability of large language models to understand the market impact of financial news. We find that historical context provides a consistent and significant improvement in performance across methods and time horizons. To this end, we propose an efficient and effective contextualization method that uses a large LM to process the main article, while a small LM encodes the historical context into concise summary embeddings that are then aligned with the large model's representation space. We explore the behavior of the model through multiple qualitative and quantitative interpretability tests and reveal insights into the value of contextualization. Finally, we demonstrate that the value of historical context in model predictions has real-world applications, translating to substantial improvements in simulated investment performance.
Scalable Controllable Accented TTS
Aug 10, 2025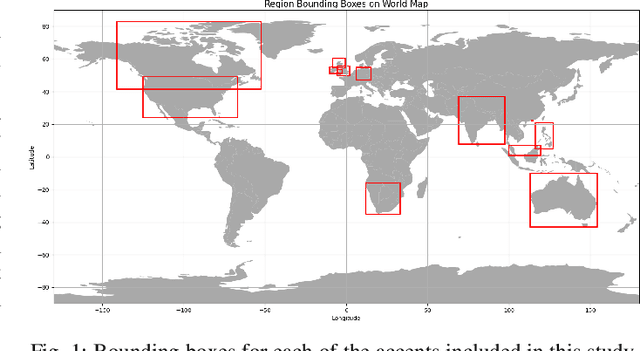
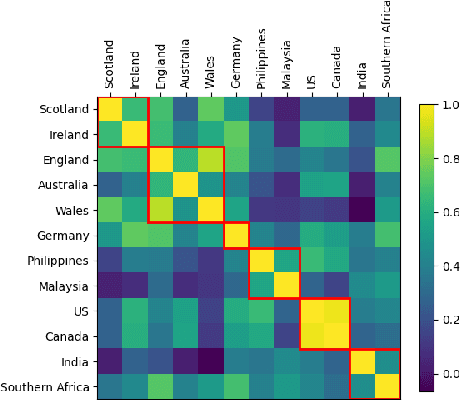
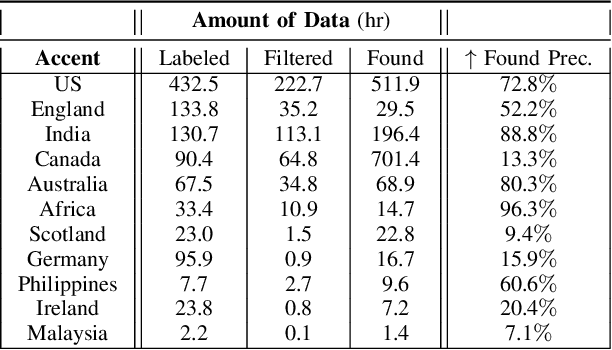

We tackle the challenge of scaling accented TTS systems, expanding their capabilities to include much larger amounts of training data and a wider variety of accent labels, even for accents that are poorly represented or unlabeled in traditional TTS datasets. To achieve this, we employ two strategies: 1. Accent label discovery via a speech geolocation model, which automatically infers accent labels from raw speech data without relying solely on human annotation; 2. Timbre augmentation through kNN voice conversion to increase data diversity and model robustness. These strategies are validated on CommonVoice, where we fine-tune XTTS-v2 for accented TTS with accent labels discovered or enhanced using geolocation. We demonstrate that the resulting accented TTS model not only outperforms XTTS-v2 fine-tuned on self-reported accent labels in CommonVoice, but also existing accented TTS benchmarks.
Feedback Friction: LLMs Struggle to Fully Incorporate External Feedback
Jun 13, 2025Recent studies have shown LLMs possess some ability to improve their responses when given external feedback. However, it remains unclear how effectively and thoroughly these models can incorporate extrinsic feedback. In an ideal scenario, if LLMs receive near-perfect and complete feedback, we would expect them to fully integrate the feedback and change their incorrect answers to correct ones. In this paper, we systematically investigate LLMs' ability to incorporate feedback by designing a controlled experimental environment. For each problem, a solver model attempts a solution, then a feedback generator with access to near-complete ground-truth answers produces targeted feedback, after which the solver tries again. We evaluate this pipeline across a diverse range of tasks, including math reasoning, knowledge reasoning, scientific reasoning, and general multi-domain evaluations with state-of-the-art language models including Claude 3.7 (with and without extended thinking). Surprisingly, even under these near-ideal conditions, solver models consistently show resistance to feedback, a limitation that we term FEEDBACK FRICTION. To mitigate this limitation, we experiment with sampling-based strategies like progressive temperature increases and explicit rejection of previously attempted incorrect answers, which yield improvements but still fail to help models achieve target performance. We also perform a rigorous exploration of potential causes of FEEDBACK FRICTION, ruling out factors such as model overconfidence and data familiarity. We hope that highlighting this issue in LLMs and ruling out several apparent causes will help future research in self-improvement.