 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Speech Content Factorization
Mar 09, 2026We propose Universal Speech Content Factorization (USCF), a simple and invertible linear method for extracting a low-rank speech representation in which speaker timbre is suppressed while phonetic content is preserved. USCF extends Speech Content Factorization, a closed-set voice conversion (VC) method, to an open-set setting by learning a universal speech-to-content mapping via least-squares optimization and deriving speaker-specific transformations from only a few seconds of target speech. We show through embedding analysis that USCF effectively removes speaker-dependent variation. As a zero-shot VC system, USCF achieves competitive intelligibility, naturalness, and speaker similarity compared to methods that require substantially more target-speaker data or additional neural training. Finally, we demonstrate that as a training-efficient timbre-disentangled speech feature, USCF features can serve as the acoustic representation for training timbre-prompted text-to-speech models. Speech samples and code are publicly available.
Scalable Controllable Accented TTS
Aug 10, 2025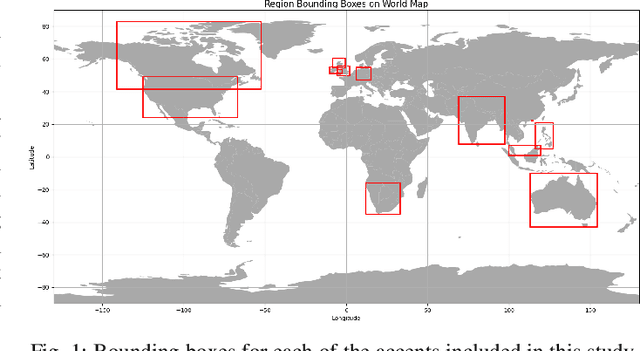
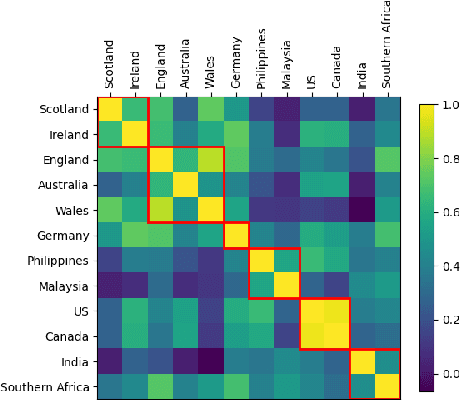
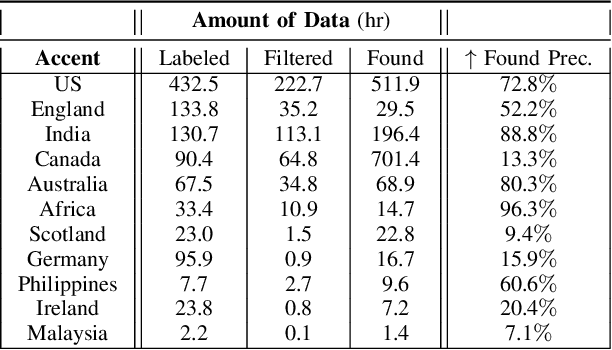

We tackle the challenge of scaling accented TTS systems, expanding their capabilities to include much larger amounts of training data and a wider variety of accent labels, even for accents that are poorly represented or unlabeled in traditional TTS datasets. To achieve this, we employ two strategies: 1. Accent label discovery via a speech geolocation model, which automatically infers accent labels from raw speech data without relying solely on human annotation; 2. Timbre augmentation through kNN voice conversion to increase data diversity and model robustness. These strategies are validated on CommonVoice, where we fine-tune XTTS-v2 for accented TTS with accent labels discovered or enhanced using geolocation. We demonstrate that the resulting accented TTS model not only outperforms XTTS-v2 fine-tuned on self-reported accent labels in CommonVoice, but also existing accented TTS benchmarks.
Less is More for Synthetic Speech Detection in the Wild
Feb 08, 2025



Driven by advances in self-supervised learning for speech, state-of-the-art synthetic speech detectors have achieved low error rates on popular benchmarks such as ASVspoof. However, prior benchmarks do not address the wide range of real-world variability in speech. Are reported error rates realistic in real-world conditions? To assess detector failure modes and robustness under controlled distribution shifts, we introduce ShiftySpeech, a benchmark with more than 3000 hours of synthetic speech from 7 domains, 6 TTS systems, 12 vocoders, and 3 languages. We found that all distribution shifts degraded model performance, and contrary to prior findings, training on more vocoders, speakers, or with data augmentation did not guarantee better generalization. In fact, we found that training on less diverse data resulted in better generalization, and that a detector fit using samples from a single carefully selected vocoder and a single speaker achieved state-of-the-art results on the challenging In-the-Wild benchmark.
GenVC: Self-Supervised Zero-Shot Voice Conversion
Feb 06, 2025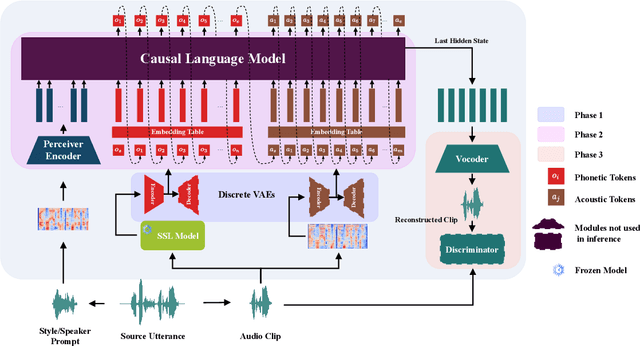
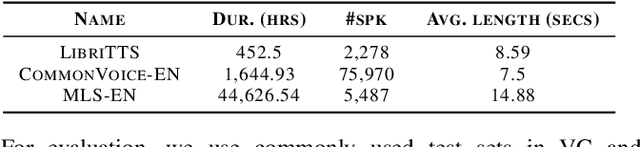
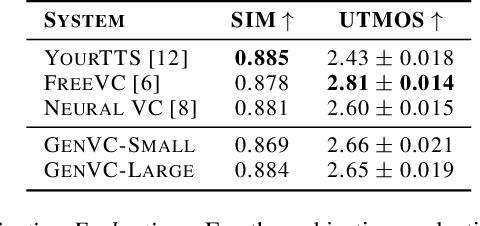
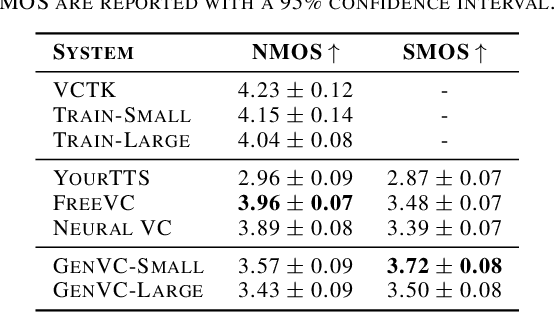
Zero-shot voice conversion has recently made substantial progress, but many models still depend on external supervised systems to disentangle speaker identity and linguistic content. Furthermore, current methods often use parallel conversion, where the converted speech inherits the source utterance's temporal structure, restricting speaker similarity and privacy. To overcome these limitations, we introduce GenVC, a generative zero-shot voice conversion model. GenVC learns to disentangle linguistic content and speaker style in a self-supervised manner, eliminating the need for external models and enabling efficient training on large, unlabeled datasets. Experimental results show that GenVC achieves state-of-the-art speaker similarity while maintaining naturalness competitive with leading approaches. Its autoregressive generation also allows the converted speech to deviate from the source utterance's temporal structure. This feature makes GenVC highly effective for voice anonymization, as it minimizes the preservation of source prosody and speaker characteristics, enhancing privacy protection.
HLTCOE JHU Submission to the Voice Privacy Challenge 2024
Sep 17, 2024



We present a number of systems for the Voice Privacy Challenge, including voice conversion based systems such as the kNN-VC method and the WavLM voice Conversion method, and text-to-speech (TTS) based systems including Whisper-VITS. We found that while voice conversion systems better preserve emotional content, they struggle to conceal speaker identity in semi-white-box attack scenarios; conversely, TTS methods perform better at anonymization and worse at emotion preservation. Finally, we propose a random admixture system which seeks to balance out the strengths and weaknesses of the two category of systems, achieving a strong EER of over 40% while maintaining UAR at a respectable 47%.
Clean Label Attacks against SLU Systems
Sep 13, 2024
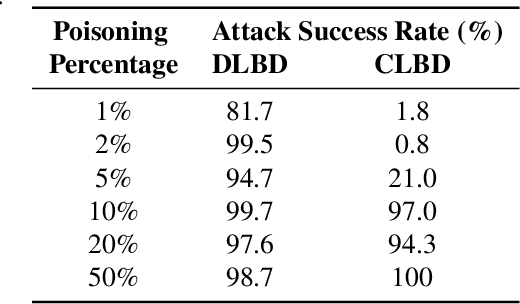

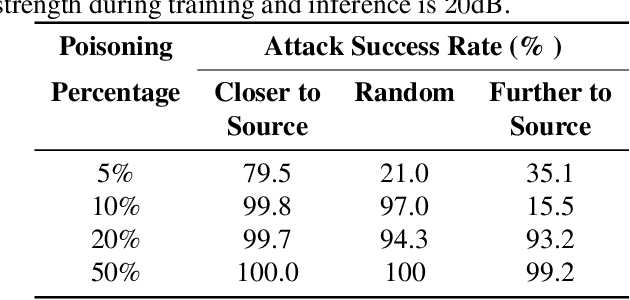
Poisoning backdoor attacks involve an adversary manipulating the training data to induce certain behaviors in the victim model by inserting a trigger in the signal at inference time. We adapted clean label backdoor (CLBD)-data poisoning attacks, which do not modify the training labels, on state-of-the-art speech recognition models that support/perform a Spoken Language Understanding task, achieving 99.8% attack success rate by poisoning 10% of the training data. We analyzed how varying the signal-strength of the poison, percent of samples poisoned, and choice of trigger impact the attack. We also found that CLBD attacks are most successful when applied to training samples that are inherently hard for a proxy model. Using this strategy, we achieved an attack success rate of 99.3% by poisoning a meager 1.5% of the training data. Finally, we applied two previously developed defenses against gradient-based attacks, and found that they attain mixed success against poisoning.
Privacy versus Emotion Preservation Trade-offs in Emotion-Preserving Speaker Anonymization
Sep 05, 2024Advances in speech technology now allow unprecedented access to personally identifiable information through speech. To protect such information, the differential privacy field has explored ways to anonymize speech while preserving its utility, including linguistic and paralinguistic aspects. However, anonymizing speech while maintaining emotional state remains challenging. We explore this problem in the context of the VoicePrivacy 2024 challenge. Specifically, we developed various speaker anonymization pipelines and find that approaches either excel at anonymization or preserving emotion state, but not both simultaneously. Achieving both would require an in-domain emotion recognizer. Additionally, we found that it is feasible to train a semi-effective speaker verification system using only emotion representations, demonstrating the challenge of separating these two modalities.
HK-LegiCoST: Leveraging Non-Verbatim Transcripts for Speech Translation
Jun 20, 2023



We introduce HK-LegiCoST, a new three-way parallel corpus of Cantonese-English translations, containing 600+ hours of Cantonese audio, its standard traditional Chinese transcript, and English translation, segmented and aligned at the sentence level. We describe the notable challenges in corpus preparation: segmentation, alignment of long audio recordings, and sentence-level alignment with non-verbatim transcripts. Such transcripts make the corpus suitable for speech translation research when there are significant differences between the spoken and written forms of the source language. Due to its large size, we are able to demonstrate competitive speech translation baselines on HK-LegiCoST and extend them to promising cross-corpus results on the FLEURS Cantonese subset. These results deliver insights into speech recognition and translation research in languages for which non-verbatim or ``noisy'' transcription is common due to various factors, including vernacular and dialectal speech.
Learning a Formality-Aware Japanese Sentence Representation
Jan 17, 2023



While the way intermediate representations are generated in encoder-decoder sequence-to-sequence models typically allow them to preserve the semantics of the input sentence, input features such as formality might be left out. On the other hand, downstream tasks such as translation would benefit from working with a sentence representation that preserves formality in addition to semantics, so as to generate sentences with the appropriate level of social formality -- the difference between speaking to a friend versus speaking with a supervisor. We propose a sequence-to-sequence method for learning a formality-aware representation for Japanese sentences, where sentence generation is conditioned on both the original representation of the input sentence, and a side constraint which guides the sentence representation towards preserving formality information. Additionally, we propose augmenting the sentence representation with a learned representation of formality which facilitates the extraction of formality in downstream tasks. We address the lack of formality-annotated parallel data by adapting previous works on procedural formality classification of Japanese sentences. Experimental results suggest that our techniques not only helps the decoder recover the formality of the input sentence, but also slightly improves the preservation of input sentence semantics.