 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHK-LegiCoST: Leveraging Non-Verbatim Transcripts for Speech Translation
Jun 20, 2023We introduce HK-LegiCoST, a new three-way parallel corpus of Cantonese-English translations, containing 600+ hours of Cantonese audio, its standard traditional Chinese transcript, and English translation, segmented and aligned at the sentence level. We describe the notable challenges in corpus preparation: segmentation, alignment of long audio recordings, and sentence-level alignment with non-verbatim transcripts. Such transcripts make the corpus suitable for speech translation research when there are significant differences between the spoken and written forms of the source language. Due to its large size, we are able to demonstrate competitive speech translation baselines on HK-LegiCoST and extend them to promising cross-corpus results on the FLEURS Cantonese subset. These results deliver insights into speech recognition and translation research in languages for which non-verbatim or ``noisy'' transcription is common due to various factors, including vernacular and dialectal speech.
Exploring Methods for the Automatic Detection of Errors in Manual Transcription
Apr 08, 2019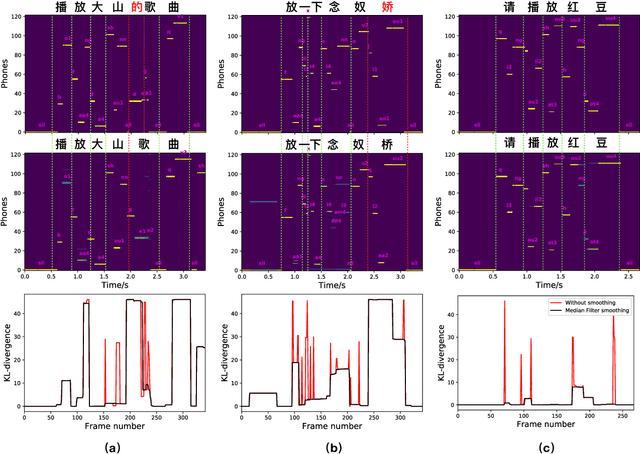

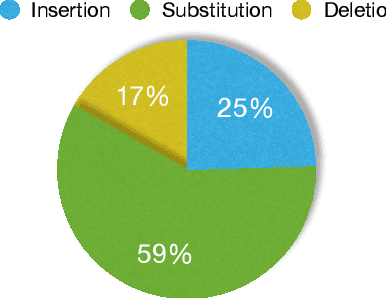

Quality of data plays an important role in most deep learning tasks. In the speech community, transcription of speech recording is indispensable. Since the transcription is usually generated artificially, automatically finding errors in manual transcriptions not only saves time and labors but benefits the performance of tasks that need the training process. Inspired by the success of hybrid automatic speech recognition using both language model and acoustic model, two approaches of automatic error detection in the transcriptions have been explored in this work. Previous study using a biased language model approach, relying on a strong transcription-dependent language model, has been reviewed. In this work, we propose a novel acoustic model based approach, focusing on the phonetic sequence of speech. Both methods have been evaluated on a completely real dataset, which was originally transcribed with errors and strictly corrected manually afterwards.
An Empirical Evaluation of Zero Resource Acoustic Unit Discovery
Feb 05, 2017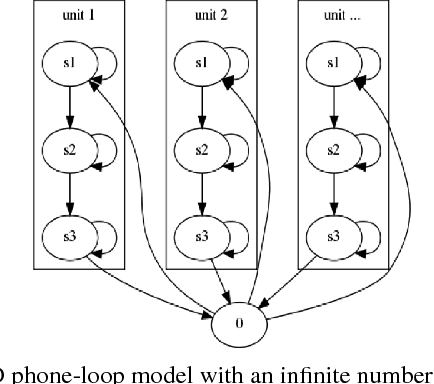
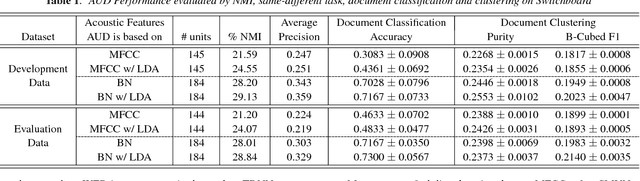
Acoustic unit discovery (AUD) is a process of automatically identifying a categorical acoustic unit inventory from speech and producing corresponding acoustic unit tokenizations. AUD provides an important avenue for unsupervised acoustic model training in a zero resource setting where expert-provided linguistic knowledge and transcribed speech are unavailable. Therefore, to further facilitate zero-resource AUD process, in this paper, we demonstrate acoustic feature representations can be significantly improved by (i) performing linear discriminant analysis (LDA) in an unsupervised self-trained fashion, and (ii) leveraging resources of other languages through building a multilingual bottleneck (BN) feature extractor to give effective cross-lingual generalization. Moreover, we perform comprehensive evaluations of AUD efficacy on multiple downstream speech applications, and their correlated performance suggests that AUD evaluations are feasible using different alternative language resources when only a subset of these evaluation resources can be available in typical zero resource applications.