 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness assessment of large audio language models in multiple-choice evaluation
Oct 06, 2025



Recent advances in large audio language models (LALMs) have primarily been assessed using a multiple-choice question answering (MCQA) framework. However, subtle changes, such as shifting the order of choices, result in substantially different results. Existing MCQA frameworks do not account for this variability and report a single accuracy number per benchmark or category. We dive into the MCQA evaluation framework and conduct a systematic study spanning three benchmarks (MMAU, MMAR and MMSU) and four models: Audio Flamingo 2, Audio Flamingo 3, Qwen2.5-Omni-7B-Instruct, and Kimi-Audio-7B-Instruct. Our findings indicate that models are sensitive not only to the ordering of choices, but also to the paraphrasing of the question and the choices. Finally, we propose a simpler evaluation protocol and metric that account for subtle variations and provide a more detailed evaluation report of LALMs within the MCQA framework.
DeCRED: Decoder-Centric Regularization for Encoder-Decoder Based Speech Recognition
Aug 12, 2025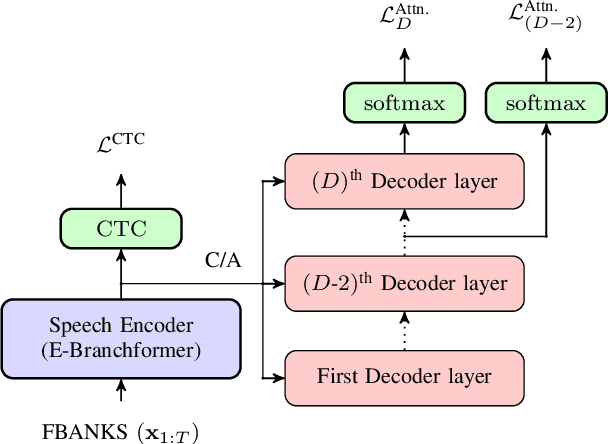
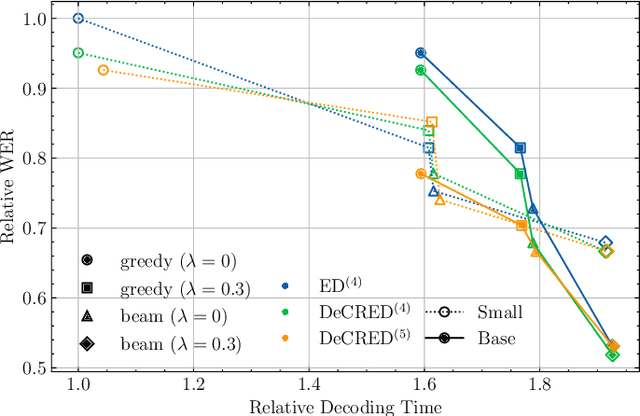


This paper presents a simple yet effective regularization for the internal language model induced by the decoder in encoder-decoder ASR models, thereby improving robustness and generalization in both in- and out-of-domain settings. The proposed method, Decoder-Centric Regularization in Encoder-Decoder (DeCRED), adds auxiliary classifiers to the decoder, enabling next token prediction via intermediate logits. Empirically, DeCRED reduces the mean internal LM BPE perplexity by 36.6% relative to 11 test sets. Furthermore, this translates into actual WER improvements over the baseline in 5 of 7 in-domain and 3 of 4 out-of-domain test sets, reducing macro WER from 6.4% to 6.3% and 18.2% to 16.2%, respectively. On TEDLIUM3, DeCRED achieves 7.0% WER, surpassing the baseline and encoder-centric InterCTC regularization by 0.6% and 0.5%, respectively. Finally, we compare DeCRED with OWSM v3.1 and Whisper-medium, showing competitive WERs despite training on much less data with fewer parameters.
Factors affecting the in-context learning abilities of LLMs for dialogue state tracking
Jun 10, 2025This study explores the application of in-context learning (ICL) to the dialogue state tracking (DST) problem and investigates the factors that influence its effectiveness. We use a sentence embedding based k-nearest neighbour method to retrieve the suitable demonstrations for ICL. The selected demonstrations, along with the test samples, are structured within a template as input to the LLM. We then conduct a systematic study to analyse the impact of factors related to demonstration selection and prompt context on DST performance. This work is conducted using the MultiWoZ2.4 dataset and focuses primarily on the OLMo-7B-instruct, Mistral-7B-Instruct-v0.3, and Llama3.2-3B-Instruct models. Our findings provide several useful insights on in-context learning abilities of LLMs for dialogue state tracking.
Approaching Dialogue State Tracking via Aligning Speech Encoders and LLMs
Jun 10, 2025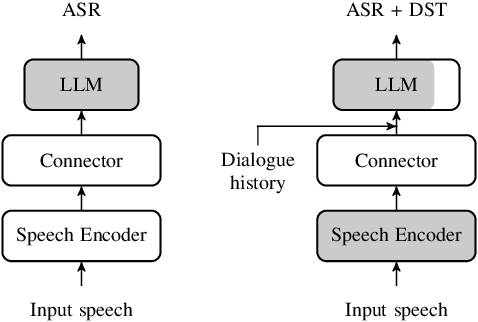
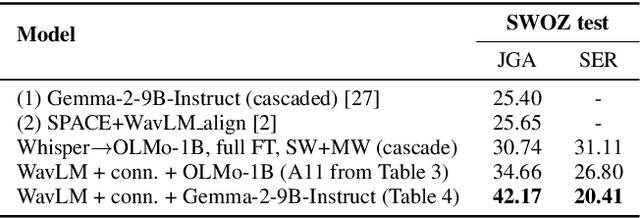
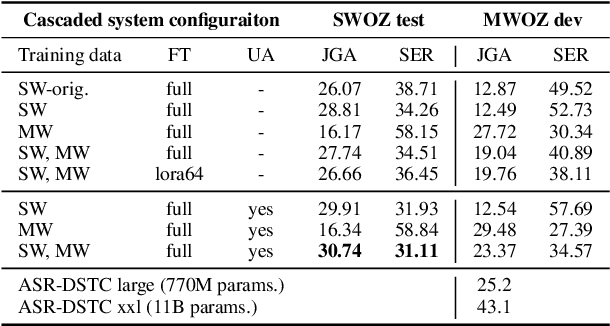
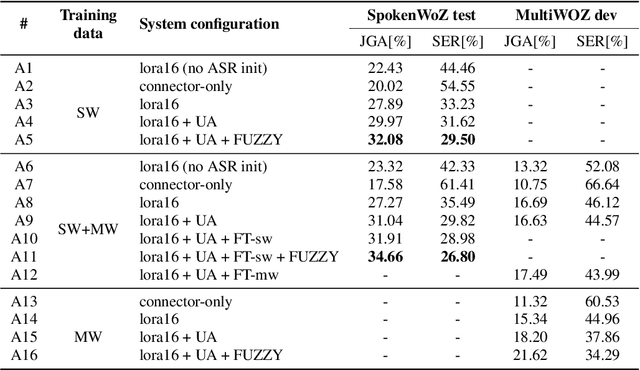
In this work, we approach spoken Dialogue State Tracking (DST) by bridging the representation spaces of speech encoders and LLMs via a small connector module, with a focus on fully open-sourced and open-data components (WavLM-large, OLMo). We focus on ablating different aspects of such systems including full/LoRA adapter fine-tuning, the effect of agent turns in the dialogue history, as well as fuzzy matching-based output post-processing, which greatly improves performance of our systems on named entities in the dialogue slot values. We conduct our experiments on the SpokenWOZ dataset, and additionally utilize the Speech-Aware MultiWOZ dataset to augment our training data. Ultimately, our best-performing WavLM + connector + OLMo-1B aligned models achieve state of the art on the SpokenWOZ test set (34.66% JGA), and our system with Gemma-2-9B-instruct further surpasses this result, reaching 42.17% JGA on SpokenWOZ test.
IIITH-BUT system for IWSLT 2025 low-resource Bhojpuri to Hindi speech translation
Jun 05, 2025



This paper presents the submission of IIITH-BUT to the IWSLT 2025 shared task on speech translation for the low-resource Bhojpuri-Hindi language pair. We explored the impact of hyperparameter optimisation and data augmentation techniques on the performance of the SeamlessM4T model fine-tuned for this specific task. We systematically investigated a range of hyperparameters including learning rate schedules, number of update steps, warm-up steps, label smoothing, and batch sizes; and report their effect on translation quality. To address data scarcity, we applied speed perturbation and SpecAugment and studied their effect on translation quality. We also examined the use of cross-lingual signal through joint training with Marathi and Bhojpuri speech data. Our experiments reveal that careful selection of hyperparameters and the application of simple yet effective augmentation techniques significantly improve performance in low-resource settings. We also analysed the translation hypotheses to understand various kinds of errors that impacted the translation quality in terms of BLEU.
Aligning Pre-trained Models for Spoken Language Translation
Nov 27, 2024This paper investigates a novel approach to end-to-end speech translation (ST) based on aligning frozen pre-trained automatic speech recognition (ASR) and machine translation (MT) models via a small connector module (Q-Former, our Subsampler-Transformer Encoder). This connector bridges the gap between the speech and text modalities, transforming ASR encoder embeddings into the latent representation space of the MT encoder while being the only part of the system optimized during training. Experiments are conducted on the How2 English-Portuguese dataset as we investigate the alignment approach in a small-scale scenario focusing on ST. While keeping the size of the connector module constant and small in comparison ( < 5% of the size of the larger aligned models), increasing the size and capability of the foundation ASR and MT models universally improves translation results. We also find that the connectors can serve as domain adapters for the foundation MT models, significantly improving translation performance in the aligned ST setting. We conclude that this approach represents a viable and scalable approach to training end-to-end ST systems.
Improving Automatic Speech Recognition with Decoder-Centric Regularisation in Encoder-Decoder Models
Oct 22, 2024



This paper proposes a simple yet effective way of regularising the encoder-decoder-based automatic speech recognition (ASR) models that enhance the robustness of the model and improve the generalisation to out-of-domain scenarios. The proposed approach is dubbed as $\textbf{De}$coder-$\textbf{C}$entric $\textbf{R}$egularisation in $\textbf{E}$ncoder-$\textbf{D}$ecoder (DeCRED) architecture for ASR, where auxiliary classifier(s) is introduced in layers of the decoder module. Leveraging these classifiers, we propose two decoding strategies that re-estimate the next token probabilities. Using the recent E-branchformer architecture, we build strong ASR systems that obtained competitive WERs as compared to Whisper-medium and outperformed OWSM v3; while relying only on a fraction of training data and model size. On top of such a strong baseline, we show that DeCRED can further improve the results and, moreover, generalise much better to out-of-domain scenarios, where we show an absolute reduction of 2.7 and 2.9 WERs on AMI and Gigaspeech datasets, respectively. We provide extensive analysis and accompanying experiments that support the benefits of the proposed regularisation scheme.
Beyond the Labels: Unveiling Text-Dependency in Paralinguistic Speech Recognition Datasets
Mar 12, 2024



Paralinguistic traits like cognitive load and emotion are increasingly recognized as pivotal areas in speech recognition research, often examined through specialized datasets like CLSE and IEMOCAP. However, the integrity of these datasets is seldom scrutinized for text-dependency. This paper critically evaluates the prevalent assumption that machine learning models trained on such datasets genuinely learn to identify paralinguistic traits, rather than merely capturing lexical features. By examining the lexical overlap in these datasets and testing the performance of machine learning models, we expose significant text-dependency in trait-labeling. Our results suggest that some machine learning models, especially large pre-trained models like HuBERT, might inadvertently focus on lexical characteristics rather than the intended paralinguistic features. The study serves as a call to action for the research community to reevaluate the reliability of existing datasets and methodologies, ensuring that machine learning models genuinely learn what they are designed to recognize.
Strategies for improving low resource speech to text translation relying on pre-trained ASR models
May 31, 2023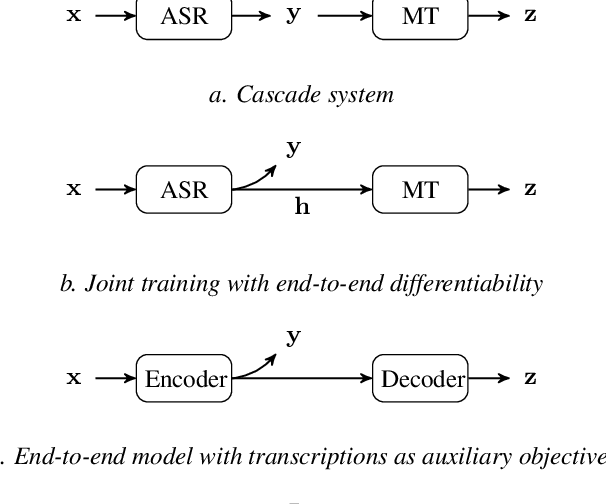

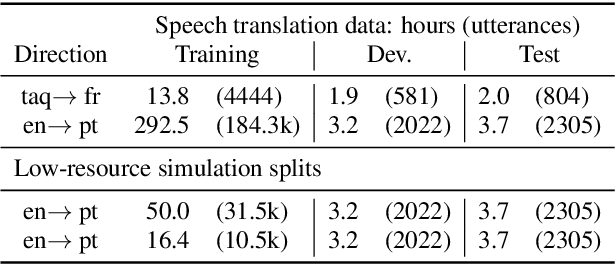
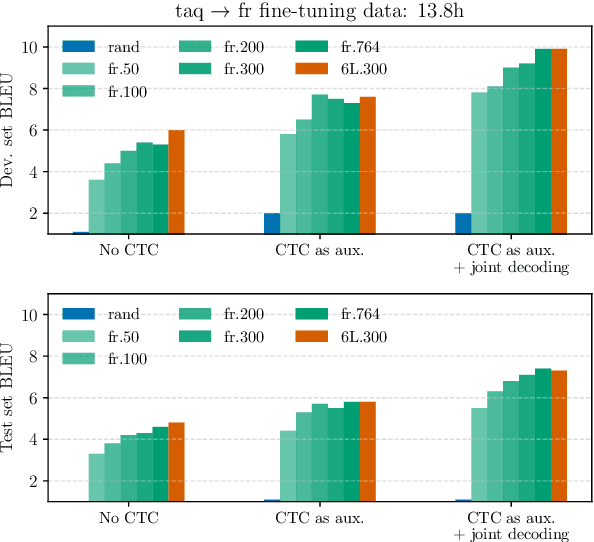
This paper presents techniques and findings for improving the performance of low-resource speech to text translation (ST). We conducted experiments on both simulated and real-low resource setups, on language pairs English - Portuguese, and Tamasheq - French respectively. Using the encoder-decoder framework for ST, our results show that a multilingual automatic speech recognition system acts as a good initialization under low-resource scenarios. Furthermore, using the CTC as an additional objective for translation during training and decoding helps to reorder the internal representations and improves the final translation. Through our experiments, we try to identify various factors (initializations, objectives, and hyper-parameters) that contribute the most for improvements in low-resource setups. With only 300 hours of pre-training data, our model achieved 7.3 BLEU score on Tamasheq - French data, outperforming prior published works from IWSLT 2022 by 1.6 points.
Detecting English Speech in the Air Traffic Control Voice Communication
Apr 06, 2021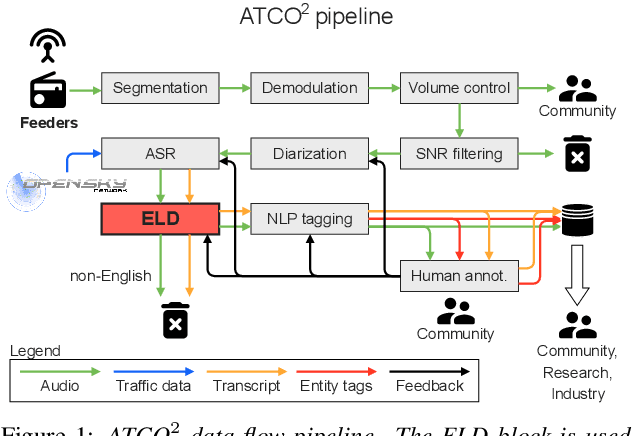
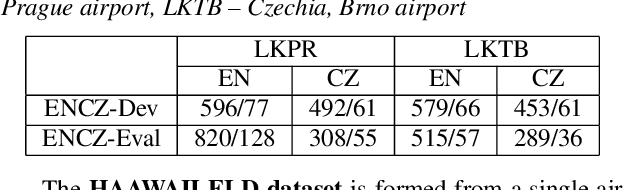
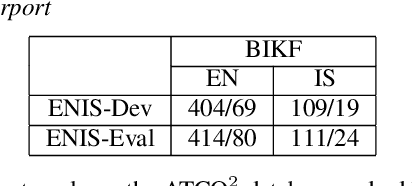

We launched a community platform for collecting the ATC speech world-wide in the ATCO2 project. Filtering out unseen non-English speech is one of the main components in the data processing pipeline. The proposed English Language Detection (ELD) system is based on the embeddings from Bayesian subspace multinomial model. It is trained on the word confusion network from an ASR system. It is robust, easy to train, and light weighted. We achieved 0.0439 equal-error-rate (EER), a 50% relative reduction as compared to the state-of-the-art acoustic ELD system based on x-vectors, in the in-domain scenario. Further, we achieved an EER of 0.1352, a 33% relative reduction as compared to the acoustic ELD, in the unseen language (out-of-domain) condition. We plan to publish the evaluation dataset from the ATCO2 project.