 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategies for improving low resource speech to text translation relying on pre-trained ASR models
May 31, 2023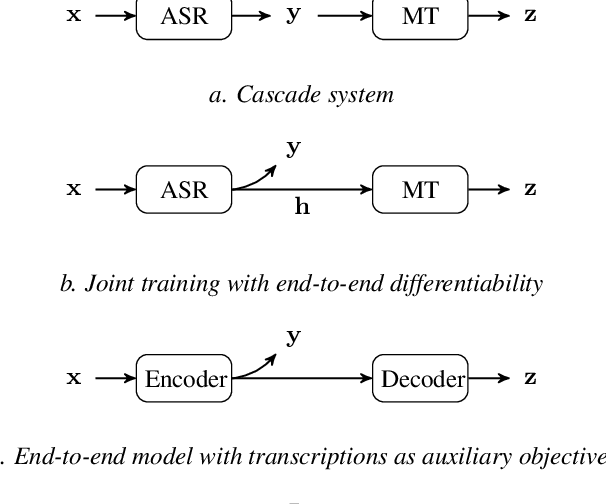

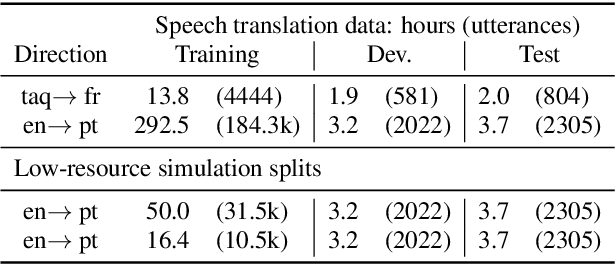
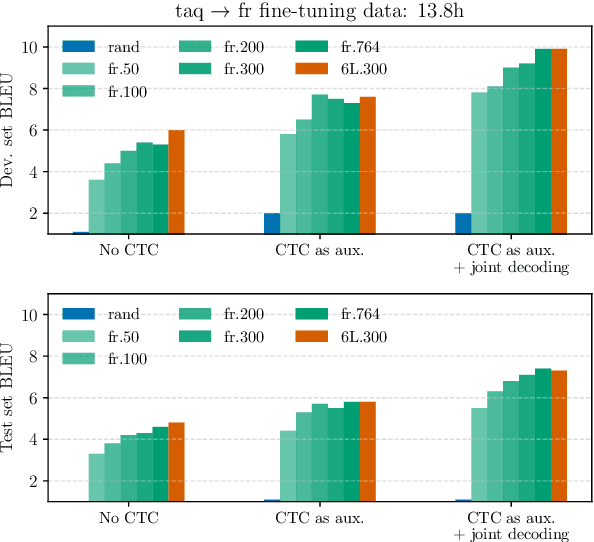
This paper presents techniques and findings for improving the performance of low-resource speech to text translation (ST). We conducted experiments on both simulated and real-low resource setups, on language pairs English - Portuguese, and Tamasheq - French respectively. Using the encoder-decoder framework for ST, our results show that a multilingual automatic speech recognition system acts as a good initialization under low-resource scenarios. Furthermore, using the CTC as an additional objective for translation during training and decoding helps to reorder the internal representations and improves the final translation. Through our experiments, we try to identify various factors (initializations, objectives, and hyper-parameters) that contribute the most for improvements in low-resource setups. With only 300 hours of pre-training data, our model achieved 7.3 BLEU score on Tamasheq - French data, outperforming prior published works from IWSLT 2022 by 1.6 points.