 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprove LLM-based Automatic Essay Scoring with Linguistic Features
Feb 13, 2025
Automatic Essay Scoring (AES) assigns scores to student essays, reducing the grading workload for instructors. Developing a scoring system capable of handling essays across diverse prompts is challenging due to the flexibility and diverse nature of the writing task. Existing methods typically fall into two categories: supervised feature-based approaches and large language model (LLM)-based methods. Supervised feature-based approaches often achieve higher performance but require resource-intensive training. In contrast, LLM-based methods are computationally efficient during inference but tend to suffer from lower performance. This paper combines these approaches by incorporating linguistic features into LLM-based scoring. Experimental results show that this hybrid method outperforms baseline models for both in-domain and out-of-domain writing prompts.
Strategies for improving low resource speech to text translation relying on pre-trained ASR models
May 31, 2023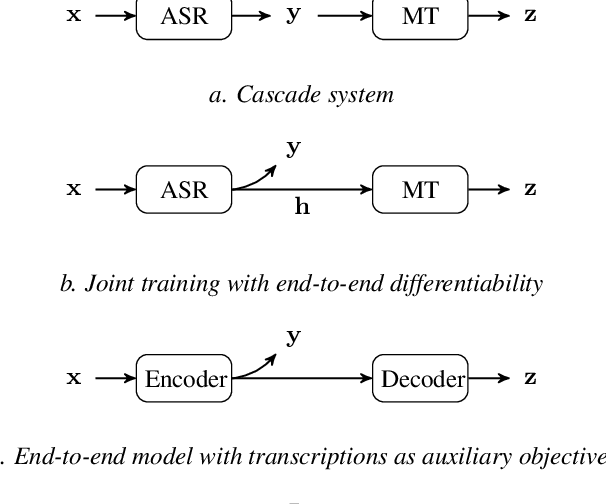

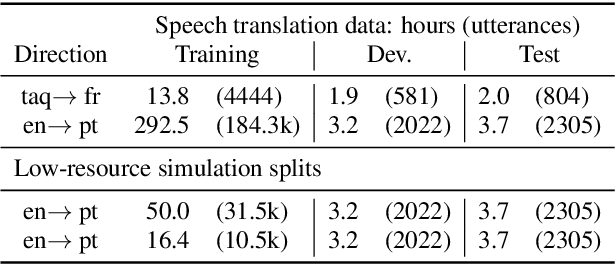
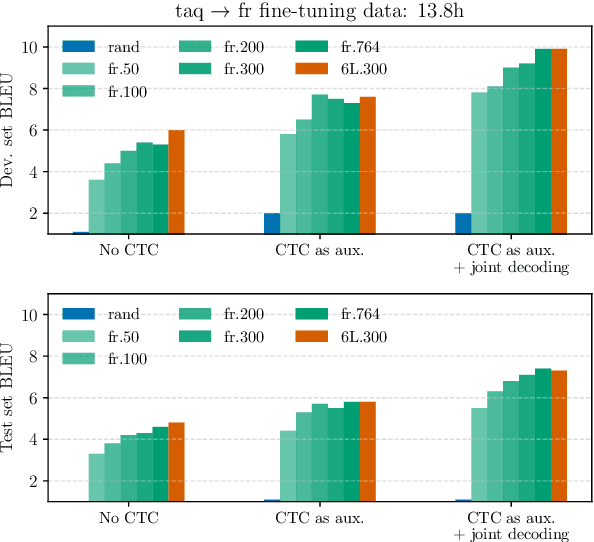
This paper presents techniques and findings for improving the performance of low-resource speech to text translation (ST). We conducted experiments on both simulated and real-low resource setups, on language pairs English - Portuguese, and Tamasheq - French respectively. Using the encoder-decoder framework for ST, our results show that a multilingual automatic speech recognition system acts as a good initialization under low-resource scenarios. Furthermore, using the CTC as an additional objective for translation during training and decoding helps to reorder the internal representations and improves the final translation. Through our experiments, we try to identify various factors (initializations, objectives, and hyper-parameters) that contribute the most for improvements in low-resource setups. With only 300 hours of pre-training data, our model achieved 7.3 BLEU score on Tamasheq - French data, outperforming prior published works from IWSLT 2022 by 1.6 points.