 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMBERT: Scaled Mixture-of-Experts Multimodal BERT for Robust Chinese Hate Speech Detection under Cloaking Perturbations
Aug 01, 2025Hate speech detection on Chinese social networks presents distinct challenges, particularly due to the widespread use of cloaking techniques designed to evade conventional text-based detection systems. Although large language models (LLMs) have recently improved hate speech detection capabilities, the majority of existing work has concentrated on English datasets, with limited attention given to multimodal strategies in the Chinese context. In this study, we propose MMBERT, a novel BERT-based multimodal framework that integrates textual, speech, and visual modalities through a Mixture-of-Experts (MoE) architecture. To address the instability associated with directly integrating MoE into BERT-based models, we develop a progressive three-stage training paradigm. MMBERT incorporates modality-specific experts, a shared self-attention mechanism, and a router-based expert allocation strategy to enhance robustness against adversarial perturbations. Empirical results in several Chinese hate speech datasets show that MMBERT significantly surpasses fine-tuned BERT-based encoder models, fine-tuned LLMs, and LLMs utilizing in-context learning approaches.
Unveiling Confirmation Bias in Chain-of-Thought Reasoning
Jun 14, 2025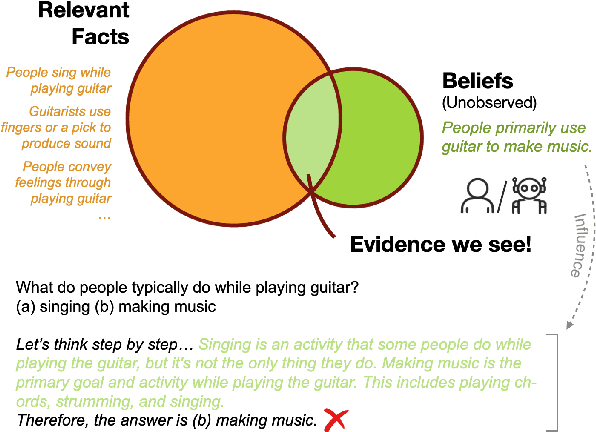
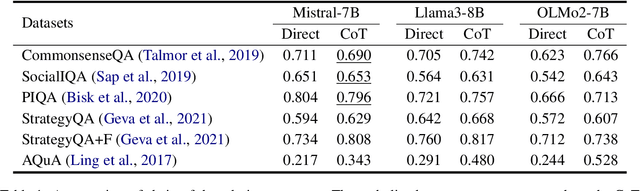
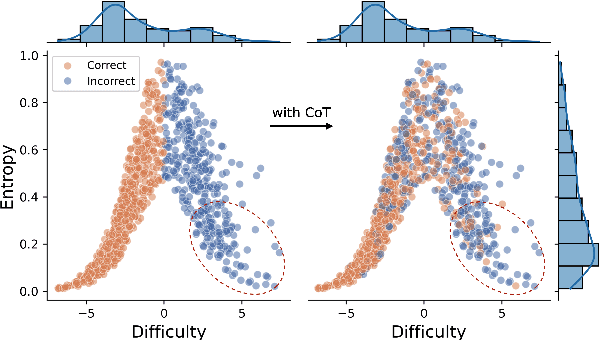
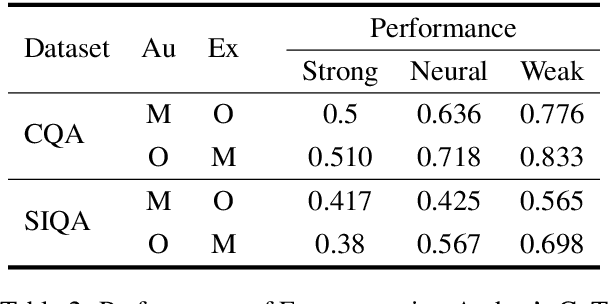
Chain-of-thought (CoT) prompting has been widely adopted to enhance the reasoning capabilities of large language models (LLMs). However, the effectiveness of CoT reasoning is inconsistent across tasks with different reasoning types. This work presents a novel perspective to understand CoT behavior through the lens of \textit{confirmation bias} in cognitive psychology. Specifically, we examine how model internal beliefs, approximated by direct question-answering probabilities, affect both reasoning generation ($Q \to R$) and reasoning-guided answer prediction ($QR \to A$) in CoT. By decomposing CoT into a two-stage process, we conduct a thorough correlation analysis in model beliefs, rationale attributes, and stage-wise performance. Our results provide strong evidence of confirmation bias in LLMs, such that model beliefs not only skew the reasoning process but also influence how rationales are utilized for answer prediction. Furthermore, the interplay between task vulnerability to confirmation bias and the strength of beliefs also provides explanations for CoT effectiveness across reasoning tasks and models. Overall, this study provides a valuable insight for the needs of better prompting strategies that mitigate confirmation bias to enhance reasoning performance. Code is available at \textit{https://github.com/yuewan2/biasedcot}.
Resolving UnderEdit & OverEdit with Iterative & Neighbor-Assisted Model Editing
Mar 14, 2025Large Language Models (LLMs) are used in various downstream language tasks, making it crucial to keep their knowledge up-to-date, but both retraining and fine-tuning the model can be costly. Model editing offers an efficient and effective alternative by a single update to only a key subset of model parameters. While being efficient, these methods are not perfect. Sometimes knowledge edits are unsuccessful, i.e., UnderEdit, or the edit contaminated neighboring knowledge that should remain unchanged, i.e., OverEdit. To address these limitations, we propose iterative model editing, based on our hypothesis that a single parameter update is often insufficient, to mitigate UnderEdit, and neighbor-assisted model editing, which incorporates neighboring knowledge during editing to minimize OverEdit. Extensive experiments demonstrate that our methods effectively reduce UnderEdit up to 38 percentage points and OverEdit up to 6 percentage points across multiple model editing algorithms, LLMs, and benchmark datasets.
Similarity-Based Domain Adaptation with LLMs
Mar 07, 2025



Unsupervised domain adaptation leverages abundant labeled data from various source domains to generalize onto unlabeled target data. Prior research has primarily focused on learning domain-invariant features across the source and target domains. However, these methods often require training a model using source domain data, which is time-consuming and can limit model usage for applications with different source data. This paper introduces a simple framework that utilizes the impressive generalization capabilities of Large Language Models (LLMs) for target data annotation without the need of source model training, followed by a novel similarity-based knowledge distillation loss. Our extensive experiments on cross-domain text classification reveal that our framework achieves impressive performance, specifically, 2.44\% accuracy improvement when compared to the SOTA method.
Improve LLM-based Automatic Essay Scoring with Linguistic Features
Feb 13, 2025
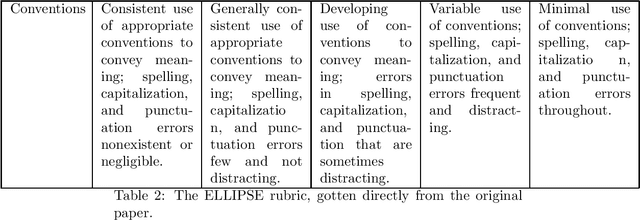
Automatic Essay Scoring (AES) assigns scores to student essays, reducing the grading workload for instructors. Developing a scoring system capable of handling essays across diverse prompts is challenging due to the flexibility and diverse nature of the writing task. Existing methods typically fall into two categories: supervised feature-based approaches and large language model (LLM)-based methods. Supervised feature-based approaches often achieve higher performance but require resource-intensive training. In contrast, LLM-based methods are computationally efficient during inference but tend to suffer from lower performance. This paper combines these approaches by incorporating linguistic features into LLM-based scoring. Experimental results show that this hybrid method outperforms baseline models for both in-domain and out-of-domain writing prompts.
Persuasiveness of Generated Free-Text Rationales in Subjective Decisions: A Case Study on Pairwise Argument Ranking
Jun 20, 2024Generating free-text rationales is among the emergent capabilities of Large Language Models (LLMs). These rationales have been found to enhance LLM performance across various NLP tasks. Recently, there has been growing interest in using these rationales to provide insights for various important downstream tasks. In this paper, we analyze generated free-text rationales in tasks with subjective answers, emphasizing the importance of rationalization in such scenarios. We focus on pairwise argument ranking, a highly subjective task with significant potential for real-world applications, such as debate assistance. We evaluate the persuasiveness of rationales generated by nine LLMs to support their subjective choices. Our findings suggest that open-source LLMs, particularly Llama2-70B-chat, are capable of providing highly persuasive rationalizations, surpassing even GPT models. Additionally, our experiments show that rationale persuasiveness can be improved by controlling its parameters through prompting or through self-refinement.
Every Answer Matters: Evaluating Commonsense with Probabilistic Measures
Jun 06, 2024



Large language models have demonstrated impressive performance on commonsense tasks; however, these tasks are often posed as multiple-choice questions, allowing models to exploit systematic biases. Commonsense is also inherently probabilistic with multiple correct answers. The purpose of "boiling water" could be making tea and cooking, but it also could be killing germs. Existing tasks do not capture the probabilistic nature of common sense. To this end, we present commonsense frame completion (CFC), a new generative task that evaluates common sense via multiple open-ended generations. We also propose a method of probabilistic evaluation that strongly correlates with human judgments. Humans drastically outperform strong language model baselines on our dataset, indicating this approach is both a challenging and useful evaluation of machine common sense.
Incorporating Geo-Diverse Knowledge into Prompting for Increased Geographical Robustness in Object Recognition
Jan 03, 2024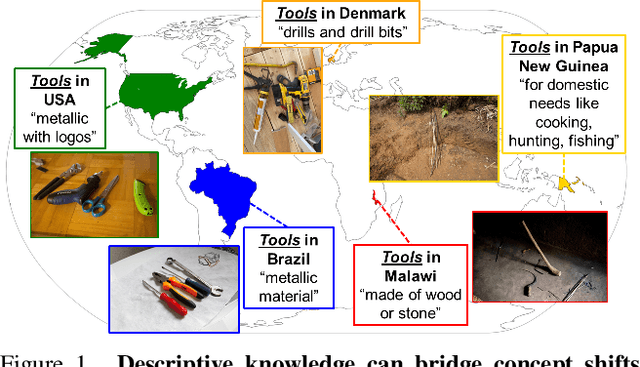
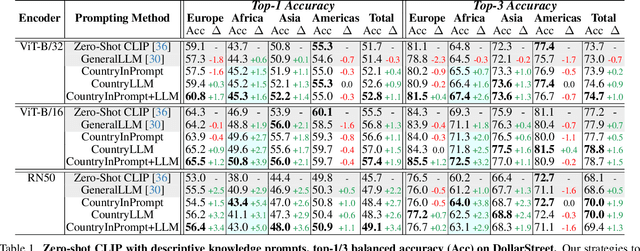
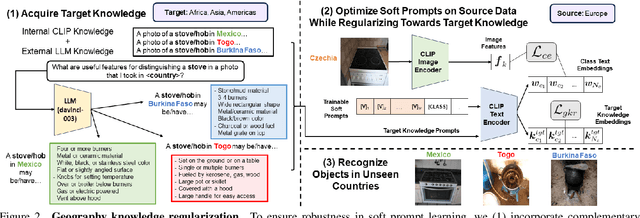
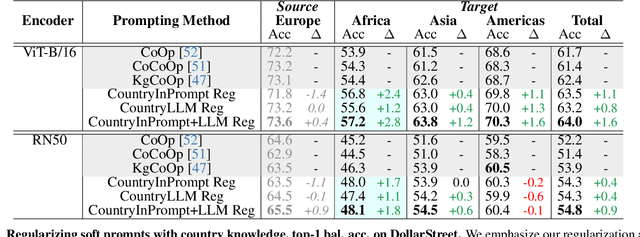
Existing object recognition models have been shown to lack robustness in diverse geographical scenarios due to significant domain shifts in design and context. Class representations need to be adapted to more accurately reflect an object concept under these shifts. In the absence of training data from target geographies, we hypothesize that geography-specific descriptive knowledge of object categories can be leveraged to enhance robustness. For this purpose, we explore the feasibility of probing a large-language model for geography-specific object knowledge, and we investigate integrating knowledge in zero-shot and learnable soft prompting with the CLIP vision-language model. In particular, we propose a geography knowledge regularization method to ensure that soft prompts trained on a source set of geographies generalize to an unseen target set of geographies. Our gains on DollarStreet when generalizing from a model trained only on data from Europe are as large as +2.8 on countries from Africa, and +4.6 on the hardest classes. We further show competitive performance vs. few-shot target training, and provide insights into how descriptive knowledge captures geographical differences.
UNcommonsense Reasoning: Abductive Reasoning about Uncommon Situations
Nov 14, 2023Language technologies that accurately model the dynamics of events must perform commonsense reasoning. Existing work evaluating commonsense reasoning focuses on making inferences about common, everyday situations. To instead investigate the ability to model unusual, unexpected, and unlikely situations, we explore the task of uncommonsense abductive reasoning. Given a piece of context with an unexpected outcome, this task requires reasoning abductively to generate a natural language explanation that makes the unexpected outcome more likely in the context. To this end, we curate and release a new English language corpus called UNcommonsense. We characterize the differences between the performance of human explainers and the best performing large language models, finding that model-enhanced human-written explanations achieve the highest quality by trading off between specificity and diversity. Finally, we experiment with several online imitation learning algorithms to train open and accessible language models on this task. When compared with the vanilla supervised fine-tuning approach, these methods consistently reduce lose rates on both common and uncommonsense abductive reasoning judged by human evaluators.
In Search of the Long-Tail: Systematic Generation of Long-Tail Knowledge via Logical Rule Guided Search
Nov 13, 2023



Since large language models have approached human-level performance on many tasks, it has become increasingly harder for researchers to find tasks that are still challenging to the models. Failure cases usually come from the long-tail distribution - data that an oracle language model could assign a probability on the lower end of its distribution. Current methodology such as prompt engineering or crowdsourcing are insufficient for creating long-tail examples because humans are constrained by cognitive bias. We propose a Logic-Induced-Knowledge-Search (LINK) framework for systematically generating long-tail knowledge statements. Grounded by a symbolic rule, we search for long-tail values for each variable of the rule by first prompting a LLM, then verifying the correctness of the values with a critic, and lastly pushing for the long-tail distribution with a reranker. With this framework we construct a dataset, Logic-Induced-Long-Tail (LINT), consisting of 200 symbolic rules and 50K knowledge statements spanning across four domains. Human annotations find that 84% of the statements in LINT are factually correct. In contrast, ChatGPT and GPT4 struggle with directly generating long-tail statements under the guidance of logic rules, each only getting 56% and 78% of their statements correct. Moreover, their "long-tail" generations in fact fall into the higher likelihood range, and thus are not really long-tail. Our findings suggest that LINK is effective for generating data in the long-tail distribution while enforcing quality. LINT can be useful for systematically evaluating LLMs' capabilities in the long-tail distribution. We challenge the models with a simple entailment classification task using samples from LINT. We find that ChatGPT and GPT4's capability in identifying incorrect knowledge drop by ~3% in the long-tail distribution compared to head distribution.