 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Faceted Evaluation of Tool-Augmented Dialogue Systems
Oct 22, 2025Evaluating conversational AI systems that use external tools is challenging, as errors can arise from complex interactions among user, agent, and tools. While existing evaluation methods assess either user satisfaction or agents' tool-calling capabilities, they fail to capture critical errors in multi-turn tool-augmented dialogues-such as when agents misinterpret tool results yet appear satisfactory to users. We introduce TRACE, a benchmark of systematically synthesized tool-augmented conversations covering diverse error cases, and SCOPE, an evaluation framework that automatically discovers diverse error patterns and evaluation rubrics in tool-augmented dialogues. Experiments show SCOPE significantly outperforms the baseline, particularly on challenging cases where user satisfaction signals are misleading.
Improve LLM-based Automatic Essay Scoring with Linguistic Features
Feb 13, 2025
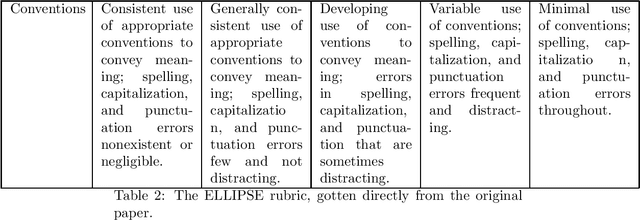
Automatic Essay Scoring (AES) assigns scores to student essays, reducing the grading workload for instructors. Developing a scoring system capable of handling essays across diverse prompts is challenging due to the flexibility and diverse nature of the writing task. Existing methods typically fall into two categories: supervised feature-based approaches and large language model (LLM)-based methods. Supervised feature-based approaches often achieve higher performance but require resource-intensive training. In contrast, LLM-based methods are computationally efficient during inference but tend to suffer from lower performance. This paper combines these approaches by incorporating linguistic features into LLM-based scoring. Experimental results show that this hybrid method outperforms baseline models for both in-domain and out-of-domain writing prompts.
Choice-75: A Dataset on Decision Branching in Script Learning
Sep 21, 2023Script learning studies how daily events unfold. Previous works tend to consider a script as a linear sequence of events while ignoring the potential branches that arise due to people's circumstantial choices. We hence propose Choice-75, the first benchmark that challenges intelligent systems to predict decisions given descriptive scenarios, containing 75 scripts and more than 600 scenarios. While large language models demonstrate overall decent performances, there is still notable room for improvement in many hard scenarios.