 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrefPalette: Personalized Preference Modeling with Latent Attributes
Jul 17, 2025



Personalizing AI systems requires understanding not just what users prefer, but the reasons that underlie those preferences - yet current preference models typically treat human judgment as a black box. We introduce PrefPalette, a framework that decomposes preferences into attribute dimensions and tailors its preference prediction to distinct social community values in a human-interpretable manner. PrefPalette operationalizes a cognitive science principle known as multi-attribute decision making in two ways: (1) a scalable counterfactual attribute synthesis step that involves generating synthetic training data to isolate for individual attribute effects (e.g., formality, humor, cultural values), and (2) attention-based preference modeling that learns how different social communities dynamically weight these attributes. This approach moves beyond aggregate preference modeling to capture the diverse evaluation frameworks that drive human judgment. When evaluated on 45 social communities from the online platform Reddit, PrefPalette outperforms GPT-4o by 46.6% in average prediction accuracy. Beyond raw predictive improvements, PrefPalette also shed light on intuitive, community-specific profiles: scholarly communities prioritize verbosity and stimulation, conflict-oriented communities value sarcasm and directness, and support-based communities emphasize empathy. By modeling the attribute-mediated structure of human judgment, PrefPalette delivers both superior preference modeling and transparent, interpretable insights, and serves as a first step toward more trustworthy, value-aware personalized applications.
Finding Flawed Fictions: Evaluating Complex Reasoning in Language Models via Plot Hole Detection
Apr 16, 2025
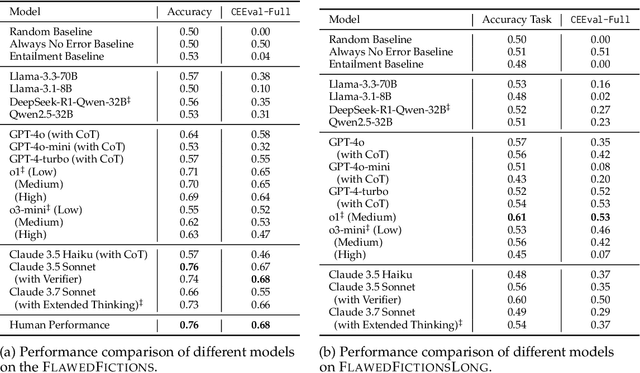

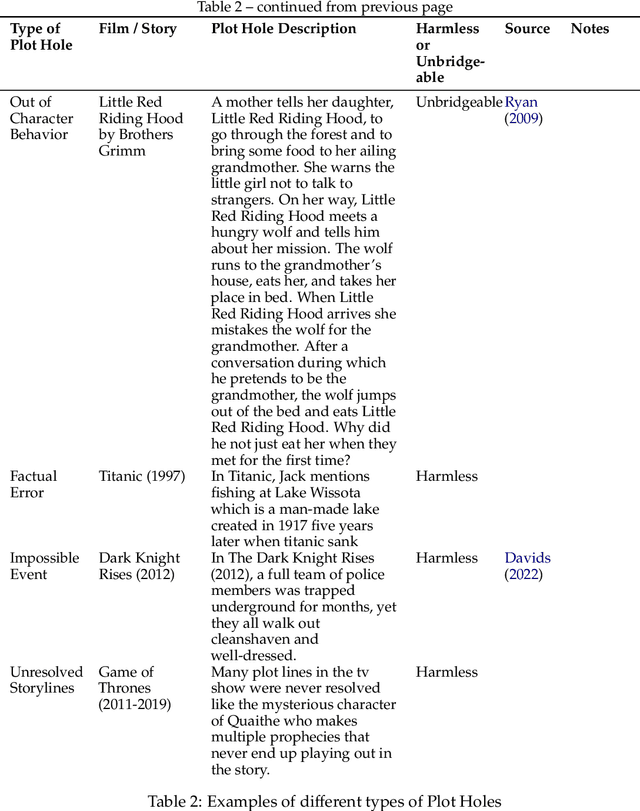
Stories are a fundamental aspect of human experience. Engaging deeply with stories and spotting plot holes -- inconsistencies in a storyline that break the internal logic or rules of a story's world -- requires nuanced reasoning skills, including tracking entities and events and their interplay, abstract thinking, pragmatic narrative understanding, commonsense and social reasoning, and theory of mind. As Large Language Models (LLMs) increasingly generate, interpret, and modify text, rigorously assessing their narrative consistency and deeper language understanding becomes critical. However, existing benchmarks focus mainly on surface-level comprehension. In this work, we propose plot hole detection in stories as a proxy to evaluate language understanding and reasoning in LLMs. We introduce FlawedFictionsMaker, a novel algorithm to controllably and carefully synthesize plot holes in human-written stories. Using this algorithm, we construct a benchmark to evaluate LLMs' plot hole detection abilities in stories -- FlawedFictions -- , which is robust to contamination, with human filtering ensuring high quality. We find that state-of-the-art LLMs struggle in accurately solving FlawedFictions regardless of the reasoning effort allowed, with performance significantly degrading as story length increases. Finally, we show that LLM-based story summarization and story generation are prone to introducing plot holes, with more than 50% and 100% increases in plot hole detection rates with respect to human-written originals.
Hypothesis-Driven Theory-of-Mind Reasoning for Large Language Models
Feb 17, 2025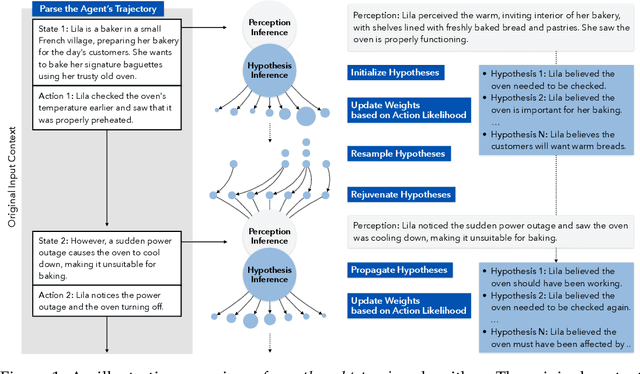

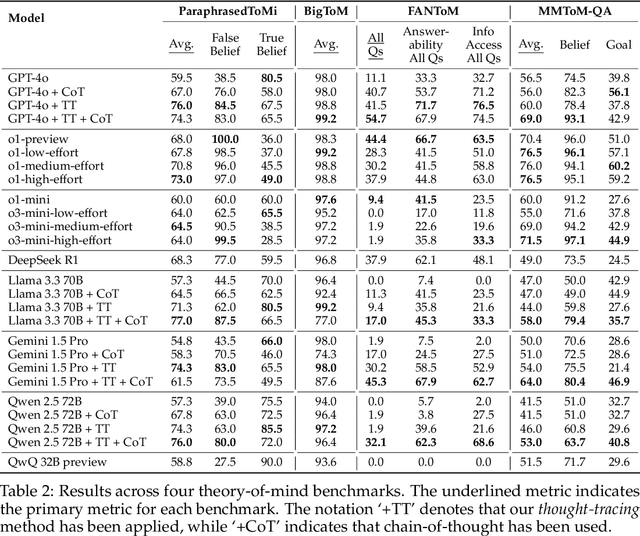
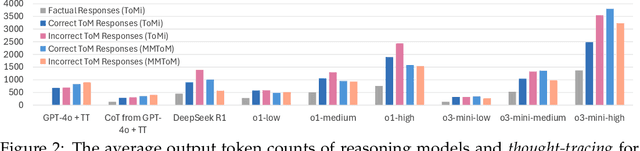
Existing LLM reasoning methods have shown impressive capabilities across various tasks, such as solving math and coding problems. However, applying these methods to scenarios without ground-truth answers or rule-based verification methods - such as tracking the mental states of an agent - remains challenging. Inspired by the sequential Monte Carlo algorithm, we introduce thought-tracing, an inference-time reasoning algorithm designed to trace the mental states of specific agents by generating hypotheses and weighting them based on observations without relying on ground-truth solutions to questions in datasets. Our algorithm is modeled after the Bayesian theory-of-mind framework, using LLMs to approximate probabilistic inference over agents' evolving mental states based on their perceptions and actions. We evaluate thought-tracing on diverse theory-of-mind benchmarks, demonstrating significant performance improvements compared to baseline LLMs. Our experiments also reveal interesting behaviors of the recent reasoning models - e.g., o1 and R1 - on theory-of-mind, highlighting the difference of social reasoning compared to other domains.
Explore Theory of Mind: Program-guided adversarial data generation for theory of mind reasoning
Dec 12, 2024



Do large language models (LLMs) have theory of mind? A plethora of papers and benchmarks have been introduced to evaluate if current models have been able to develop this key ability of social intelligence. However, all rely on limited datasets with simple patterns that can potentially lead to problematic blind spots in evaluation and an overestimation of model capabilities. We introduce ExploreToM, the first framework to allow large-scale generation of diverse and challenging theory of mind data for robust training and evaluation. Our approach leverages an A* search over a custom domain-specific language to produce complex story structures and novel, diverse, yet plausible scenarios to stress test the limits of LLMs. Our evaluation reveals that state-of-the-art LLMs, such as Llama-3.1-70B and GPT-4o, show accuracies as low as 0% and 9% on ExploreToM-generated data, highlighting the need for more robust theory of mind evaluation. As our generations are a conceptual superset of prior work, fine-tuning on our data yields a 27-point accuracy improvement on the classic ToMi benchmark (Le et al., 2019). ExploreToM also enables uncovering underlying skills and factors missing for models to show theory of mind, such as unreliable state tracking or data imbalances, which may contribute to models' poor performance on benchmarks.
AI as Humanity's Salieri: Quantifying Linguistic Creativity of Language Models via Systematic Attribution of Machine Text against Web Text
Oct 05, 2024Creativity has long been considered one of the most difficult aspect of human intelligence for AI to mimic. However, the rise of Large Language Models (LLMs), like ChatGPT, has raised questions about whether AI can match or even surpass human creativity. We present CREATIVITY INDEX as the first step to quantify the linguistic creativity of a text by reconstructing it from existing text snippets on the web. CREATIVITY INDEX is motivated by the hypothesis that the seemingly remarkable creativity of LLMs may be attributable in large part to the creativity of human-written texts on the web. To compute CREATIVITY INDEX efficiently, we introduce DJ SEARCH, a novel dynamic programming algorithm that can search verbatim and near-verbatim matches of text snippets from a given document against the web. Experiments reveal that the CREATIVITY INDEX of professional human authors is on average 66.2% higher than that of LLMs, and that alignment reduces the CREATIVITY INDEX of LLMs by an average of 30.1%. In addition, we find that distinguished authors like Hemingway exhibit measurably higher CREATIVITY INDEX compared to other human writers. Finally, we demonstrate that CREATIVITY INDEX can be used as a surprisingly effective criterion for zero-shot machine text detection, surpassing the strongest existing zero-shot system, DetectGPT, by a significant margin of 30.2%, and even outperforming the strongest supervised system, GhostBuster, in five out of six domains.
The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning
Dec 04, 2023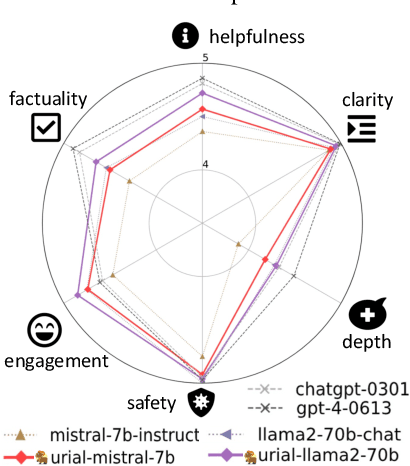
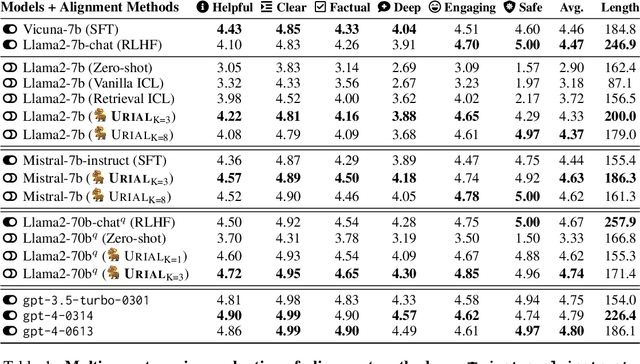
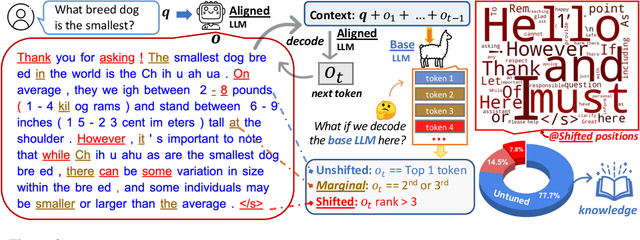

The alignment tuning process of large language models (LLMs) typically involves instruction learning through supervised fine-tuning (SFT) and preference tuning via reinforcement learning from human feedback (RLHF). A recent study, LIMA (Zhou et al. 2023), shows that using merely 1K examples for SFT can achieve significant alignment performance as well, suggesting that the effect of alignment tuning might be "superficial." This raises questions about how exactly the alignment tuning transforms a base LLM. We analyze the effect of alignment tuning by examining the token distribution shift between base LLMs and their aligned counterpart. Our findings reveal that base LLMs and their alignment-tuned versions perform nearly identically in decoding on the majority of token positions. Most distribution shifts occur with stylistic tokens. These direct evidence strongly supports the Superficial Alignment Hypothesis suggested by LIMA. Based on these findings, we rethink the alignment of LLMs by posing the research question: how effectively can we align base LLMs without SFT or RLHF? To address this, we introduce a simple, tuning-free alignment method, URIAL. URIAL achieves effective alignment purely through in-context learning (ICL) with base LLMs, requiring as few as three constant stylistic examples and a system prompt. We conduct a fine-grained and interpretable evaluation on a diverse set of examples, named JUST-EVAL-INSTRUCT. Results demonstrate that base LLMs with URIAL can match or even surpass the performance of LLMs aligned with SFT or SFT+RLHF. We show that the gap between tuning-free and tuning-based alignment methods can be significantly reduced through strategic prompting and ICL. Our findings on the superficial nature of alignment tuning and results with URIAL suggest that deeper analysis and theoretical understanding of alignment is crucial to future LLM research.
FANToM: A Benchmark for Stress-testing Machine Theory of Mind in Interactions
Oct 31, 2023Theory of mind (ToM) evaluations currently focus on testing models using passive narratives that inherently lack interactivity. We introduce FANToM, a new benchmark designed to stress-test ToM within information-asymmetric conversational contexts via question answering. Our benchmark draws upon important theoretical requisites from psychology and necessary empirical considerations when evaluating large language models (LLMs). In particular, we formulate multiple types of questions that demand the same underlying reasoning to identify illusory or false sense of ToM capabilities in LLMs. We show that FANToM is challenging for state-of-the-art LLMs, which perform significantly worse than humans even with chain-of-thought reasoning or fine-tuning.
Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting
Oct 17, 2023



As large language models (LLMs) are adopted as a fundamental component of language technologies, it is crucial to accurately characterize their performance. Because choices in prompt design can strongly influence model behavior, this design process is critical in effectively using any modern pre-trained generative language model. In this work, we focus on LLM sensitivity to a quintessential class of meaning-preserving design choices: prompt formatting. We find that several widely used open-source LLMs are extremely sensitive to subtle changes in prompt formatting in few-shot settings, with performance differences of up to 76 accuracy points when evaluated using LLaMA-2-13B. Sensitivity remains even when increasing model size, the number of few-shot examples, or performing instruction tuning. Our analysis suggests that work evaluating LLMs with prompting-based methods would benefit from reporting a range of performance across plausible prompt formats, instead of the currently-standard practice of reporting performance on a single format. We also show that format performance only weakly correlates between models, which puts into question the methodological validity of comparing models with an arbitrarily chosen, fixed prompt format. To facilitate systematic analysis we propose FormatSpread, an algorithm that rapidly evaluates a sampled set of plausible prompt formats for a given task, and reports the interval of expected performance without accessing model weights. Furthermore, we present a suite of analyses that characterize the nature of this sensitivity, including exploring the influence of particular atomic perturbations and the internal representation of particular formats.
Phenomenal Yet Puzzling: Testing Inductive Reasoning Capabilities of Language Models with Hypothesis Refinement
Oct 12, 2023The ability to derive underlying principles from a handful of observations and then generalize to novel situations -- known as inductive reasoning -- is central to human intelligence. Prior work suggests that language models (LMs) often fall short on inductive reasoning, despite achieving impressive success on research benchmarks. In this work, we conduct a systematic study of the inductive reasoning capabilities of LMs through iterative hypothesis refinement, a technique that more closely mirrors the human inductive process than standard input-output prompting. Iterative hypothesis refinement employs a three-step process: proposing, selecting, and refining hypotheses in the form of textual rules. By examining the intermediate rules, we observe that LMs are phenomenal hypothesis proposers (i.e., generating candidate rules), and when coupled with a (task-specific) symbolic interpreter that is able to systematically filter the proposed set of rules, this hybrid approach achieves strong results across inductive reasoning benchmarks that require inducing causal relations, language-like instructions, and symbolic concepts. However, they also behave as puzzling inductive reasoners, showing notable performance gaps in rule induction (i.e., identifying plausible rules) and rule application (i.e., applying proposed rules to instances), suggesting that LMs are proposing hypotheses without being able to actually apply the rules. Through empirical and human analyses, we further reveal several discrepancies between the inductive reasoning processes of LMs and humans, shedding light on both the potentials and limitations of using LMs in inductive reasoning tasks.
Faith and Fate: Limits of Transformers on Compositionality
Jun 01, 2023



Transformer large language models (LLMs) have sparked admiration for their exceptional performance on tasks that demand intricate multi-step reasoning. Yet, these models simultaneously show failures on surprisingly trivial problems. This begs the question: Are these errors incidental, or do they signal more substantial limitations? In an attempt to demystify Transformers, we investigate the limits of these models across three representative compositional tasks -- multi-digit multiplication, logic grid puzzles, and a classic dynamic programming problem. These tasks require breaking problems down into sub-steps and synthesizing these steps into a precise answer. We formulate compositional tasks as computation graphs to systematically quantify the level of complexity, and break down reasoning steps into intermediate sub-procedures. Our empirical findings suggest that Transformers solve compositional tasks by reducing multi-step compositional reasoning into linearized subgraph matching, without necessarily developing systematic problem-solving skills. To round off our empirical study, we provide theoretical arguments on abstract multi-step reasoning problems that highlight how Transformers' performance will rapidly decay with increased task complexity.