 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnpredictaBench: A Benchmark for Evaluating Distributional Randomness in LLMs
Jun 04, 2026We introduce UnpredictaBench, an evaluation that tests the ability of large language models (LLMs) to capture true underlying distributions. As LLMs are increasingly used as substitutes for other entities (e.g., for humans in economic simulations), the tendency of many models to collapse towards a single plausible answer means a failure to capture the unpredictability of real systems. Recent work on improving output diversity is insufficient for this setting: simulation requires samples that are calibrated to a target distribution, not merely varied outputs. UnpredictaBench isolates a simplified but fundamental version of this problem: sampling outcomes from individual target distributions, including canonical statistical distributions, distributions induced by stochastic programs, and natural-language scenarios that describe random processes. We introduce 448 such problems together with KS@N, a general-purpose evaluation metric that quantifies how well a model outputs approximate black-box target distributions via the Kolmogorov-Smirnov statistical test. This is the rate at which we fail to reject model samples of size N against ground-truth samples, with larger N indicating greater difficulty. Tested across open and proprietary models, we find a large spread in distributional capabilities. For instance, when models generate samples of size 100 (KS@100, our standard metric), scores range from near 0 to over 20%. No model is able to achieve over 40% at KS@100, showing significant headroom in distributional sampling as a capability. Although adding reasoning can somewhat increase scores, we find no immediate solution for this issue. UnpredictaBench shows that even simple distributional simulation remains challenging, making it a necessary first step toward using LLMs as stand-ins for complex systems.
Can You Keep a Secret? Involuntary Information Leakage in Language Model Writing
May 11, 2026Language models are deployed in settings that require compartmentalization: system prompts should not be disclosed, chain-of-thought reasoning is hidden from users, and sensitive data passes through shared contexts. We test whether models can keep prompted information out of their writing. We give each model a secret word with instructions not to reveal it, then ask it to write a story. A second model tries to identify the secret from the story in a binary discrimination test. The secret word never appears literally in any output, but all five frontier models we test leak it thematically -- through topic choice, imagery, and setting--6hy-at rates significantly different from chance, up to 79\%. When told to actively hide the secret, models write \emph{away from} it, and this avoidance is itself detectable. The leakage is cross-model readable, scales sharply with model size within two model families, and disappears entirely for short-form writing like jokes. Giving the model a decoy concept to ``focus on instead'' partially redirects the leakage from the real secret to the decoy. Attending to a secret appears to open up an information channel that frontier LLMs cannot close, even when instructed to.
Spoiler Alert: Narrative Forecasting as a Metric for Tension in LLM Storytelling
Apr 10, 2026LLMs have so far failed both to generate consistently compelling stories and to recognize this failure--on the leading creative-writing benchmark (EQ-Bench), LLM judges rank zero-shot AI stories above New Yorker short stories, a gold standard for literary fiction. We argue that existing rubrics overlook a key dimension of compelling human stories: narrative tension. We introduce the 100-Endings metric, which walks through a story sentence by sentence: at each position, a model predicts how the story will end 100 times given only the text so far, and we measure tension as how often predictions fail to match the ground truth. Beyond the mismatch rate, the sentence-level curve yields complementary statistics, such as inflection rate, a geometric measure of how frequently the curve reverses direction, tracking twists and revelations. Unlike rubric-based judges, 100-Endings correctly ranks New Yorker stories far above LLM outputs. Grounded in narratological principles, we design a story-generation pipeline using structural constraints, including analysis of story templates, idea formulation, and narrative scaffolding. Our pipeline significantly increases narrative tension as measured by the 100-Endings metric, while maintaining performance on the EQ-Bench leaderboard.
Watch Before You Answer: Learning from Visually Grounded Post-Training
Apr 06, 2026It is critical for vision-language models (VLMs) to comprehensively understand visual, temporal, and textual cues. However, despite rapid progress in multimodal modeling, video understanding performance still lags behind text-based reasoning. In this work, we find that progress is even worse than previously assumed: commonly reported long video understanding benchmarks contain 40-60% of questions that can be answered using text cues alone. Furthermore, we find that these issues are also pervasive in widely used post-training datasets, potentially undercutting the ability of post-training to improve VLM video understanding performance. Guided by this observation, we introduce VidGround as a simple yet effective solution: using only the actual visually grounded questions without any linguistic biases for post-training. When used in tandem with RL-based post-training algorithms, this simple technique improves performance by up to 6.2 points relative to using the full dataset, while using only 69.1% of the original post-training data. Moreover, we show that data curation with a simple post-training algorithm outperforms several more complex post-training techniques, highlighting that data quality is a major bottleneck for improving video understanding in VLMs. These results underscore the importance of curating post-training data and evaluation benchmarks that truly require visual grounding to advance the development of more capable VLMs. Project page: http://vidground.etuagi.com.
AbsenceBench: Language Models Can't Tell What's Missing
Jun 13, 2025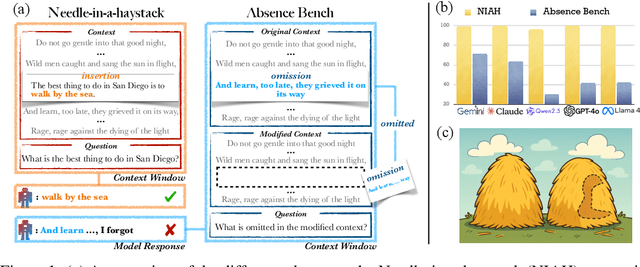

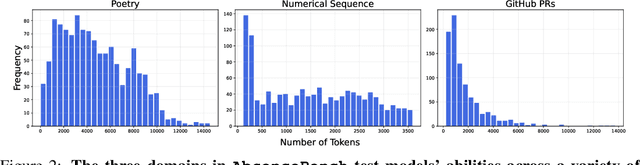

Large language models (LLMs) are increasingly capable of processing long inputs and locating specific information within them, as evidenced by their performance on the Needle in a Haystack (NIAH) test. However, while models excel at recalling surprising information, they still struggle to identify clearly omitted information. We introduce AbsenceBench to assesses LLMs' capacity to detect missing information across three domains: numerical sequences, poetry, and GitHub pull requests. AbsenceBench asks models to identify which pieces of a document were deliberately removed, given access to both the original and edited contexts. Despite the apparent straightforwardness of these tasks, our experiments reveal that even state-of-the-art models like Claude-3.7-Sonnet achieve only 69.6% F1-score with a modest average context length of 5K tokens. Our analysis suggests this poor performance stems from a fundamental limitation: Transformer attention mechanisms cannot easily attend to "gaps" in documents since these absences don't correspond to any specific keys that can be attended to. Overall, our results and analysis provide a case study of the close proximity of tasks where models are already superhuman (NIAH) and tasks where models breakdown unexpectedly (AbsenceBench).
Base Models Beat Aligned Models at Randomness and Creativity
Apr 30, 2025



Alignment has quickly become a default ingredient in LLM development, with techniques such as reinforcement learning from human feedback making models act safely, follow instructions, and perform ever-better on complex tasks. While these techniques are certainly useful, we propose that they should not be universally applied and demonstrate a range of tasks on which base language models consistently outperform their popular aligned forms. Particularly, we study tasks that require unpredictable outputs, such as random number generation, mixed strategy games (rock-paper-scissors and hide-and-seek), and creative writing. In each case, aligned models tend towards narrow behaviors that result in distinct disadvantages, for instance, preferring to generate "7" over other uniformly random numbers, becoming almost fully predictable in some game states, or prioritizing pleasant writing over creative originality. Across models tested, better performance on common benchmarks tends to correlate with worse performance on our tasks, suggesting an effective trade-off in the required capabilities.
BottleHumor: Self-Informed Humor Explanation using the Information Bottleneck Principle
Feb 22, 2025
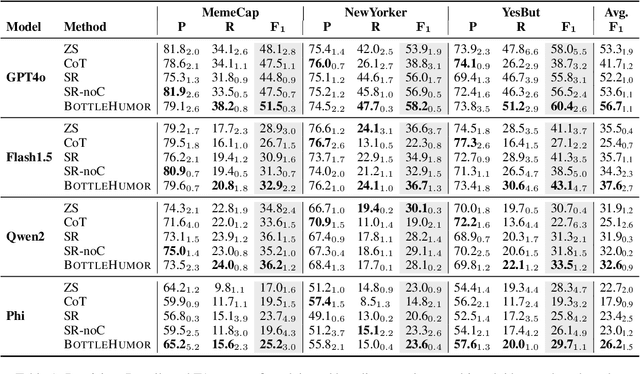


Humor is prevalent in online communications and it often relies on more than one modality (e.g., cartoons and memes). Interpreting humor in multimodal settings requires drawing on diverse types of knowledge, including metaphorical, sociocultural, and commonsense knowledge. However, identifying the most useful knowledge remains an open question. We introduce \method{}, a method inspired by the information bottleneck principle that elicits relevant world knowledge from vision and language models which is iteratively refined for generating an explanation of the humor in an unsupervised manner. Our experiments on three datasets confirm the advantage of our method over a range of baselines. Our method can further be adapted in the future for additional tasks that can benefit from eliciting and conditioning on relevant world knowledge and open new research avenues in this direction.
Benchmarks as Microscopes: A Call for Model Metrology
Jul 22, 2024Modern language models (LMs) pose a new challenge in capability assessment. Static benchmarks inevitably saturate without providing confidence in the deployment tolerances of LM-based systems, but developers nonetheless claim that their models have generalized traits such as reasoning or open-domain language understanding based on these flawed metrics. The science and practice of LMs requires a new approach to benchmarking which measures specific capabilities with dynamic assessments. To be confident in our metrics, we need a new discipline of model metrology -- one which focuses on how to generate benchmarks that predict performance under deployment. Motivated by our evaluation criteria, we outline how building a community of model metrology practitioners -- one focused on building tools and studying how to measure system capabilities -- is the best way to meet these needs to and add clarity to the AI discussion.
Predicting vs. Acting: A Trade-off Between World Modeling & Agent Modeling
Jul 02, 2024
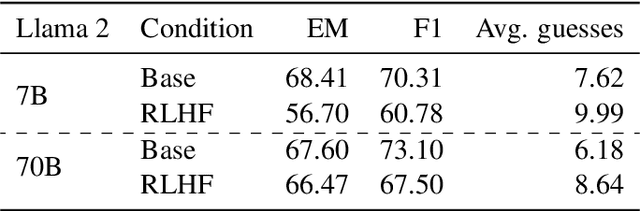


RLHF-aligned LMs have shown unprecedented ability on both benchmarks and long-form text generation, yet they struggle with one foundational task: next-token prediction. As RLHF models become agent models aimed at interacting with humans, they seem to lose their world modeling -- the ability to predict what comes next in arbitrary documents, which is the foundational training objective of the Base LMs that RLHF adapts. Besides empirically demonstrating this trade-off, we propose a potential explanation: to perform coherent long-form generation, RLHF models restrict randomness via implicit blueprints. In particular, RLHF models concentrate probability on sets of anchor spans that co-occur across multiple generations for the same prompt, serving as textual scaffolding but also limiting a model's ability to generate documents that do not include these spans. We study this trade-off on the most effective current agent models, those aligned with RLHF, while exploring why this may remain a fundamental trade-off between models that act and those that predict, even as alignment techniques improve.
Information-Theoretic Distillation for Reference-less Summarization
Mar 20, 2024The current winning recipe for automatic summarization is using proprietary large-scale language models (LLMs) such as ChatGPT as is, or imitation learning from them as teacher models. While increasingly ubiquitous dependence on such large-scale language models is convenient, there remains an important question of whether small-scale models could have achieved competitive results, if we were to seek an alternative learning method -- that allows for a more cost-efficient, controllable, yet powerful summarizer. We present InfoSumm, a novel framework to distill a powerful summarizer based on the information-theoretic objective for summarization, without relying on either the LLM's capability or human-written references. To achieve this, we first propose a novel formulation of the desiderata of summarization (saliency, faithfulness and brevity) through the lens of mutual information between the original document and the summary. Based on this formulation, we start off from Pythia-2.8B as the teacher model, which is not yet capable of summarization, then self-train the model to optimize for the information-centric measures of ideal summaries. Distilling from the improved teacher, we arrive at a compact but powerful summarizer with only 568M parameters that performs competitively against ChatGPT, without ever relying on ChatGPT's capabilities. Extensive analysis demonstrates that our approach outperforms in-domain supervised models in human evaluation, let alone state-of-the-art unsupervised methods, and wins over ChatGPT in controllable summarization.