 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
Certainly Uncertain: A Benchmark and Metric for Multimodal Epistemic and Aleatoric Awareness
Jul 02, 2024



The ability to acknowledge the inevitable uncertainty in their knowledge and reasoning is a prerequisite for AI systems to be truly truthful and reliable. In this paper, we present a taxonomy of uncertainty specific to vision-language AI systems, distinguishing between epistemic uncertainty (arising from a lack of information) and aleatoric uncertainty (due to inherent unpredictability), and further explore finer categories within. Based on this taxonomy, we synthesize a benchmark dataset, CertainlyUncertain, featuring 178K visual question answering (VQA) samples as contrastive pairs. This is achieved by 1) inpainting images to make previously answerable questions into unanswerable ones; and 2) using image captions to prompt large language models for both answerable and unanswerable questions. Additionally, we introduce a new metric confidence-weighted accuracy, that is well correlated with both accuracy and calibration error, to address the shortcomings of existing metrics.
Selective "Selective Prediction": Reducing Unnecessary Abstention in Vision-Language Reasoning
Feb 23, 2024
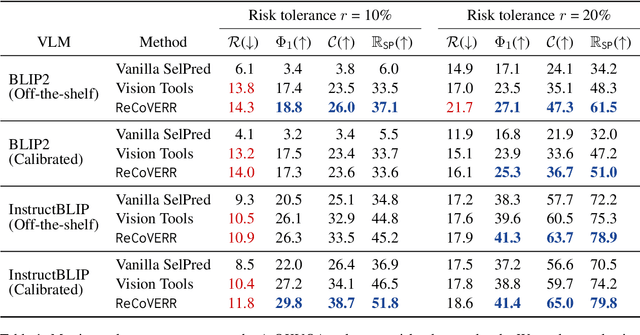

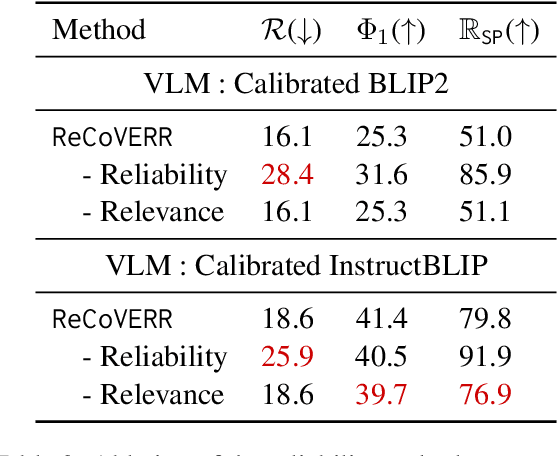
Prior work on selective prediction minimizes incorrect predictions from vision-language models (VLMs) by allowing them to abstain from answering when uncertain. However, when deploying a vision-language system with low tolerance for inaccurate predictions, selective prediction may be over-cautious and abstain too frequently, even on many correct predictions. We introduce ReCoVERR, an inference-time algorithm to reduce the over-abstention of a selective vision-language system without decreasing prediction accuracy. When the VLM makes a low-confidence prediction, instead of abstaining ReCoVERR tries to find relevant clues in the image that provide additional evidence for the prediction. ReCoVERR uses an LLM to pose related questions to the VLM, collects high-confidence evidences, and if enough evidence confirms the prediction the system makes a prediction instead of abstaining. ReCoVERR enables two VLMs, BLIP2 and InstructBLIP, to answer up to 20% more questions on the A-OKVQA task than vanilla selective prediction without decreasing system accuracy, thus improving overall system reliability.
OLMo: Accelerating the Science of Language Models
Feb 07, 2024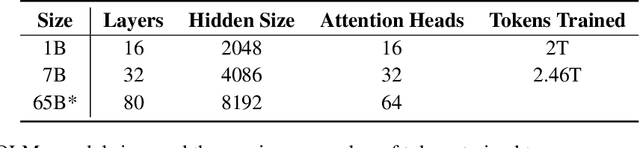
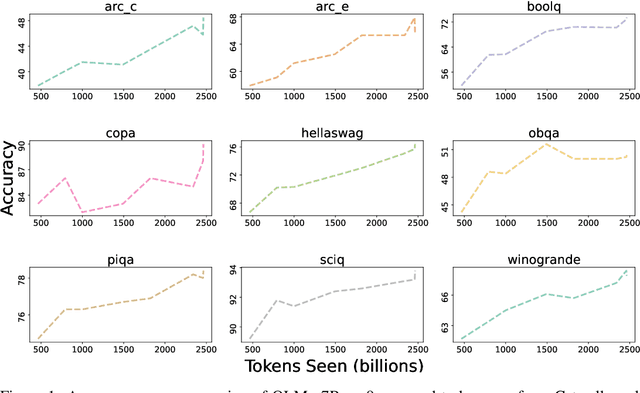
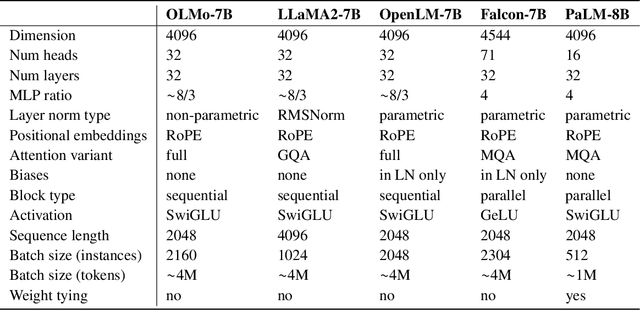
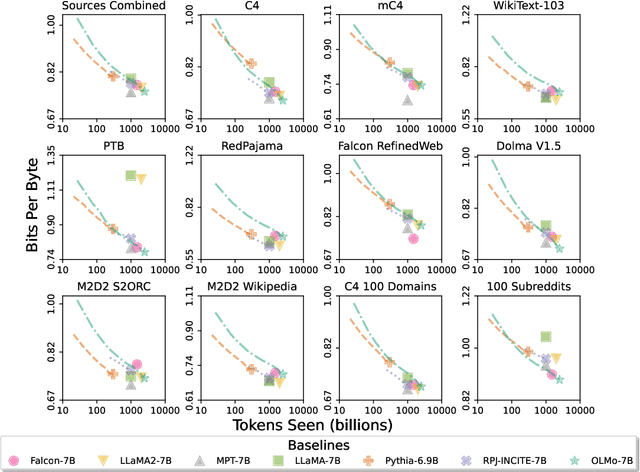
Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, this technical report details the first release of OLMo, a state-of-the-art, truly Open Language Model and its framework to build and study the science of language modeling. Unlike most prior efforts that have only released model weights and inference code, we release OLMo and the whole framework, including training data and training and evaluation code. We hope this release will empower and strengthen the open research community and inspire a new wave of innovation.
Deal, or no deal ? Forecasting Uncertainty in Conversations using Large Language Models
Feb 05, 2024
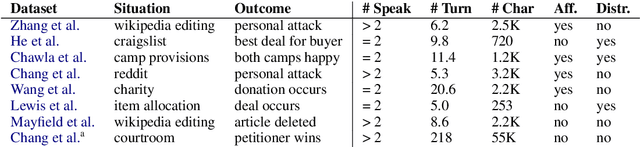

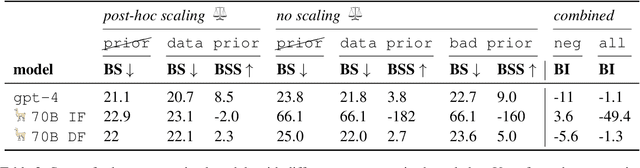
Effective interlocutors account for the uncertain goals, beliefs, and emotions of others. But even the best human conversationalist cannot perfectly anticipate the trajectory of a dialogue. How well can language models represent inherent uncertainty in conversations? We propose FortUne Dial, an expansion of the long-standing "conversation forecasting" task: instead of just accuracy, evaluation is conducted with uncertainty-aware metrics, effectively enabling abstention on individual instances. We study two ways in which language models potentially represent outcome uncertainty (internally, using scores and directly, using tokens) and propose fine-tuning strategies to improve calibration of both representations. Experiments on eight difficult negotiation corpora demonstrate that our proposed fine-tuning strategies (a traditional supervision strategy and an off-policy reinforcement learning strategy) can calibrate smaller open-source models to compete with pre-trained models 10x their size.
Localized Symbolic Knowledge Distillation for Visual Commonsense Models
Dec 12, 2023


Instruction following vision-language (VL) models offer a flexible interface that supports a broad range of multimodal tasks in a zero-shot fashion. However, interfaces that operate on full images do not directly enable the user to "point to" and access specific regions within images. This capability is important not only to support reference-grounded VL benchmarks, but also, for practical applications that require precise within-image reasoning. We build Localized Visual Commonsense models, which allow users to specify (multiple) regions as input. We train our model by sampling localized commonsense knowledge from a large language model (LLM): specifically, we prompt an LLM to collect commonsense knowledge given a global literal image description and a local literal region description automatically generated by a set of VL models. With a separately trained critic model that selects high-quality examples, we find that training on the localized commonsense corpus can successfully distill existing VL models to support a reference-as-input interface. Empirical results and human evaluations in a zero-shot setup demonstrate that our distillation method results in more precise VL models of reasoning compared to a baseline of passing a generated referring expression to an LLM.
How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources
Jun 07, 2023In this work we explore recent advances in instruction-tuning language models on a range of open instruction-following datasets. Despite recent claims that open models can be on par with state-of-the-art proprietary models, these claims are often accompanied by limited evaluation, making it difficult to compare models across the board and determine the utility of various resources. We provide a large set of instruction-tuned models from 6.7B to 65B parameters in size, trained on 12 instruction datasets ranging from manually curated (e.g., OpenAssistant) to synthetic and distilled (e.g., Alpaca) and systematically evaluate them on their factual knowledge, reasoning, multilinguality, coding, and open-ended instruction following abilities through a collection of automatic, model-based, and human-based metrics. We further introduce T\"ulu, our best performing instruction-tuned model suite finetuned on a combination of high-quality open resources. Our experiments show that different instruction-tuning datasets can uncover or enhance specific skills, while no single dataset (or combination) provides the best performance across all evaluations. Interestingly, we find that model and human preference-based evaluations fail to reflect differences in model capabilities exposed by benchmark-based evaluations, suggesting the need for the type of systemic evaluation performed in this work. Our evaluations show that the best model in any given evaluation reaches on average 83% of ChatGPT performance, and 68% of GPT-4 performance, suggesting that further investment in building better base models and instruction-tuning data is required to close the gap. We release our instruction-tuned models, including a fully finetuned 65B T\"ulu, along with our code, data, and evaluation framework at https://github.com/allenai/open-instruct to facilitate future research.