 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Decision-Making for Inline Text Autocomplete
Mar 21, 2024Autocomplete suggestions are fundamental to modern text entry systems, with applications in domains such as messaging and email composition. Typically, autocomplete suggestions are generated from a language model with a confidence threshold. However, this threshold does not directly take into account the cognitive load imposed on the user by surfacing suggestions, such as the effort to switch contexts from typing to reading the suggestion, and the time to decide whether to accept the suggestion. In this paper, we study the problem of improving inline autocomplete suggestions in text entry systems via a sequential decision-making formulation, and use reinforcement learning to learn suggestion policies through repeated interactions with a target user over time. This formulation allows us to factor cognitive load into the objective of training an autocomplete model, through a reward function based on text entry speed. We acquired theoretical and experimental evidence that, under certain objectives, the sequential decision-making formulation of the autocomplete problem provides a better suggestion policy than myopic single-step reasoning. However, aligning these objectives with real users requires further exploration. In particular, we hypothesize that the objectives under which sequential decision-making can improve autocomplete systems are not tailored solely to text entry speed, but more broadly to metrics such as user satisfaction and convenience.
Score Models for Offline Goal-Conditioned Reinforcement Learning
Nov 03, 2023Offline Goal-Conditioned Reinforcement Learning (GCRL) is tasked with learning to achieve multiple goals in an environment purely from offline datasets using sparse reward functions. Offline GCRL is pivotal for developing generalist agents capable of leveraging pre-existing datasets to learn diverse and reusable skills without hand-engineering reward functions. However, contemporary approaches to GCRL based on supervised learning and contrastive learning are often suboptimal in the offline setting. An alternative perspective on GCRL optimizes for occupancy matching, but necessitates learning a discriminator, which subsequently serves as a pseudo-reward for downstream RL. Inaccuracies in the learned discriminator can cascade, negatively influencing the resulting policy. We present a novel approach to GCRL under a new lens of mixture-distribution matching, leading to our discriminator-free method: SMORe. The key insight is combining the occupancy matching perspective of GCRL with a convex dual formulation to derive a learning objective that can better leverage suboptimal offline data. SMORe learns scores or unnormalized densities representing the importance of taking an action at a state for reaching a particular goal. SMORe is principled and our extensive experiments on the fully offline GCRL benchmark composed of robot manipulation and locomotion tasks, including high-dimensional observations, show that SMORe can outperform state-of-the-art baselines by a significant margin.
Sequence Modeling is a Robust Contender for Offline Reinforcement Learning
May 26, 2023Offline reinforcement learning (RL) allows agents to learn effective, return-maximizing policies from a static dataset. Three major paradigms for offline RL are Q-Learning, Imitation Learning, and Sequence Modeling. A key open question is: which paradigm is preferred under what conditions? We study this question empirically by exploring the performance of representative algorithms -- Conservative Q-Learning (CQL), Behavior Cloning (BC), and Decision Transformer (DT) -- across the commonly used D4RL and Robomimic benchmarks. We design targeted experiments to understand their behavior concerning data suboptimality and task complexity. Our key findings are: (1) Sequence Modeling requires more data than Q-Learning to learn competitive policies but is more robust; (2) Sequence Modeling is a substantially better choice than both Q-Learning and Imitation Learning in sparse-reward and low-quality data settings; and (3) Sequence Modeling and Imitation Learning are preferable as task horizon increases, or when data is obtained from human demonstrators. Based on the overall strength of Sequence Modeling, we also investigate architectural choices and scaling trends for DT on Atari and D4RL and make design recommendations. We find that scaling the amount of data for DT by 5x gives a 2.5x average score improvement on Atari.
Curriculum Script Distillation for Multilingual Visual Question Answering
Jan 17, 2023Pre-trained models with dual and cross encoders have shown remarkable success in propelling the landscape of several tasks in vision and language in Visual Question Answering (VQA). However, since they are limited by the requirements of gold annotated data, most of these advancements do not see the light of day in other languages beyond English. We aim to address this problem by introducing a curriculum based on the source and target language translations to finetune the pre-trained models for the downstream task. Experimental results demonstrate that script plays a vital role in the performance of these models. Specifically, we show that target languages that share the same script perform better (~6%) than other languages and mixed-script code-switched languages perform better than their counterparts (~5-12%).
Navigating Connected Memories with a Task-oriented Dialog System
Nov 15, 2022



Recent years have seen an increasing trend in the volume of personal media captured by users, thanks to the advent of smartphones and smart glasses, resulting in large media collections. Despite conversation being an intuitive human-computer interface, current efforts focus mostly on single-shot natural language based media retrieval to aid users query their media and re-live their memories. This severely limits the search functionality as users can neither ask follow-up queries nor obtain information without first formulating a single-turn query. In this work, we propose dialogs for connected memories as a powerful tool to empower users to search their media collection through a multi-turn, interactive conversation. Towards this, we collect a new task-oriented dialog dataset COMET, which contains $11.5k$ user<->assistant dialogs (totaling $103k$ utterances), grounded in simulated personal memory graphs. We employ a resource-efficient, two-phase data collection pipeline that uses: (1) a novel multimodal dialog simulator that generates synthetic dialog flows grounded in memory graphs, and, (2) manual paraphrasing to obtain natural language utterances. We analyze COMET, formulate four main tasks to benchmark meaningful progress, and adopt state-of-the-art language models as strong baselines, in order to highlight the multimodal challenges captured by our dataset.
Tell Your Story: Task-Oriented Dialogs for Interactive Content Creation
Nov 08, 2022
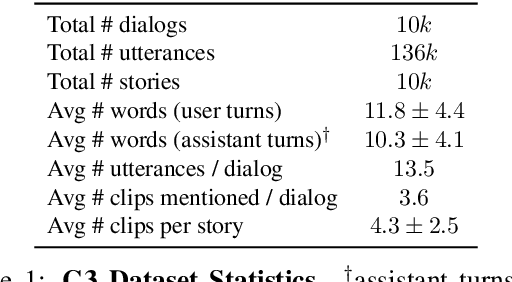


People capture photos and videos to relive and share memories of personal significance. Recently, media montages (stories) have become a popular mode of sharing these memories due to their intuitive and powerful storytelling capabilities. However, creating such montages usually involves a lot of manual searches, clicks, and selections that are time-consuming and cumbersome, adversely affecting user experiences. To alleviate this, we propose task-oriented dialogs for montage creation as a novel interactive tool to seamlessly search, compile, and edit montages from a media collection. To the best of our knowledge, our work is the first to leverage multi-turn conversations for such a challenging application, extending the previous literature studying simple media retrieval tasks. We collect a new dataset C3 (Conversational Content Creation), comprising 10k dialogs conditioned on media montages simulated from a large media collection. We take a simulate-and-paraphrase approach to collect these dialogs to be both cost and time efficient, while drawing from natural language distribution. Our analysis and benchmarking of state-of-the-art language models showcase the multimodal challenges present in the dataset. Lastly, we present a real-world mobile demo application that shows the feasibility of the proposed work in real-world applications. Our code and data will be made publicly available.
Multilingual Multimodality: A Taxonomical Survey of Datasets, Techniques, Challenges and Opportunities
Oct 30, 2022Contextualizing language technologies beyond a single language kindled embracing multiple modalities and languages. Individually, each of these directions undoubtedly proliferated into several NLP tasks. Despite this momentum, most of the multimodal research is primarily centered around English and multilingual research is primarily centered around contexts from text modality. Challenging this conventional setup, researchers studied the unification of multilingual and multimodal (MultiX) streams. The main goal of this work is to catalogue and characterize these works by charting out the categories of tasks, datasets and methods to address MultiX scenarios. To this end, we review the languages studied, gold or silver data with parallel annotations, and understand how these modalities and languages interact in modeling. We present an account of the modeling approaches along with their strengths and weaknesses to better understand what scenarios they can be used reliably. Following this, we present the high-level trends in the overall paradigm of the field. Finally, we conclude by presenting a road map of challenges and promising research directions.
Reinforcement Learning of Multi-Domain Dialog Policies Via Action Embeddings
Jul 01, 2022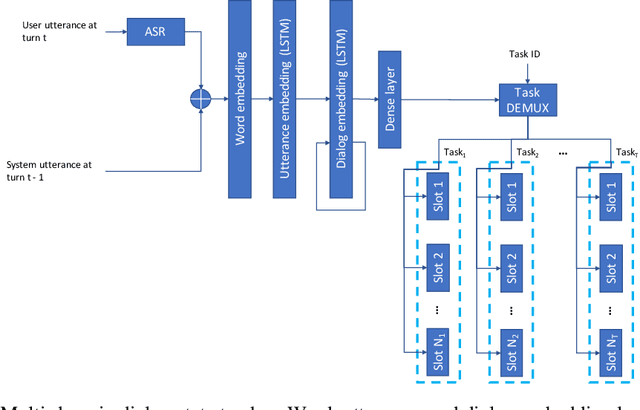
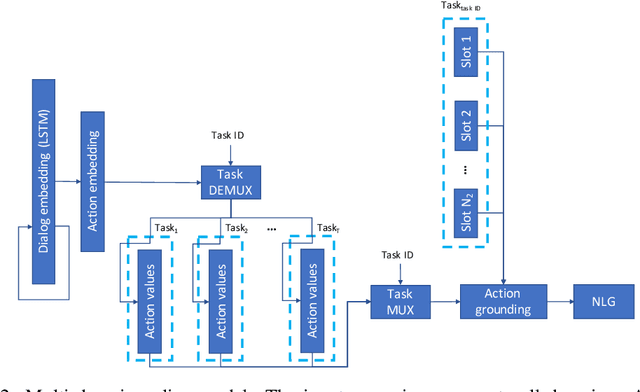
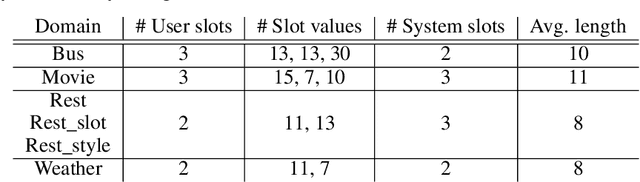
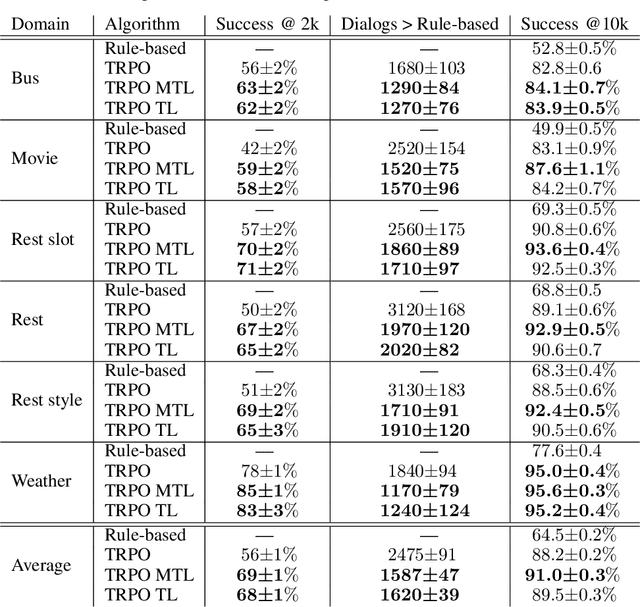
Learning task-oriented dialog policies via reinforcement learning typically requires large amounts of interaction with users, which in practice renders such methods unusable for real-world applications. In order to reduce the data requirements, we propose to leverage data from across different dialog domains, thereby reducing the amount of data required from each given domain. In particular, we propose to learn domain-agnostic action embeddings, which capture general-purpose structure that informs the system how to act given the current dialog context, and are then specialized to a specific domain. We show how this approach is capable of learning with significantly less interaction with users, with a reduction of 35% in the number of dialogs required to learn, and to a higher level of proficiency than training separate policies for each domain on a set of simulated domains.
Database Search Results Disambiguation for Task-Oriented Dialog Systems
Dec 15, 2021


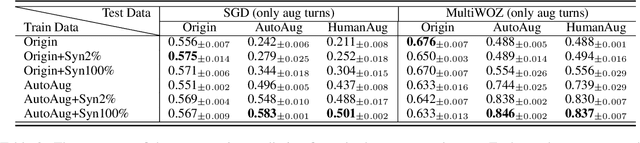
As task-oriented dialog systems are becoming increasingly popular in our lives, more realistic tasks have been proposed and explored. However, new practical challenges arise. For instance, current dialog systems cannot effectively handle multiple search results when querying a database, due to the lack of such scenarios in existing public datasets. In this paper, we propose Database Search Result (DSR) Disambiguation, a novel task that focuses on disambiguating database search results, which enhances user experience by allowing them to choose from multiple options instead of just one. To study this task, we augment the popular task-oriented dialog datasets (MultiWOZ and SGD) with turns that resolve ambiguities by (a) synthetically generating turns through a pre-defined grammar, and (b) collecting human paraphrases for a subset. We find that training on our augmented dialog data improves the model's ability to deal with ambiguous scenarios, without sacrificing performance on unmodified turns. Furthermore, pre-fine tuning and multi-task learning help our model to improve performance on DSR-disambiguation even in the absence of in-domain data, suggesting that it can be learned as a universal dialog skill. Our data and code will be made publicly available.
DAIR: Data Augmented Invariant Regularization
Oct 21, 2021


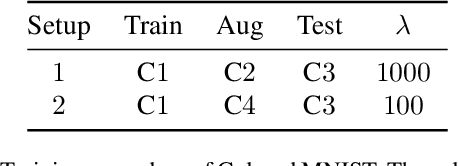
While deep learning through empirical risk minimization (ERM) has succeeded at achieving human-level performance at a variety of complex tasks, ERM generalizes poorly to distribution shift. This is partly explained by overfitting to spurious features such as background in images or named entities in natural language. Synthetic data augmentation followed by empirical risk minimization (DA-ERM) is a simple yet powerful solution to remedy this problem. In this paper, we propose data augmented invariant regularization (DAIR). The idea of DAIR is based on the observation that the model performance (loss) is desired to be consistent on the augmented sample and the original one. DAIR introduces a regularizer on DA-ERM to penalize such loss inconsistency. Both theoretically and through empirical experiments, we show that a particular form of the DAIR regularizer consistently performs well in a variety of settings. We apply it to multiple real-world learning problems involving domain shift, namely robust regression, visual question answering, robust deep neural network training, and task-oriented dialog modeling. Our experiments show that DAIR consistently outperforms ERM and DA-ERM with little marginal cost and setting new state-of-the-art results in several benchmarks.