 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCHR : Goal-Conditioned Hindsight Regularization for Sample-Efficient Reinforcement Learning
Aug 08, 2025



Goal-conditioned reinforcement learning (GCRL) with sparse rewards remains a fundamental challenge in reinforcement learning. While hindsight experience replay (HER) has shown promise by relabeling collected trajectories with achieved goals, we argue that trajectory relabeling alone does not fully exploit the available experiences in off-policy GCRL methods, resulting in limited sample efficiency. In this paper, we propose Hindsight Goal-conditioned Regularization (HGR), a technique that generates action regularization priors based on hindsight goals. When combined with hindsight self-imitation regularization (HSR), our approach enables off-policy RL algorithms to maximize experience utilization. Compared to existing GCRL methods that employ HER and self-imitation techniques, our hindsight regularizations achieve substantially more efficient sample reuse and the best performances, which we empirically demonstrate on a suite of navigation and manipulation tasks.
Segmenting Text and Learning Their Rewards for Improved RLHF in Language Model
Jan 06, 2025Reinforcement learning from human feedback (RLHF) has been widely adopted to align language models (LMs) with human preference. Prior RLHF works typically take a bandit formulation, which, though intuitive, ignores the sequential nature of LM generation and can suffer from the sparse reward issue. While recent works propose dense token-level RLHF, treating each token as an action may be oversubtle to proper reward assignment. In this paper, we seek to get the best of both by training and utilizing a segment-level reward model, which assigns a reward to each semantically complete text segment that spans over a short sequence of tokens. For reward learning, our method allows dynamic text segmentation and compatibility with standard sequence-preference datasets. For effective RL-based LM training against segment reward, we generalize the classical scalar bandit reward normalizers into location-aware normalizer functions and interpolate the segment reward for further densification. With these designs, our method performs competitively on three popular RLHF benchmarks for LM policy: AlpacaEval 2.0, Arena-Hard, and MT-Bench. Ablation studies are conducted to further demonstrate our method.
SWaT: Statistical Modeling of Video Watch Time through User Behavior Analysis
Aug 14, 2024



The significance of estimating video watch time has been highlighted by the rising importance of (short) video recommendation, which has become a core product of mainstream social media platforms. Modeling video watch time, however, has been challenged by the complexity of user-video interaction, such as different user behavior modes in watching the recommended videos and varying watching probabilities over the video horizon. Despite the importance and challenges, existing literature on modeling video watch time mostly focuses on relatively black-box mechanical enhancement of the classical regression/classification losses, without factoring in user behavior in a principled manner. In this paper, we for the first time take on a user-centric perspective to model video watch time, from which we propose a white-box statistical framework that directly translates various user behavior assumptions in watching (short) videos into statistical watch time models. These behavior assumptions are portrayed by our domain knowledge on users' behavior modes in video watching. We further employ bucketization to cope with user's non-stationary watching probability over the video horizon, which additionally helps to respect the constraint of video length and facilitate the practical compatibility between the continuous regression event of watch time and other binary classification events. We test our models extensively on two public datasets, a large-scale offline industrial dataset, and an online A/B test on a short video platform with hundreds of millions of daily-active users. On all experiments, our models perform competitively against strong relevant baselines, demonstrating the efficacy of our user-centric perspective and proposed framework.
Sequential Decision-Making for Inline Text Autocomplete
Mar 21, 2024Autocomplete suggestions are fundamental to modern text entry systems, with applications in domains such as messaging and email composition. Typically, autocomplete suggestions are generated from a language model with a confidence threshold. However, this threshold does not directly take into account the cognitive load imposed on the user by surfacing suggestions, such as the effort to switch contexts from typing to reading the suggestion, and the time to decide whether to accept the suggestion. In this paper, we study the problem of improving inline autocomplete suggestions in text entry systems via a sequential decision-making formulation, and use reinforcement learning to learn suggestion policies through repeated interactions with a target user over time. This formulation allows us to factor cognitive load into the objective of training an autocomplete model, through a reward function based on text entry speed. We acquired theoretical and experimental evidence that, under certain objectives, the sequential decision-making formulation of the autocomplete problem provides a better suggestion policy than myopic single-step reasoning. However, aligning these objectives with real users requires further exploration. In particular, we hypothesize that the objectives under which sequential decision-making can improve autocomplete systems are not tailored solely to text entry speed, but more broadly to metrics such as user satisfaction and convenience.
A Dense Reward View on Aligning Text-to-Image Diffusion with Preference
Feb 13, 2024Aligning text-to-image diffusion model (T2I) with preference has been gaining increasing research attention. While prior works exist on directly optimizing T2I by preference data, these methods are developed under the bandit assumption of a latent reward on the entire diffusion reverse chain, while ignoring the sequential nature of the generation process. From literature, this may harm the efficacy and efficiency of alignment. In this paper, we take on a finer dense reward perspective and derive a tractable alignment objective that emphasizes the initial steps of the T2I reverse chain. In particular, we introduce temporal discounting into the DPO-style explicit-reward-free loss, to break the temporal symmetry therein and suit the T2I generation hierarchy. In experiments on single and multiple prompt generation, our method is competitive with strong relevant baselines, both quantitatively and qualitatively. Further studies are conducted to illustrate the insight of our approach.
Preference-grounded Token-level Guidance for Language Model Fine-tuning
Jun 01, 2023



Aligning language models (LMs) with preferences is an important problem in natural language generation. A key challenge is that preferences are typically provided at the sequence level while LM training and generation both occur at the token level. There is, therefore, a granularity mismatch between the preference and the LM training losses, which may complicate the learning problem. In this paper, we address this issue by developing an alternate training process, where we iterate between grounding the sequence-level preference into token-level training guidance, and improving the LM with the learned guidance. For guidance learning, we design a framework that extends the pairwise-preference learning in imitation learning to both variable-length LM generation and utilizing the preference among multiple generations. For LM training, based on the amount of supervised data, we present two minimalist learning objectives that utilize the learned guidance. In experiments, our method performs competitively on two distinct representative LM tasks -- discrete-prompt generation and text summarization.
Fantastic Rewards and How to Tame Them: A Case Study on Reward Learning for Task-oriented Dialogue Systems
Feb 20, 2023When learning task-oriented dialogue (ToD) agents, reinforcement learning (RL) techniques can naturally be utilized to train dialogue strategies to achieve user-specific goals. Prior works mainly focus on adopting advanced RL techniques to train the ToD agents, while the design of the reward function is not well studied. This paper aims at answering the question of how to efficiently learn and leverage a reward function for training end-to-end (E2E) ToD agents. Specifically, we introduce two generalized objectives for reward-function learning, inspired by the classical learning-to-rank literature. Further, we utilize the learned reward function to guide the training of the E2E ToD agent. With the proposed techniques, we achieve competitive results on the E2E response-generation task on the Multiwoz 2.0 dataset. Source code and checkpoints are publicly released at https://github.com/Shentao-YANG/Fantastic_Reward_ICLR2023.
A Unified Framework for Alternating Offline Model Training and Policy Learning
Oct 12, 2022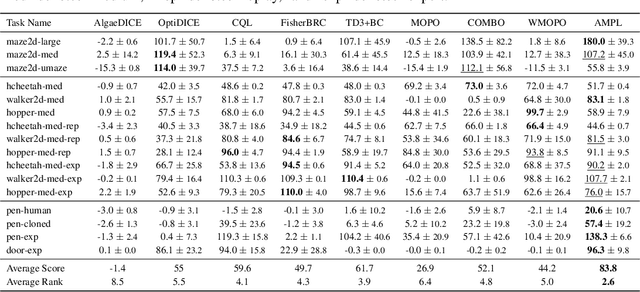
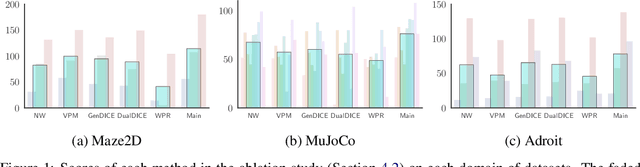
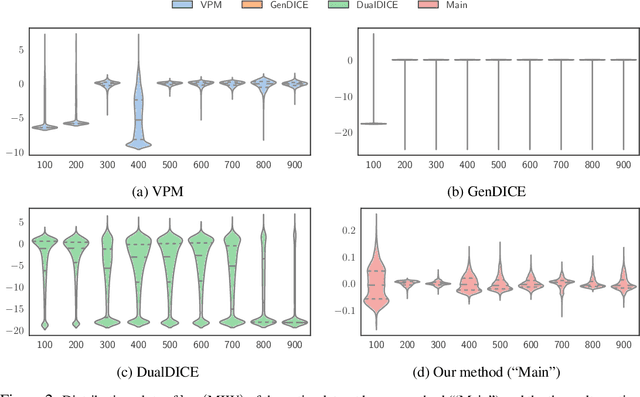
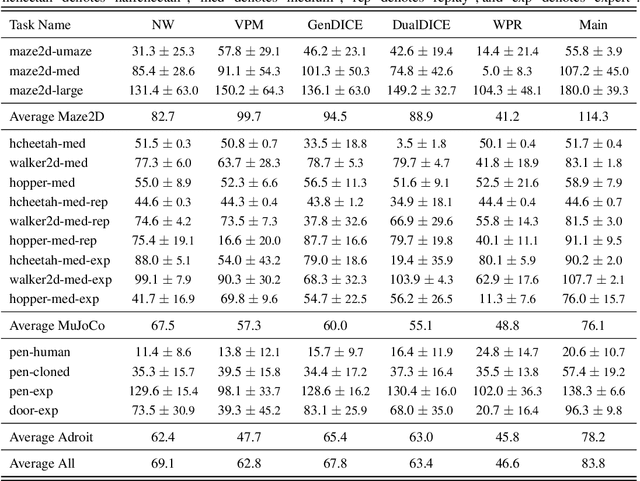
In offline model-based reinforcement learning (offline MBRL), we learn a dynamic model from historically collected data, and subsequently utilize the learned model and fixed datasets for policy learning, without further interacting with the environment. Offline MBRL algorithms can improve the efficiency and stability of policy learning over the model-free algorithms. However, in most of the existing offline MBRL algorithms, the learning objectives for the dynamic models and the policies are isolated from each other. Such an objective mismatch may lead to inferior performance of the learned agents. In this paper, we address this issue by developing an iterative offline MBRL framework, where we maximize a lower bound of the true expected return, by alternating between dynamic-model training and policy learning. With the proposed unified model-policy learning framework, we achieve competitive performance on a wide range of continuous-control offline reinforcement learning datasets. Source code is publicly released.
Regularizing a Model-based Policy Stationary Distribution to Stabilize Offline Reinforcement Learning
Jun 14, 2022
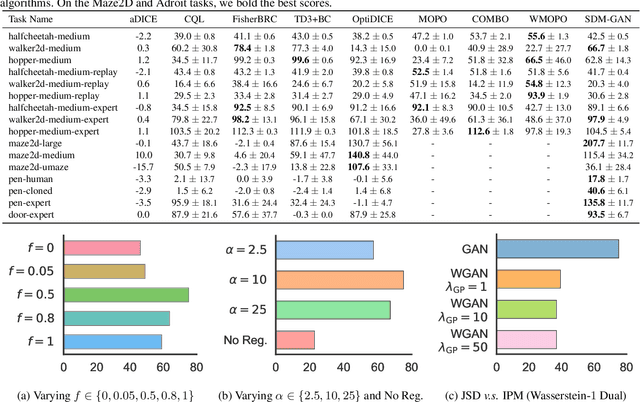
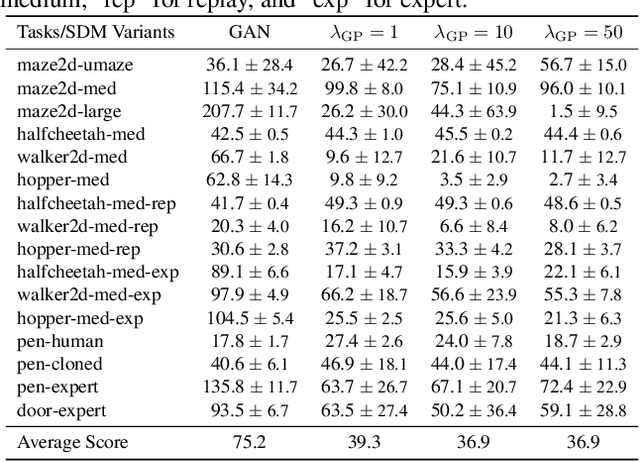
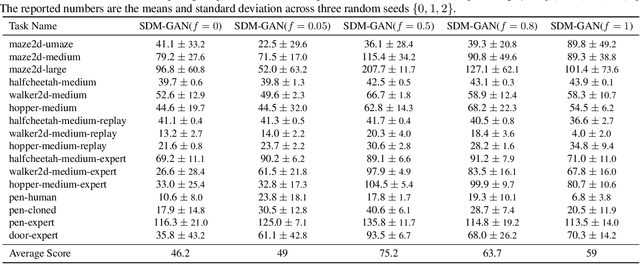
Offline reinforcement learning (RL) extends the paradigm of classical RL algorithms to purely learning from static datasets, without interacting with the underlying environment during the learning process. A key challenge of offline RL is the instability of policy training, caused by the mismatch between the distribution of the offline data and the undiscounted stationary state-action distribution of the learned policy. To avoid the detrimental impact of distribution mismatch, we regularize the undiscounted stationary distribution of the current policy towards the offline data during the policy optimization process. Further, we train a dynamics model to both implement this regularization and better estimate the stationary distribution of the current policy, reducing the error induced by distribution mismatch. On a wide range of continuous-control offline RL datasets, our method indicates competitive performance, which validates our algorithm. The code is publicly available.
A Regularized Implicit Policy for Offline Reinforcement Learning
Feb 19, 2022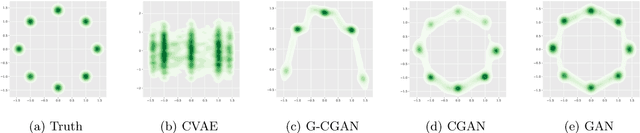
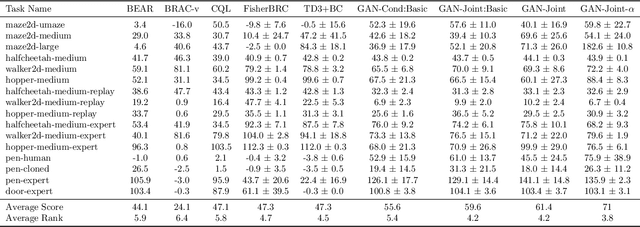
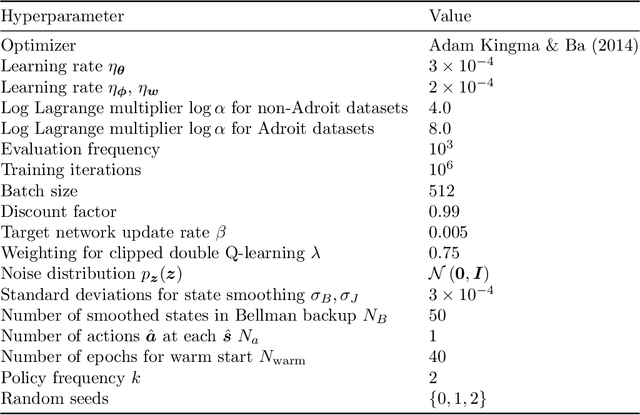
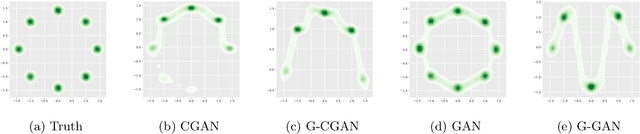
Offline reinforcement learning enables learning from a fixed dataset, without further interactions with the environment. The lack of environmental interactions makes the policy training vulnerable to state-action pairs far from the training dataset and prone to missing rewarding actions. For training more effective agents, we propose a framework that supports learning a flexible yet well-regularized fully-implicit policy. We further propose a simple modification to the classical policy-matching methods for regularizing with respect to the dual form of the Jensen--Shannon divergence and the integral probability metrics. We theoretically show the correctness of the policy-matching approach, and the correctness and a good finite-sample property of our modification. An effective instantiation of our framework through the GAN structure is provided, together with techniques to explicitly smooth the state-action mapping for robust generalization beyond the static dataset. Extensive experiments and ablation study on the D4RL dataset validate our framework and the effectiveness of our algorithmic designs.