 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Benchmarking LLMs for Political Science: A United Nations Perspective
Feb 19, 2025Large Language Models (LLMs) have achieved significant advances in natural language processing, yet their potential for high-stake political decision-making remains largely unexplored. This paper addresses the gap by focusing on the application of LLMs to the United Nations (UN) decision-making process, where the stakes are particularly high and political decisions can have far-reaching consequences. We introduce a novel dataset comprising publicly available UN Security Council (UNSC) records from 1994 to 2024, including draft resolutions, voting records, and diplomatic speeches. Using this dataset, we propose the United Nations Benchmark (UNBench), the first comprehensive benchmark designed to evaluate LLMs across four interconnected political science tasks: co-penholder judgment, representative voting simulation, draft adoption prediction, and representative statement generation. These tasks span the three stages of the UN decision-making process--drafting, voting, and discussing--and aim to assess LLMs' ability to understand and simulate political dynamics. Our experimental analysis demonstrates the potential and challenges of applying LLMs in this domain, providing insights into their strengths and limitations in political science. This work contributes to the growing intersection of AI and political science, opening new avenues for research and practical applications in global governance. The UNBench Repository can be accessed at: https://github.com/yueqingliang1/UNBench.
ProjectTest: A Project-level LLM Unit Test Generation Benchmark and Impact of Error Fixing Mechanisms
Feb 11, 2025



Unit test generation has become a promising and important use case of LLMs. However, existing evaluation benchmarks for assessing LLM unit test generation capabilities focus on function- or class-level code rather than more practical and challenging project-level codebases. To address such limitation, we propose ProjectTest, a project-level benchmark for unit test generation covering Python, Java, and JavaScript. ProjectTest features 20 moderate-sized and high-quality projects per language. We evaluate nine frontier LLMs on ProjectTest and the results show that all frontier LLMs tested exhibit moderate performance on ProjectTest on Python and Java, highlighting the difficulty of ProjectTest. We also conduct a thorough error analysis, which shows that even frontier LLMs, such as Claude-3.5-Sonnet, have significant simple errors, including compilation and cascade errors. Motivated by this observation, we further evaluate all frontier LLMs under manual error-fixing and self-error-fixing scenarios to assess their potential when equipped with error-fixing mechanisms.
ProjectTest: A Project-level Unit Test Generation Benchmark and Impact of Error Fixing Mechanisms
Feb 10, 2025Unit test generation has become a promising and important use case of LLMs. However, existing evaluation benchmarks for assessing LLM unit test generation capabilities focus on function- or class-level code rather than more practical and challenging project-level codebases. To address such limitation, we propose ProjectTest, a project-level benchmark for unit test generation covering Python, Java, and JavaScript. ProjectTest features 20 moderate-sized and high-quality projects per language. We evaluate nine frontier LLMs on ProjectTest and the results show that all frontier LLMs tested exhibit moderate performance on ProjectTest on Python and Java, highlighting the difficulty of ProjectTest. We also conduct a thorough error analysis, which shows that even frontier LLMs, such as Claude-3.5-Sonnet, have significant simple errors, including compilation and cascade errors. Motivated by this observation, we further evaluate all frontier LLMs under manual error-fixing and self-error-fixing scenarios to assess their potential when equipped with error-fixing mechanisms.
AAAR-1.0: Assessing AI's Potential to Assist Research
Oct 29, 2024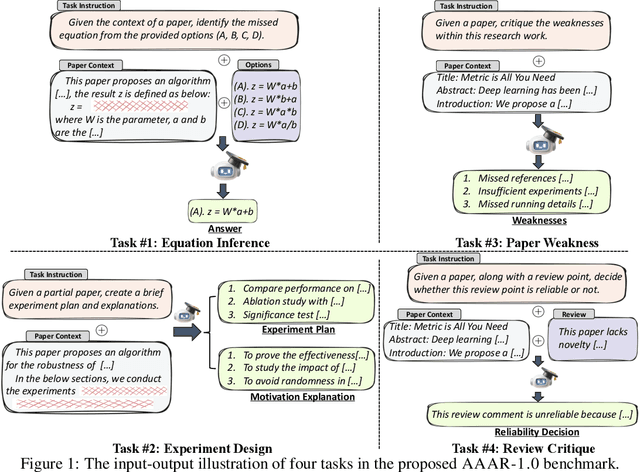
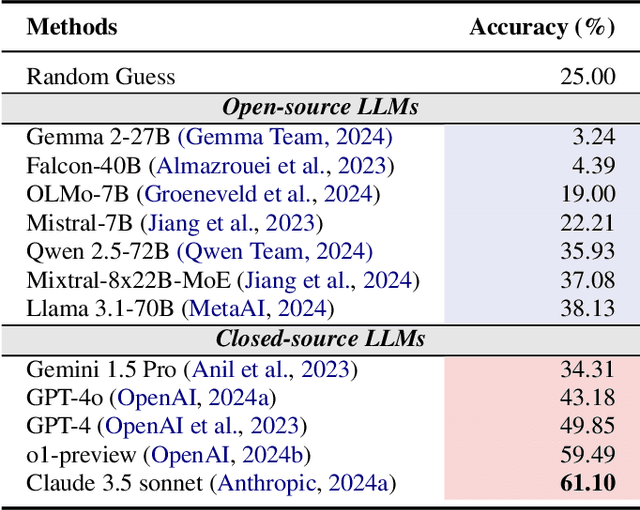
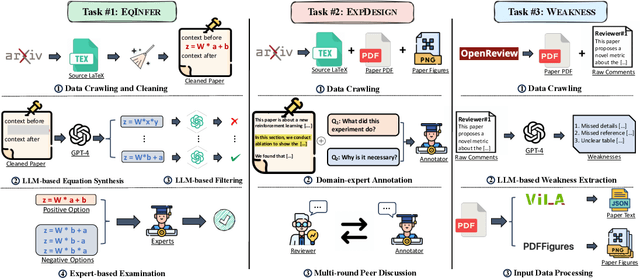
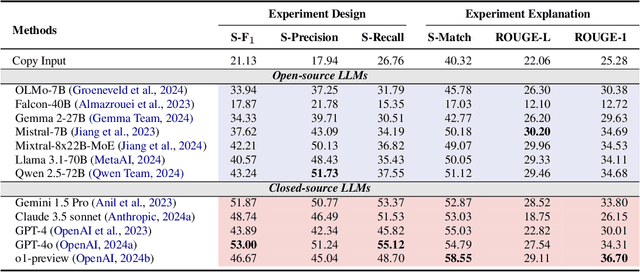
Numerous studies have assessed the proficiency of AI systems, particularly large language models (LLMs), in facilitating everyday tasks such as email writing, question answering, and creative content generation. However, researchers face unique challenges and opportunities in leveraging LLMs for their own work, such as brainstorming research ideas, designing experiments, and writing or reviewing papers. In this study, we introduce AAAR-1.0, a benchmark dataset designed to evaluate LLM performance in three fundamental, expertise-intensive research tasks: (i) EquationInference, assessing the correctness of equations based on the contextual information in paper submissions; (ii) ExperimentDesign, designing experiments to validate research ideas and solutions; (iii) PaperWeakness, identifying weaknesses in paper submissions; and (iv) REVIEWCRITIQUE, identifying each segment in human reviews is deficient or not. AAAR-1.0 differs from prior benchmarks in two key ways: first, it is explicitly research-oriented, with tasks requiring deep domain expertise; second, it is researcher-oriented, mirroring the primary activities that researchers engage in on a daily basis. An evaluation of both open-source and proprietary LLMs reveals their potential as well as limitations in conducting sophisticated research tasks. We will keep iterating AAAR-1.0 to new versions.
ReGenesis: LLMs can Grow into Reasoning Generalists via Self-Improvement
Oct 03, 2024Post-training Large Language Models (LLMs) with explicit reasoning trajectories can enhance their reasoning abilities. However, acquiring such high-quality trajectory data typically demands meticulous supervision from humans or superior models, which can be either expensive or license-constrained. In this paper, we explore how far an LLM can improve its reasoning by self-synthesizing reasoning paths as training data without any additional supervision. Existing self-synthesizing methods, such as STaR, suffer from poor generalization to out-of-domain (OOD) reasoning tasks. We hypothesize it is due to that their self-synthesized reasoning paths are too task-specific, lacking general task-agnostic reasoning guidance. To address this, we propose Reasoning Generalist via Self-Improvement (ReGenesis), a method to self-synthesize reasoning paths as post-training data by progressing from abstract to concrete. More specifically, ReGenesis self-synthesizes reasoning paths by converting general reasoning guidelines into task-specific ones, generating reasoning structures, and subsequently transforming these structures into reasoning paths, without the need for human-designed task-specific examples used in existing methods. We show that ReGenesis achieves superior performance on all in-domain and OOD settings tested compared to existing methods. For six OOD tasks specifically, while previous methods exhibited an average performance decrease of approximately 4.6% after post training, ReGenesis delivers around 6.1% performance improvement. We also conduct in-depth analysis of our framework and show ReGenesis is effective across various LLMs and design choices.
xGen-VideoSyn-1: High-fidelity Text-to-Video Synthesis with Compressed Representations
Aug 22, 2024



We present xGen-VideoSyn-1, a text-to-video (T2V) generation model capable of producing realistic scenes from textual descriptions. Building on recent advancements, such as OpenAI's Sora, we explore the latent diffusion model (LDM) architecture and introduce a video variational autoencoder (VidVAE). VidVAE compresses video data both spatially and temporally, significantly reducing the length of visual tokens and the computational demands associated with generating long-sequence videos. To further address the computational costs, we propose a divide-and-merge strategy that maintains temporal consistency across video segments. Our Diffusion Transformer (DiT) model incorporates spatial and temporal self-attention layers, enabling robust generalization across different timeframes and aspect ratios. We have devised a data processing pipeline from the very beginning and collected over 13M high-quality video-text pairs. The pipeline includes multiple steps such as clipping, text detection, motion estimation, aesthetics scoring, and dense captioning based on our in-house video-LLM model. Training the VidVAE and DiT models required approximately 40 and 642 H100 days, respectively. Our model supports over 14-second 720p video generation in an end-to-end way and demonstrates competitive performance against state-of-the-art T2V models.
LLMs Assist NLP Researchers: Critique Paper (Meta-)Reviewing
Jun 25, 2024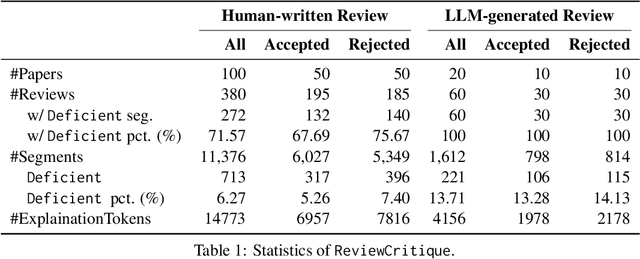
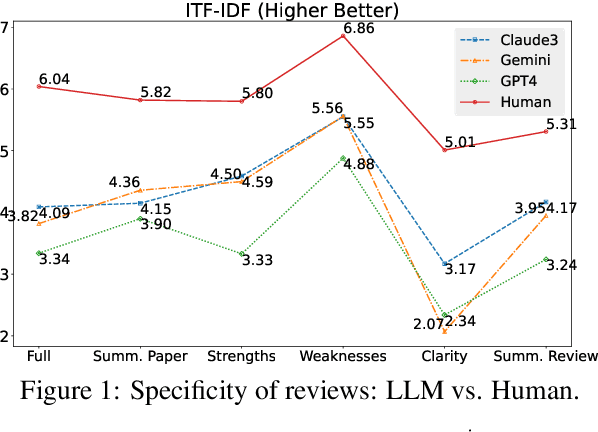

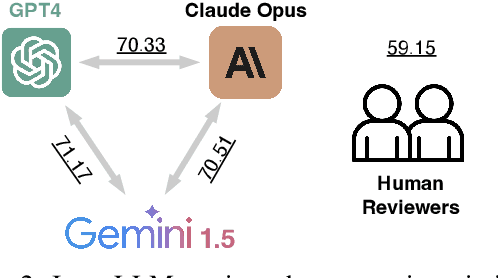
This work is motivated by two key trends. On one hand, large language models (LLMs) have shown remarkable versatility in various generative tasks such as writing, drawing, and question answering, significantly reducing the time required for many routine tasks. On the other hand, researchers, whose work is not only time-consuming but also highly expertise-demanding, face increasing challenges as they have to spend more time reading, writing, and reviewing papers. This raises the question: how can LLMs potentially assist researchers in alleviating their heavy workload? This study focuses on the topic of LLMs assist NLP Researchers, particularly examining the effectiveness of LLM in assisting paper (meta-)reviewing and its recognizability. To address this, we constructed the ReviewCritique dataset, which includes two types of information: (i) NLP papers (initial submissions rather than camera-ready) with both human-written and LLM-generated reviews, and (ii) each review comes with "deficiency" labels and corresponding explanations for individual segments, annotated by experts. Using ReviewCritique, this study explores two threads of research questions: (i) "LLMs as Reviewers", how do reviews generated by LLMs compare with those written by humans in terms of quality and distinguishability? (ii) "LLMs as Metareviewers", how effectively can LLMs identify potential issues, such as Deficient or unprofessional review segments, within individual paper reviews? To our knowledge, this is the first work to provide such a comprehensive analysis.
FOFO: A Benchmark to Evaluate LLMs' Format-Following Capability
Feb 28, 2024This paper presents FoFo, a pioneering benchmark for evaluating large language models' (LLMs) ability to follow complex, domain-specific formats, a crucial yet underexamined capability for their application as AI agents. Despite LLMs' advancements, existing benchmarks fail to assess their format-following proficiency adequately. FoFo fills this gap with a diverse range of real-world formats and instructions, developed through an AI-Human collaborative method. Our evaluation across both open-source (e.g., Llama 2, WizardLM) and closed-source (e.g., GPT-4, PALM2, Gemini) LLMs highlights three key findings: open-source models significantly lag behind closed-source ones in format adherence; LLMs' format-following performance is independent of their content generation quality; and LLMs' format proficiency varies across different domains. These insights suggest the need for specialized tuning for format-following skills and highlight FoFo's role in guiding the selection of domain-specific AI agents. FoFo is released here at https://github.com/SalesforceAIResearch/FoFo.
All Labels Together: Low-shot Intent Detection with an Efficient Label Semantic Encoding Paradigm
Sep 08, 2023



In intent detection tasks, leveraging meaningful semantic information from intent labels can be particularly beneficial for few-shot scenarios. However, existing few-shot intent detection methods either ignore the intent labels, (e.g. treating intents as indices) or do not fully utilize this information (e.g. only using part of the intent labels). In this work, we present an end-to-end One-to-All system that enables the comparison of an input utterance with all label candidates. The system can then fully utilize label semantics in this way. Experiments on three few-shot intent detection tasks demonstrate that One-to-All is especially effective when the training resource is extremely scarce, achieving state-of-the-art performance in 1-, 3- and 5-shot settings. Moreover, we present a novel pretraining strategy for our model that utilizes indirect supervision from paraphrasing, enabling zero-shot cross-domain generalization on intent detection tasks. Our code is at https://github.com/jiangshdd/AllLablesTogether.