 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Language Feedback via Variational Policy Distillation
May 14, 2026Reinforcement learning from verifiable rewards (RLVR) suffers from sparse outcome signals, creating severe exploration bottlenecks on complex reasoning tasks. Recent on-policy self-distillation methods attempt to address this by utilizing language feedback to generate dense, token-level supervision. However, these approaches rely on a fixed, passive teacher to interpret the feedback. As the student policy improves, the teacher's zero-shot assessment capabilities plateau, ultimately halting further learning. To overcome this, we propose Variational Policy Distillation (VPD), a framework that formalizes learning from language feedback as a Variational Expectation-Maximization (EM) problem. VPD co-evolves both policies: in the E-step, the teacher is actively refined on trajectory outcomes via an adaptive trust-region update, translating textual feedback into a dynamically improved target token distribution. In the M-step, the student internalizes this dense distributional guidance on its own on-policy rollouts. By continuously improving the teacher's ability to extract actionable signals from textual critique, VPD overcomes the limitations of passive distillation. Evaluated across diverse sources of diagnostic feedback on scientific reasoning and code generation tasks, VPD consistently outperforms both standard RLVR and existing self-distillation baselines. Finally, by stress-testing our framework on rigid mathematical reasoning and cold-start regimes, we illuminate the fundamental bounds of feedback-driven self-distillation compared to pure environment-driven RL.
Convomem Benchmark: Why Your First 150 Conversations Don't Need RAG
Nov 13, 2025We introduce a comprehensive benchmark for conversational memory evaluation containing 75,336 question-answer pairs across diverse categories including user facts, assistant recall, abstention, preferences, temporal changes, and implicit connections. While existing benchmarks have advanced the field, our work addresses fundamental challenges in statistical power, data generation consistency, and evaluation flexibility that limit current memory evaluation frameworks. We examine the relationship between conversational memory and retrieval-augmented generation (RAG). While these systems share fundamental architectural patterns--temporal reasoning, implicit extraction, knowledge updates, and graph representations--memory systems have a unique characteristic: they start from zero and grow progressively with each conversation. This characteristic enables naive approaches that would be impractical for traditional RAG. Consistent with recent findings on long context effectiveness, we observe that simple full-context approaches achieve 70-82% accuracy even on our most challenging multi-message evidence cases, while sophisticated RAG-based memory systems like Mem0 achieve only 30-45% when operating on conversation histories under 150 interactions. Our analysis reveals practical transition points: long context excels for the first 30 conversations, remains viable with manageable trade-offs up to 150 conversations, and typically requires hybrid or RAG approaches beyond that point as costs and latencies become prohibitive. These patterns indicate that the small-corpus advantage of conversational memory--where exhaustive search and complete reranking are feasible--deserves dedicated research attention rather than simply applying general RAG solutions to conversation histories.
xGen-small Technical Report
May 10, 2025



We introduce xGen-small, a family of 4B and 9B Transformer decoder models optimized for long-context applications. Our vertically integrated pipeline unites domain-balanced, frequency-aware data curation; multi-stage pre-training with quality annealing and length extension to 128k tokens; and targeted post-training via supervised fine-tuning, preference learning, and online reinforcement learning. xGen-small delivers strong performance across various tasks, especially in math and coding domains, while excelling at long context benchmarks.
XGen-7B Technical Report
Sep 07, 2023Large Language Models (LLMs) have become ubiquitous across various domains, transforming the way we interact with information and conduct research. However, most high-performing LLMs remain confined behind proprietary walls, hindering scientific progress. Most open-source LLMs, on the other hand, are limited in their ability to support longer sequence lengths, which is a key requirement for many tasks that require inference over an input context. To address this, we have trained XGen, a series of 7B parameter models on up to 8K sequence length for up to 1.5T tokens. We have also finetuned the XGen models on public-domain instructional data, creating their instruction-tuned counterparts (XGen-Inst). We open-source our models for both research advancements and commercial applications. Our evaluation on standard benchmarks shows that XGen models achieve comparable or better results when compared with state-of-the-art open-source LLMs. Our targeted evaluation on long sequence modeling tasks shows the benefits of our 8K-sequence models over 2K-sequence open-source LLMs.
CodeGen2: Lessons for Training LLMs on Programming and Natural Languages
May 03, 2023



Large language models (LLMs) have demonstrated remarkable abilities in representation learning for program synthesis and understanding tasks. The quality of the learned representations appears to be dictated by the neural scaling laws as a function of the number of model parameters and observations, while imposing upper bounds on the model performance by the amount of available data and compute, which is costly. In this study, we attempt to render the training of LLMs for program synthesis more efficient by unifying four key components: (1) model architectures, (2) learning methods, (3) infill sampling, and, (4) data distributions. Specifically, for the model architecture, we attempt to unify encoder and decoder-based models into a single prefix-LM. For learning methods, (i) causal language modeling, (ii) span corruption, (iii) infilling are unified into a simple learning algorithm. For infill sampling, we explore the claim of a "free lunch" hypothesis. For data distributions, the effect of a mixture distribution of programming and natural languages on model performance is explored. We conduct a comprehensive series of empirical experiments on 1B LLMs, for which failures and successes of this exploration are distilled into four lessons. We will provide a final recipe for training and release CodeGen2 models in size 1B, 3.7B, 7B, and, 16B parameters, along with the training framework as open-source: https://github.com/salesforce/CodeGen2.
Generating High Fidelity Synthetic Data via Coreset selection and Entropic Regularization
Jan 31, 2023


Generative models have the ability to synthesize data points drawn from the data distribution, however, not all generated samples are high quality. In this paper, we propose using a combination of coresets selection methods and ``entropic regularization'' to select the highest fidelity samples. We leverage an Energy-Based Model which resembles a variational auto-encoder with an inference and generator model for which the latent prior is complexified by an energy-based model. In a semi-supervised learning scenario, we show that augmenting the labeled data-set, by adding our selected subset of samples, leads to better accuracy improvement rather than using all the synthetic samples.
Learning Probabilistic Models from Generator Latent Spaces with Hat EBM
Oct 29, 2022



This work proposes a method for using any generator network as the foundation of an Energy-Based Model (EBM). Our formulation posits that observed images are the sum of unobserved latent variables passed through the generator network and a residual random variable that spans the gap between the generator output and the image manifold. One can then define an EBM that includes the generator as part of its forward pass, which we call the Hat EBM. The model can be trained without inferring the latent variables of the observed data or calculating the generator Jacobian determinant. This enables explicit probabilistic modeling of the output distribution of any type of generator network. Experiments show strong performance of the proposed method on (1) unconditional ImageNet synthesis at 128x128 resolution, (2) refining the output of existing generators, and (3) learning EBMs that incorporate non-probabilistic generators. Code and pretrained models to reproduce our results are available at https://github.com/point0bar1/hat-ebm.
BigIssue: A Realistic Bug Localization Benchmark
Jul 21, 2022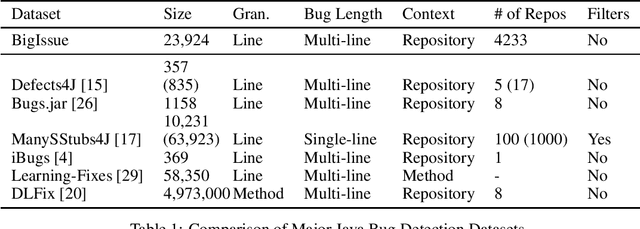



As machine learning tools progress, the inevitable question arises: How can machine learning help us write better code? With significant progress being achieved in natural language processing with models like GPT-3 and Bert, the applications of natural language processing techniques to code are starting to be explored. Most of the research has been focused on automatic program repair (APR), and while the results on synthetic or highly filtered datasets are promising, such models are hard to apply in real-world scenarios because of inadequate bug localization. We propose BigIssue: a benchmark for realistic bug localization. The goal of the benchmark is two-fold. We provide (1) a general benchmark with a diversity of real and synthetic Java bugs and (2) a motivation to improve bug localization capabilities of models through attention to the full repository context. With the introduction of BigIssue, we hope to advance the state of the art in bug localization, in turn improving APR performance and increasing its applicability to the modern development cycle.
ProGen2: Exploring the Boundaries of Protein Language Models
Jun 27, 2022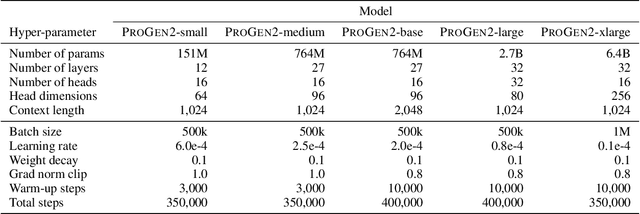
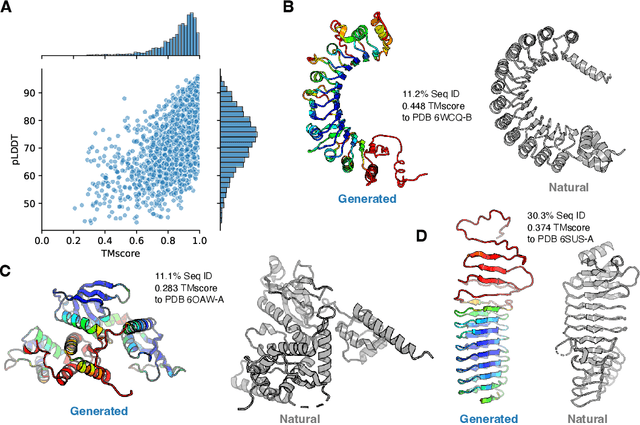
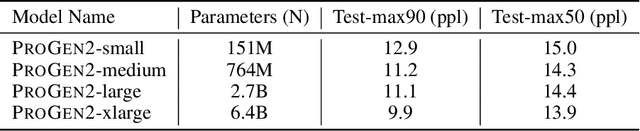
Attention-based models trained on protein sequences have demonstrated incredible success at classification and generation tasks relevant for artificial intelligence-driven protein design. However, we lack a sufficient understanding of how very large-scale models and data play a role in effective protein model development. We introduce a suite of protein language models, named ProGen2, that are scaled up to 6.4B parameters and trained on different sequence datasets drawn from over a billion proteins from genomic, metagenomic, and immune repertoire databases. ProGen2 models show state-of-the-art performance in capturing the distribution of observed evolutionary sequences, generating novel viable sequences, and predicting protein fitness without additional finetuning. As large model sizes and raw numbers of protein sequences continue to become more widely accessible, our results suggest that a growing emphasis needs to be placed on the data distribution provided to a protein sequence model. We release the ProGen2 models and code at https://github.com/salesforce/progen.
A Conversational Paradigm for Program Synthesis
Mar 30, 2022
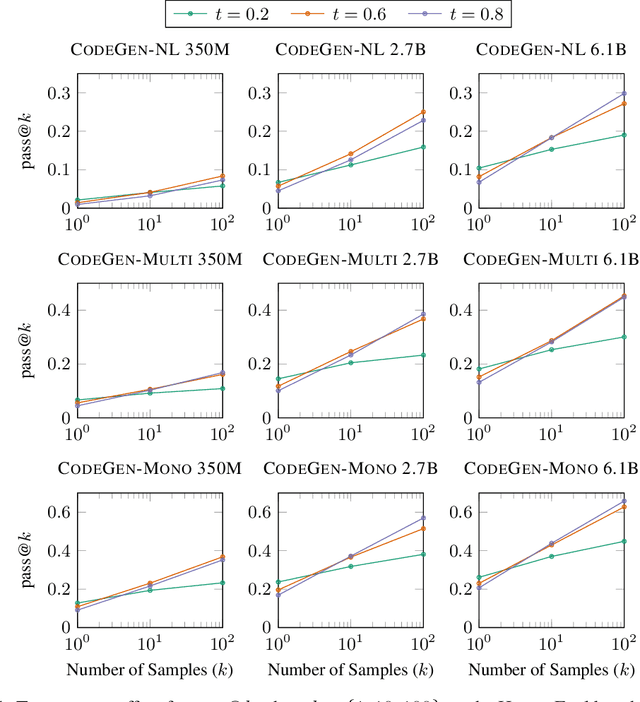
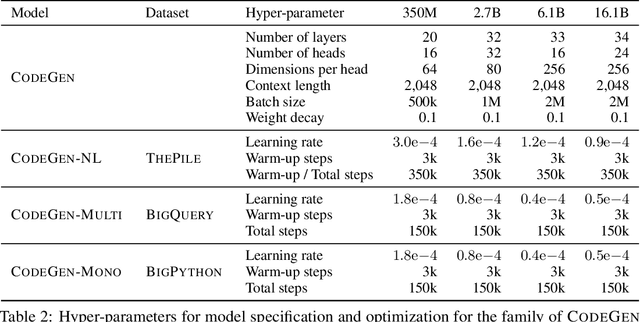
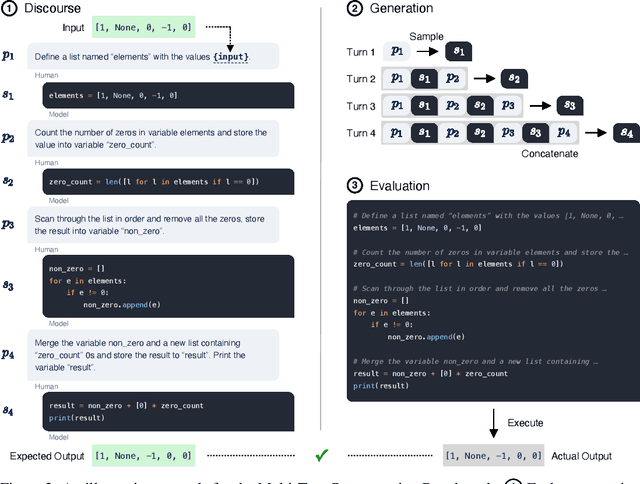
Program synthesis strives to generate a computer program as a solution to a given problem specification. We propose a conversational program synthesis approach via large language models, which addresses the challenges of searching over a vast program space and user intent specification faced in prior approaches. Our new approach casts the process of writing a specification and program as a multi-turn conversation between a user and a system. It treats program synthesis as a sequence prediction problem, in which the specification is expressed in natural language and the desired program is conditionally sampled. We train a family of large language models, called CodeGen, on natural language and programming language data. With weak supervision in the data and the scaling up of data size and model size, conversational capacities emerge from the simple autoregressive language modeling. To study the model behavior on conversational program synthesis, we develop a multi-turn programming benchmark (MTPB), where solving each problem requires multi-step synthesis via multi-turn conversation between the user and the model. Our findings show the emergence of conversational capabilities and the effectiveness of the proposed conversational program synthesis paradigm. In addition, our model CodeGen (with up to 16B parameters trained on TPU-v4) outperforms OpenAI's Codex on the HumanEval benchmark. We make the training library JaxFormer including checkpoints available as open source contribution: https://github.com/salesforce/CodeGen.