 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexGen-small Technical Report
May 10, 2025



We introduce xGen-small, a family of 4B and 9B Transformer decoder models optimized for long-context applications. Our vertically integrated pipeline unites domain-balanced, frequency-aware data curation; multi-stage pre-training with quality annealing and length extension to 128k tokens; and targeted post-training via supervised fine-tuning, preference learning, and online reinforcement learning. xGen-small delivers strong performance across various tasks, especially in math and coding domains, while excelling at long context benchmarks.
CLOVER: A Test Case Generation Benchmark with Coverage, Long-Context, and Verification
Feb 12, 2025Software testing is a critical aspect of software development, yet generating test cases remains a routine task for engineers. This paper presents a benchmark, CLOVER, to evaluate models' capabilities in generating and completing test cases under specific conditions. Spanning from simple assertion completions to writing test cases that cover specific code blocks across multiple files, these tasks are based on 12 python repositories, analyzing 845 problems with context lengths ranging from 4k to 128k tokens. Utilizing code testing frameworks, we propose a method to construct retrieval contexts using coverage information. While models exhibit comparable performance with short contexts, notable differences emerge with 16k contexts. Notably, models like GPT-4o and Claude 3.5 can effectively leverage relevant snippets; however, all models score below 35\% on the complex Task III, even with the oracle context provided, underscoring the benchmark's significance and the potential for model improvement. The benchmark is containerized for code execution across tasks, and we will release the code, data, and construction methodologies.
Unlocking Anticipatory Text Generation: A Constrained Approach for Faithful Decoding with Large Language Models
Dec 11, 2023

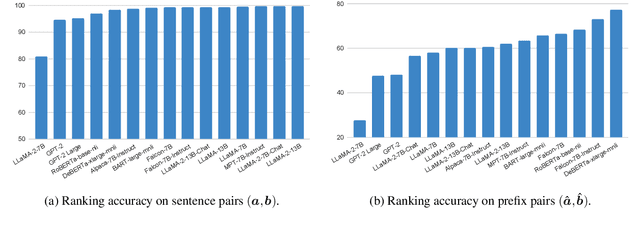

Large Language Models (LLMs) have demonstrated a powerful ability for text generation. However, achieving optimal results with a given prompt or instruction can be challenging, especially for billion-sized models. Additionally, undesired behaviors such as toxicity or hallucinations can manifest. While much larger models (e.g., ChatGPT) may demonstrate strength in mitigating these issues, there is still no guarantee of complete prevention. In this work, we propose formalizing text generation as a future-constrained generation problem to minimize undesirable behaviors and enforce faithfulness to instructions. The estimation of future constraint satisfaction, accomplished using LLMs, guides the text generation process. Our extensive experiments demonstrate the effectiveness of the proposed approach across three distinct text generation tasks: keyword-constrained generation (Lin et al., 2020), toxicity reduction (Gehman et al., 2020), and factual correctness in question-answering (Gao et al., 2023).
Efficiently Aligned Cross-Lingual Transfer Learning for Conversational Tasks using Prompt-Tuning
Apr 03, 2023



Cross-lingual transfer of language models trained on high-resource languages like English has been widely studied for many NLP tasks, but focus on conversational tasks has been rather limited. This is partly due to the high cost of obtaining non-English conversational data, which results in limited coverage. In this work, we introduce XSGD, a parallel and large-scale multilingual conversation dataset that we created by translating the English-only Schema-Guided Dialogue (SGD) dataset (Rastogi et al., 2020) into 105 other languages. XSGD contains approximately 330k utterances per language. To facilitate aligned cross-lingual representations, we develop an efficient prompt-tuning-based method for learning alignment prompts. We also investigate two different classifiers: NLI-based and vanilla classifiers, and test cross-lingual capability enabled by the aligned prompts. We evaluate our model's cross-lingual generalization capabilities on two conversation tasks: slot-filling and intent classification. Our results demonstrate the strong and efficient modeling ability of NLI-based classifiers and the large cross-lingual transfer improvements achieved by our aligned prompts, particularly in few-shot settings.
Converse: A Tree-Based Modular Task-Oriented Dialogue System
Mar 30, 2022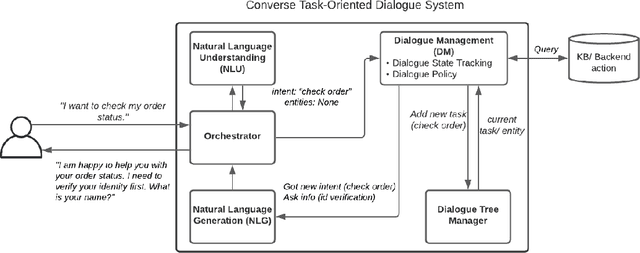

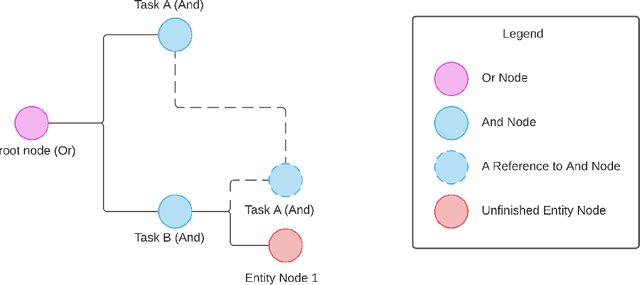
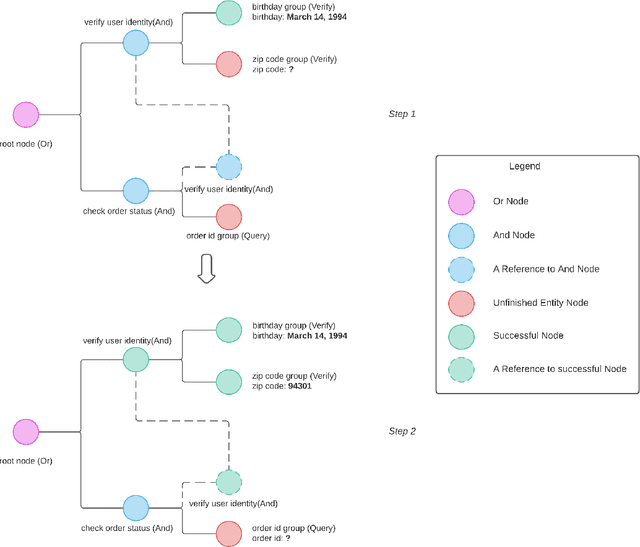
Creating a system that can have meaningful conversations with humans to help accomplish tasks is one of the ultimate goals of Artificial Intelligence (AI). It has defined the meaning of AI since the beginning. A lot has been accomplished in this area recently, with voice assistant products entering our daily lives and chat bot systems becoming commonplace in customer service. At first glance there seems to be no shortage of options for dialogue systems. However, the frequently deployed dialogue systems today seem to all struggle with a critical weakness - they are hard to build and harder to maintain. At the core of the struggle is the need to script every single turn of interactions between the bot and the human user. This makes the dialogue systems more difficult to maintain as the tasks become more complex and more tasks are added to the system. In this paper, we propose Converse, a flexible tree-based modular task-oriented dialogue system. Converse uses an and-or tree structure to represent tasks and offers powerful multi-task dialogue management. Converse supports task dependency and task switching, which are unique features compared to other open-source dialogue frameworks. At the same time, Converse aims to make the bot building process easy and simple, for both professional and non-professional software developers. The code is available at https://github.com/salesforce/Converse.