 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^3$Eval: Multi-Modal Memory Evaluation through Cognitively-Grounded Video Tasks
Jun 03, 2026As multi-modal models advance towards long-form video understanding, memory emerges as a critical capability. Despite substantial efforts in developing video datasets and benchmarks, existing works primarily focus on perception and reasoning, without systematically evaluating memory: what models retain, how faithfully information is preserved, and how robust memory remains under interference. To address this gap, we introduce M$^3$Eval, the first comprehensive evaluation framework and benchmark for probing different memory dimensions in multi-modal models. Grounded in cognitive psychology, our design features carefully constructed tasks that isolate key aspects of memory. Leveraging M$^3$Eval, we conduct extensive experiments across representative multi-modal models, revealing consistent weaknesses and distinctive behaviors. We find that models struggle to maintain disentangled representations when processing parallel video streams, exhibit interference patterns differing substantially from those observed in human memory, ground memory sources more reliably in the spatial domain than the temporal domain, and demonstrate limited symbolic memory. Collectively, our benchmark provides a valuable resource for future research, while our findings highlight memory as a fundamental yet underexplored capability and offer insights for designing more effective memory mechanisms in multi-modal models. Our code and dataset are available at https://pku-value-lab.github.io/m3eval-homepage.
MTA-Agent: An Open Recipe for Multimodal Deep Search Agents
Apr 07, 2026Multimodal large language models (MLLMs) have demonstrated strong capabilities in visual understanding, yet they remain limited in complex, multi-step reasoning that requires deep searching and integrating visual evidence with external knowledge. In this work, we address this challenge by constructing high-quality, verified multi-hop vision-language training data for multimodal deep-search agents. We propose a Multi-hop Tool-Augmented Agent for Evidence-based QA Synthesis (MTA-Agent), which automatically selects tools and their parameters to retrieve and validate evidence from both visual and textual sources and generates structured multi-hop question-answer trajectories. Starting from diverse VQA seed datasets, our pipeline produces a large-scale training dataset, MTA-Vision-DeepSearch, containing 21K high-quality multi-hop examples. The data is filtered through a multi-stage verification process to ensure factual consistency and answer uniqueness. Using MTA-Vision-DeepSearch, a 32B open-source multimodal search agent achieves state-of-the-art performance, reaching an average of 54.63\% across six challenging benchmarks, outperforming GPT-5 (51.86\%), Gemini-2.5-Pro (50.98\%), and Gemini-3-Pro (54.46\%) under the same tool settings. We further show that training on our data improves both reasoning depth and tool-use behavior, increasing the average number of steps from 2.27 to 4.28, and leading to more systematic and persistent search strategies. Additionally, we demonstrate that training can be performed without real-time tool calls by replaying cached interactions, significantly reducing training cost. Importantly, we present MTA-Agent as a fully open recipe for multimodal deep search: we release the entire dataset, training trajectories, and implementation details to enable reproducibility and future research on open multimodal search agents.
Visual Distraction Undermines Moral Reasoning in Vision-Language Models
Mar 17, 2026Moral reasoning is fundamental to safe Artificial Intelligence (AI), yet ensuring its consistency across modalities becomes critical as AI systems evolve from text-based assistants to embodied agents. Current safety techniques demonstrate success in textual contexts, but concerns remain about generalization to visual inputs. Existing moral evaluation benchmarks rely on textonly formats and lack systematic control over variables that influence moral decision-making. Here we show that visual inputs fundamentally alter moral decision-making in state-of-the-art (SOTA) Vision-Language Models (VLMs), bypassing text-based safety mechanisms. We introduce Moral Dilemma Simulation (MDS), a multimodal benchmark grounded in Moral Foundation Theory (MFT) that enables mechanistic analysis through orthogonal manipulation of visual and contextual variables. The evaluation reveals that the vision modality activates intuition-like pathways that override the more deliberate and safer reasoning patterns observed in text-only contexts. These findings expose critical fragilities where language-tuned safety filters fail to constrain visual processing, demonstrating the urgent need for multimodal safety alignment.
LLM Active Alignment: A Nash Equilibrium Perspective
Feb 06, 2026We develop a game-theoretic framework for predicting and steering the behavior of populations of large language models (LLMs) through Nash equilibrium (NE) analysis. To avoid the intractability of equilibrium computation in open-ended text spaces, we model each agent's action as a mixture over human subpopulations. Agents choose actively and strategically which groups to align with, yielding an interpretable and behaviorally substantive policy class. We derive closed-form NE characterizations, adopting standard concave-utility assumptions to enable analytical system-level predictions and give explicit, actionable guidance for shifting alignment targets toward socially desirable outcomes. The method functions as an active alignment layer on top of existing alignment pipelines such as RLHF. In a social-media setting, we show that a population of LLMs, especially reasoning-based models, may exhibit political exclusion, pathologies where some subpopulations are ignored by all LLM agents, which can be avoided by our method, illustrating the promise of applying the method to regulate multi-agent LLM dynamics across domains.
Are Large Reasoning Models Good Translation Evaluators? Analysis and Performance Boost
Oct 23, 2025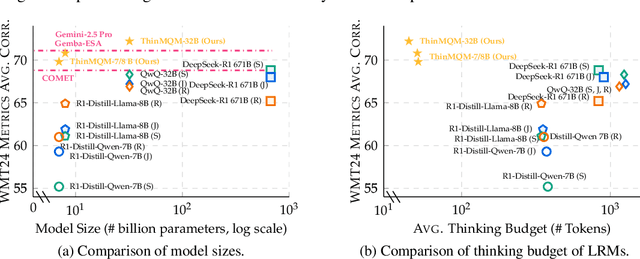
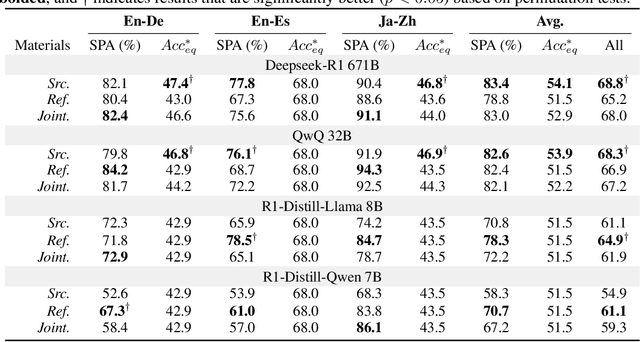
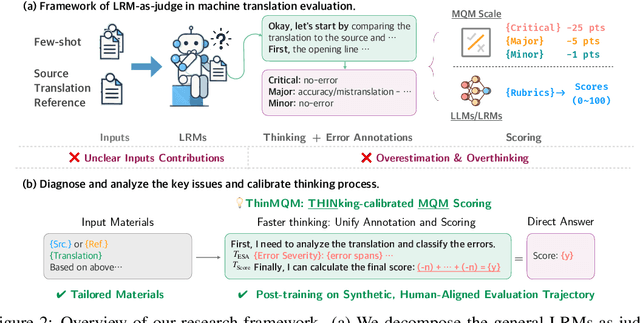

Recent advancements in large reasoning models (LRMs) have introduced an intermediate "thinking" process prior to generating final answers, improving their reasoning capabilities on complex downstream tasks. However, the potential of LRMs as evaluators for machine translation (MT) quality remains underexplored. We provides the first systematic analysis of LRM-as-a-judge in MT evaluation. We identify key challenges, revealing LRMs require tailored evaluation materials, tend to "overthink" simpler instances and have issues with scoring mechanisms leading to overestimation. To address these, we propose to calibrate LRM thinking by training them on synthetic, human-like thinking trajectories. Our experiments on WMT24 Metrics benchmarks demonstrate that this approach largely reduces thinking budgets by ~35x while concurrently improving evaluation performance across different LRM scales from 7B to 32B (e.g., R1-Distill-Qwen-7B achieves a +8.7 correlation point improvement). These findings highlight the potential of efficiently calibrated LRMs to advance fine-grained automatic MT evaluation.
AnalogSeeker: An Open-source Foundation Language Model for Analog Circuit Design
Aug 14, 2025In this paper, we propose AnalogSeeker, an effort toward an open-source foundation language model for analog circuit design, with the aim of integrating domain knowledge and giving design assistance. To overcome the scarcity of data in this field, we employ a corpus collection strategy based on the domain knowledge framework of analog circuits. High-quality, accessible textbooks across relevant subfields are systematically curated and cleaned into a textual domain corpus. To address the complexity of knowledge of analog circuits, we introduce a granular domain knowledge distillation method. Raw, unlabeled domain corpus is decomposed into typical, granular learning nodes, where a multi-agent framework distills implicit knowledge embedded in unstructured text into question-answer data pairs with detailed reasoning processes, yielding a fine-grained, learnable dataset for fine-tuning. To address the unexplored challenges in training analog circuit foundation models, we explore and share our training methods through both theoretical analysis and experimental validation. We finally establish a fine-tuning-centric training paradigm, customizing and implementing a neighborhood self-constrained supervised fine-tuning algorithm. This approach enhances training outcomes by constraining the perturbation magnitude between the model's output distributions before and after training. In practice, we train the Qwen2.5-32B-Instruct model to obtain AnalogSeeker, which achieves 85.04% accuracy on AMSBench-TQA, the analog circuit knowledge evaluation benchmark, with a 15.67% point improvement over the original model and is competitive with mainstream commercial models. Furthermore, AnalogSeeker also shows effectiveness in the downstream operational amplifier design task. AnalogSeeker is open-sourced at https://huggingface.co/analogllm/analogseeker for research use.
Rethinking Prompt-based Debiasing in Large Language Models
Mar 12, 2025
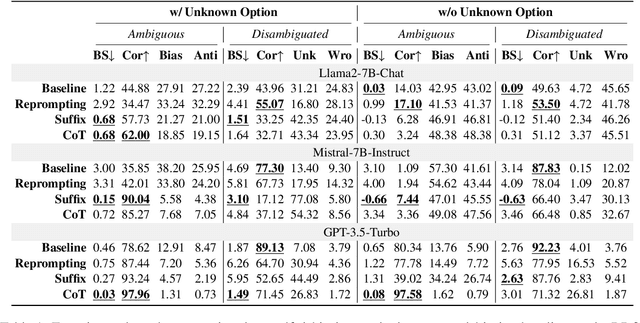
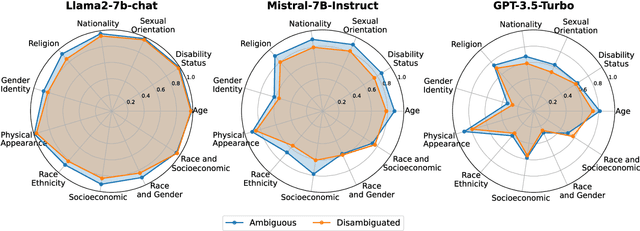
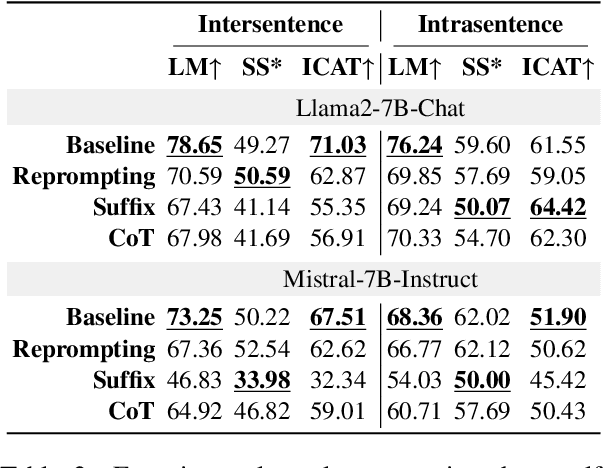
Investigating bias in large language models (LLMs) is crucial for developing trustworthy AI. While prompt-based through prompt engineering is common, its effectiveness relies on the assumption that models inherently understand biases. Our study systematically analyzed this assumption using the BBQ and StereoSet benchmarks on both open-source models as well as commercial GPT model. Experimental results indicate that prompt-based is often superficial; for instance, the Llama2-7B-Chat model misclassified over 90% of unbiased content as biased, despite achieving high accuracy in identifying bias issues on the BBQ dataset. Additionally, specific evaluation and question settings in bias benchmarks often lead LLMs to choose "evasive answers", disregarding the core of the question and the relevance of the response to the context. Moreover, the apparent success of previous methods may stem from flawed evaluation metrics. Our research highlights a potential "false prosperity" in prompt-base efforts and emphasizes the need to rethink bias metrics to ensure truly trustworthy AI.
Multi-Robot System for Cooperative Exploration in Unknown Environments: A Survey
Mar 10, 2025With the advancement of multi-robot technology, cooperative exploration tasks have garnered increasing attention. This paper presents a comprehensive review of multi-robot cooperative exploration systems. First, we review the evolution of robotic exploration and introduce a modular research framework tailored for multi-robot cooperative exploration. Based on this framework, we systematically categorize and summarize key system components. As a foundational module for multi-robot exploration, the localization and mapping module is primarily introduced by focusing on global and relative pose estimation, as well as multi-robot map merging techniques. The cooperative motion module is further divided into learning-based approaches and multi-stage planning, with the latter encompassing target generation, task allocation, and motion planning strategies. Given the communication constraints of real-world environments, we also analyze the communication module, emphasizing how robots exchange information within local communication ranges and under limited transmission capabilities. Finally, we discuss the challenges and future research directions for multi-robot cooperative exploration in light of real-world trends. This review aims to serve as a valuable reference for researchers and practitioners in the field.
Policy-to-Language: Train LLMs to Explain Decisions with Flow-Matching Generated Rewards
Feb 18, 2025As humans increasingly share environments with diverse agents powered by RL, LLMs, and beyond, the ability to explain their policies in natural language will be vital for reliable coexistence. In this paper, we build a model-agnostic explanation generator based on an LLM. The technical novelty is that the rewards for training this LLM are generated by a generative flow matching model. This model has a specially designed structure with a hidden layer merged with an LLM to harness the linguistic cues of explanations into generating appropriate rewards. Experiments on both RL and LLM tasks demonstrate that our method can generate dense and effective rewards while saving on expensive human feedback; it thus enables effective explanations and even improves the accuracy of the decisions in original tasks.
Learning to Plan with Personalized Preferences
Feb 02, 2025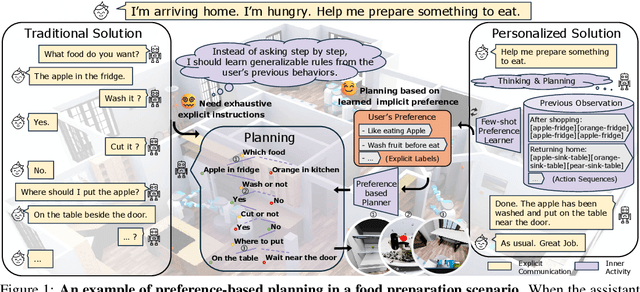
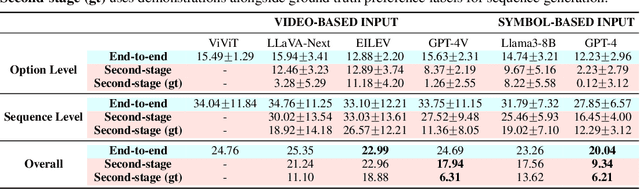
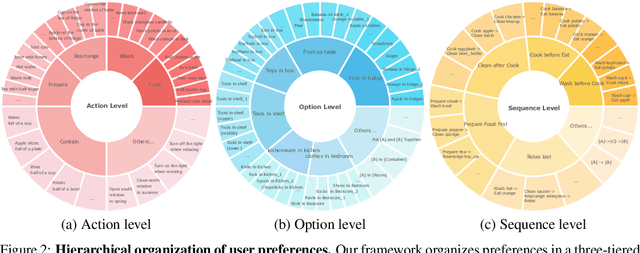
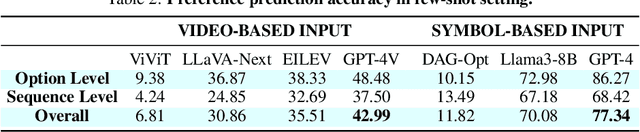
Effective integration of AI agents into daily life requires them to understand and adapt to individual human preferences, particularly in collaborative roles. Although recent studies on embodied intelligence have advanced significantly, they typically adopt generalized approaches that overlook personal preferences in planning. We address this limitation by developing agents that not only learn preferences from few demonstrations but also learn to adapt their planning strategies based on these preferences. Our research leverages the observation that preferences, though implicitly expressed through minimal demonstrations, can generalize across diverse planning scenarios. To systematically evaluate this hypothesis, we introduce Preference-based Planning (PbP) benchmark, an embodied benchmark featuring hundreds of diverse preferences spanning from atomic actions to complex sequences. Our evaluation of SOTA methods reveals that while symbol-based approaches show promise in scalability, significant challenges remain in learning to generate and execute plans that satisfy personalized preferences. We further demonstrate that incorporating learned preferences as intermediate representations in planning significantly improves the agent's ability to construct personalized plans. These findings establish preferences as a valuable abstraction layer for adaptive planning, opening new directions for research in preference-guided plan generation and execution.