 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-Redundancy-Controlled Parallel Decoding for Diffusion-Based Multimodal Large Language Models
May 25, 2026Diffusion-based multimodal large language models (dMLLMs) decode by iteratively predicting tokens at multiple masked positions in parallel. This turns each decoding step into a position-selection problem: the model must choose not only which predictions are reliable in isolation, but also which positions should be committed together as context for later decoding steps. Existing confidence-based decoding ranks masked positions independently and commits the top-K positions, largely ignoring whether the committed tokens provide complementary visual grounding. We identify a step-level limitation of this strategy in multimodal settings: high-confidence tokens selected in the same step can rely on overlapping visual grounding, introducing visual redundancy among the committed tokens and leaving less complementary visual grounding available for later decoding. To quantify this effect, we introduce the Visual Redundancy Index (VRI), which measures visual grounding overlap among tokens committed in parallel. To control this redundancy during decoding, we propose Visual-Redundancy-Controlled Decoding (VRCD), a training-free inference-time decoding method that uses token-to-image attention to prioritize visually complementary positions. Across diverse multimodal benchmarks, VRCD reduces visual redundancy and remaining-position entropy with modest runtime overhead. In longer decoding experiments, it also achieves relative accuracy gains of up to 18.8% on M^3CoT and 6.9% on MMBench over confidence-based decoding. Code will be released at https://github.com/infiniteYuanyl/VRCD.
UST-SSM: Unified Spatio-Temporal State Space Models for Point Cloud Video Modeling
Aug 20, 2025


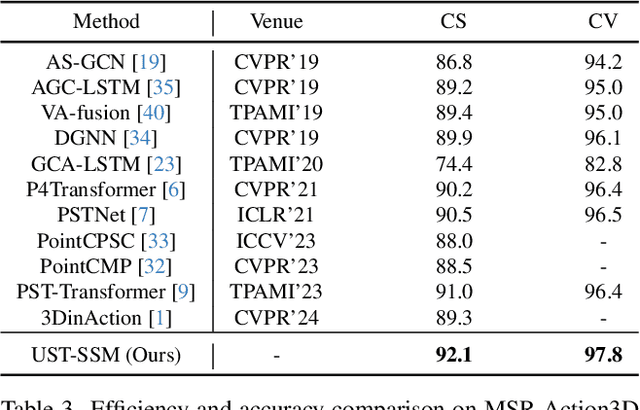
Point cloud videos capture dynamic 3D motion while reducing the effects of lighting and viewpoint variations, making them highly effective for recognizing subtle and continuous human actions. Although Selective State Space Models (SSMs) have shown good performance in sequence modeling with linear complexity, the spatio-temporal disorder of point cloud videos hinders their unidirectional modeling when directly unfolding the point cloud video into a 1D sequence through temporally sequential scanning. To address this challenge, we propose the Unified Spatio-Temporal State Space Model (UST-SSM), which extends the latest advancements in SSMs to point cloud videos. Specifically, we introduce Spatial-Temporal Selection Scanning (STSS), which reorganizes unordered points into semantic-aware sequences through prompt-guided clustering, thereby enabling the effective utilization of points that are spatially and temporally distant yet similar within the sequence. For missing 4D geometric and motion details, Spatio-Temporal Structure Aggregation (STSA) aggregates spatio-temporal features and compensates. To improve temporal interaction within the sampled sequence, Temporal Interaction Sampling (TIS) enhances fine-grained temporal dependencies through non-anchor frame utilization and expanded receptive fields. Experimental results on the MSR-Action3D, NTU RGB+D, and Synthia 4D datasets validate the effectiveness of our method. Our code is available at https://github.com/wangzy01/UST-SSM.
Exploring the Impact of Personality Traits on LLM Bias and Toxicity
Feb 18, 2025
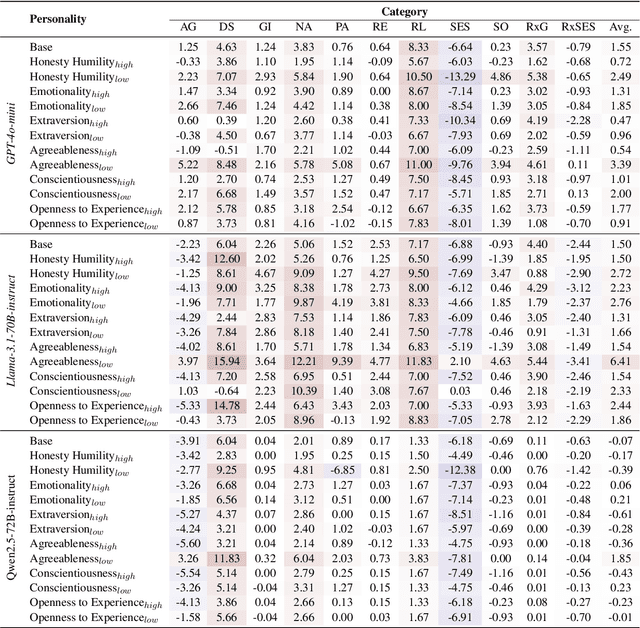
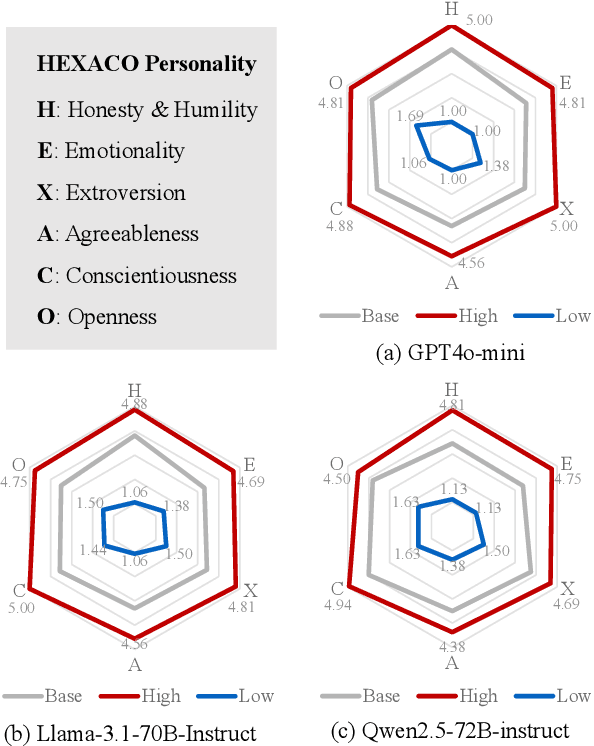
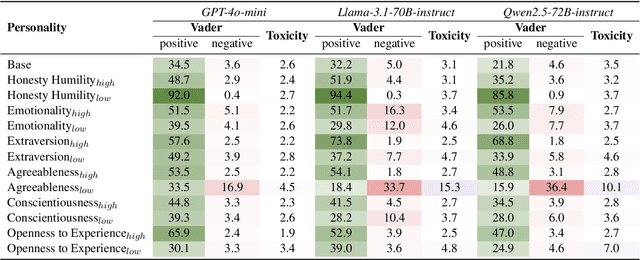
With the different roles that AI is expected to play in human life, imbuing large language models (LLMs) with different personalities has attracted increasing research interests. While the "personification" enhances human experiences of interactivity and adaptability of LLMs, it gives rise to critical concerns about content safety, particularly regarding bias, sentiment and toxicity of LLM generation. This study explores how assigning different personality traits to LLMs affects the toxicity and biases of their outputs. Leveraging the widely accepted HEXACO personality framework developed in social psychology, we design experimentally sound prompts to test three LLMs' performance on three toxic and bias benchmarks. The findings demonstrate the sensitivity of all three models to HEXACO personality traits and, more importantly, a consistent variation in the biases, negative sentiment and toxicity of their output. In particular, adjusting the levels of several personality traits can effectively reduce bias and toxicity in model performance, similar to humans' correlations between personality traits and toxic behaviors. The findings highlight the additional need to examine content safety besides the efficiency of training or fine-tuning methods for LLM personification. They also suggest a potential for the adjustment of personalities to be a simple and low-cost method to conduct controlled text generation.
Findings of the WMT 2024 Shared Task on Discourse-Level Literary Translation
Dec 16, 2024Following last year, we have continued to host the WMT translation shared task this year, the second edition of the Discourse-Level Literary Translation. We focus on three language directions: Chinese-English, Chinese-German, and Chinese-Russian, with the latter two ones newly added. This year, we totally received 10 submissions from 5 academia and industry teams. We employ both automatic and human evaluations to measure the performance of the submitted systems. The official ranking of the systems is based on the overall human judgments. We release data, system outputs, and leaderboard at https://www2.statmt.org/wmt24/literary-translation-task.html.
DetectRL: Benchmarking LLM-Generated Text Detection in Real-World Scenarios
Oct 31, 2024
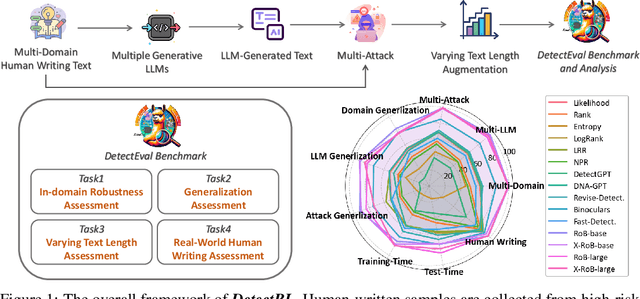
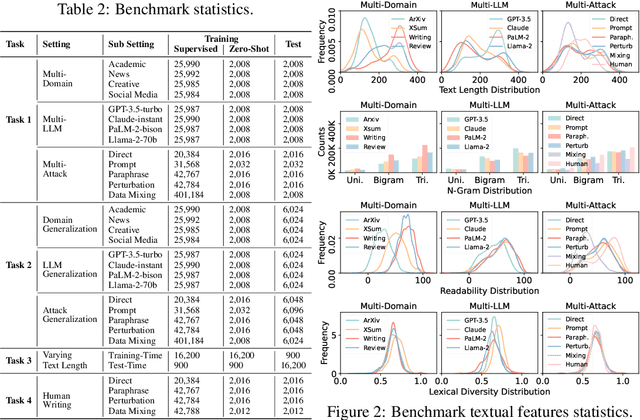
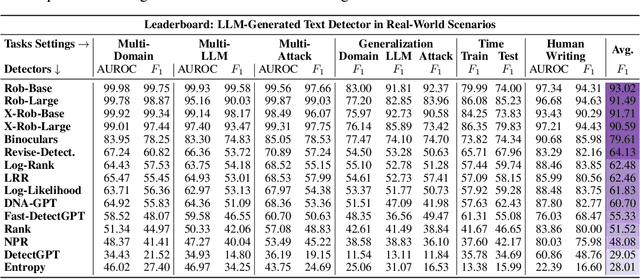
Detecting text generated by large language models (LLMs) is of great recent interest. With zero-shot methods like DetectGPT, detection capabilities have reached impressive levels. However, the reliability of existing detectors in real-world applications remains underexplored. In this study, we present a new benchmark, DetectRL, highlighting that even state-of-the-art (SOTA) detection techniques still underperformed in this task. We collected human-written datasets from domains where LLMs are particularly prone to misuse. Using popular LLMs, we generated data that better aligns with real-world applications. Unlike previous studies, we employed heuristic rules to create adversarial LLM-generated text, simulating advanced prompt usages, human revisions like word substitutions, and writing errors. Our development of DetectRL reveals the strengths and limitations of current SOTA detectors. More importantly, we analyzed the potential impact of writing styles, model types, attack methods, the text lengths, and real-world human writing factors on different types of detectors. We believe DetectRL could serve as an effective benchmark for assessing detectors in real-world scenarios, evolving with advanced attack methods, thus providing more stressful evaluation to drive the development of more efficient detectors. Data and code are publicly available at: https://github.com/NLP2CT/DetectRL.
(Perhaps) Beyond Human Translation: Harnessing Multi-Agent Collaboration for Translating Ultra-Long Literary Texts
May 20, 2024Recent advancements in machine translation (MT) have significantly enhanced translation quality across various domains. However, the translation of literary texts remains a formidable challenge due to their complex language, figurative expressions, and cultural nuances. In this work, we introduce a novel multi-agent framework based on large language models (LLMs) for literary translation, implemented as a company called TransAgents, which mirrors traditional translation publication process by leveraging the collective capabilities of multiple agents, to address the intricate demands of translating literary works. To evaluate the effectiveness of our system, we propose two innovative evaluation strategies: Monolingual Human Preference (MHP) and Bilingual LLM Preference (BLP). MHP assesses translations from the perspective of monolingual readers of the target language, while BLP uses advanced LLMs to compare translations directly with the original texts. Empirical findings indicate that despite lower d-BLEU scores, translations from TransAgents are preferred by both human evaluators and LLMs over human-written references, particularly in genres requiring domain-specific knowledge. We also highlight the strengths and limitations of TransAgents through case studies and suggests directions for future research.
Findings of the WMT 2023 Shared Task on Discourse-Level Literary Translation: A Fresh Orb in the Cosmos of LLMs
Nov 06, 2023Translating literary works has perennially stood as an elusive dream in machine translation (MT), a journey steeped in intricate challenges. To foster progress in this domain, we hold a new shared task at WMT 2023, the first edition of the Discourse-Level Literary Translation. First, we (Tencent AI Lab and China Literature Ltd.) release a copyrighted and document-level Chinese-English web novel corpus. Furthermore, we put forth an industry-endorsed criteria to guide human evaluation process. This year, we totally received 14 submissions from 7 academia and industry teams. We employ both automatic and human evaluations to measure the performance of the submitted systems. The official ranking of the systems is based on the overall human judgments. In addition, our extensive analysis reveals a series of interesting findings on literary and discourse-aware MT. We release data, system outputs, and leaderboard at http://www2.statmt.org/wmt23/literary-translation-task.html.
A Survey on LLM-generated Text Detection: Necessity, Methods, and Future Directions
Oct 24, 2023



The powerful ability to understand, follow, and generate complex language emerging from large language models (LLMs) makes LLM-generated text flood many areas of our daily lives at an incredible speed and is widely accepted by humans. As LLMs continue to expand, there is an imperative need to develop detectors that can detect LLM-generated text. This is crucial to mitigate potential misuse of LLMs and safeguard realms like artistic expression and social networks from harmful influence of LLM-generated content. The LLM-generated text detection aims to discern if a piece of text was produced by an LLM, which is essentially a binary classification task. The detector techniques have witnessed notable advancements recently, propelled by innovations in watermarking techniques, zero-shot methods, fine-turning LMs methods, adversarial learning methods, LLMs as detectors, and human-assisted methods. In this survey, we collate recent research breakthroughs in this area and underscore the pressing need to bolster detector research. We also delve into prevalent datasets, elucidating their limitations and developmental requirements. Furthermore, we analyze various LLM-generated text detection paradigms, shedding light on challenges like out-of-distribution problems, potential attacks, and data ambiguity. Conclusively, we highlight interesting directions for future research in LLM-generated text detection to advance the implementation of responsible artificial intelligence (AI). Our aim with this survey is to provide a clear and comprehensive introduction for newcomers while also offering seasoned researchers a valuable update in the field of LLM-generated text detection. The useful resources are publicly available at: https://github.com/NLP2CT/LLM-generated-Text-Detection.