 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing the Poem: Image-Semantic Detection of AI-Generated Modern Chinese Poetry with MLLMs
May 21, 2026Previous detection studies have shown that LLMs cannot be effectively used as detectors, but these studies have not addressed modern Chinese poetry. Moreover, no relevant research has explored the performance of LLMs in detecting modern Chinese poetry. This paper evaluates and enhances the performance of LLMs as detectors for modern Chinese poetry, and proposes an image-semantic guided poetry detection method. Compared with traditional detection approaches, our method innovatively incorporates images that reflect the content of the poetry. Through example-driven approaches, our method effectively integrates information such as meaning, imagery, and feeling from the image, then forms a complementary judgment with the poem text. Experimental results demonstrate that the LLM detectors based on our method outperform baseline detectors based on plain text, and even surpass the best-performing traditional detector, RoBERTa. The Gemini detector using our method achieves a Macro-F1 score of 85.65%, reaching the state-of-the-art level. The performance improvements of different LLM detectors on multiple LLMs-generated data prove the effectiveness of our method.
Neuron-Aware Data Selection In Instruction Tuning For Large Language Models
Mar 13, 2026Instruction Tuning (IT) has been proven to be an effective approach to unlock the powerful capabilities of large language models (LLMs). Recent studies indicate that excessive IT data can degrade LLMs performance, while carefully selecting a small subset of high-quality IT data can significantly enhance their capabilities. Therefore, identifying the most efficient subset data from the IT dataset to effectively develop either specific or general abilities in LLMs has become a critical challenge. To address this, we propose a novel and efficient framework called NAIT. NAIT evaluates the impact of IT data on LLMs performance by analyzing the similarity of neuron activation patterns between the IT dataset and the target domain capability. Specifically, NAIT captures neuron activation patterns from in-domain datasets of target domain capabilities to construct reusable and transferable neuron activation features. It then evaluates and selects optimal samples based on the similarity between candidate samples and the expected activation features of the target capabilities. Experimental results show that training on the 10\% Alpaca-GPT4 IT data subset selected by NAIT consistently outperforms methods that rely on external advanced models or uncertainty-based features across various tasks. Our findings also reveal the transferability of neuron activation features across different capabilities of LLMs. In particular, IT data with more logical reasoning and programmatic features possesses strong general transferability, enabling models to develop stronger capabilities across multiple tasks, while a stable core subset of data is sufficient to consistently activate fundamental model capabilities and universally improve performance across diverse tasks.
Investigating CoT Monitorability in Large Reasoning Models
Nov 13, 2025



Large Reasoning Models (LRMs) have demonstrated remarkable performance on complex tasks by engaging in extended reasoning before producing final answers. Beyond improving abilities, these detailed reasoning traces also create a new opportunity for AI safety, CoT Monitorability: monitoring potential model misbehavior, such as the use of shortcuts or sycophancy, through their chain-of-thought (CoT) during decision-making. However, two key fundamental challenges arise when attempting to build more effective monitors through CoT analysis. First, as prior research on CoT faithfulness has pointed out, models do not always truthfully represent their internal decision-making in the generated reasoning. Second, monitors themselves may be either overly sensitive or insufficiently sensitive, and can potentially be deceived by models' long, elaborate reasoning traces. In this paper, we present the first systematic investigation of the challenges and potential of CoT monitorability. Motivated by two fundamental challenges we mentioned before, we structure our study around two central perspectives: (i) verbalization: to what extent do LRMs faithfully verbalize the true factors guiding their decisions in the CoT, and (ii) monitor reliability: to what extent can misbehavior be reliably detected by a CoT-based monitor? Specifically, we provide empirical evidence and correlation analyses between verbalization quality, monitor reliability, and LLM performance across mathematical, scientific, and ethical domains. Then we further investigate how different CoT intervention methods, designed to improve reasoning efficiency or performance, will affect monitoring effectiveness. Finally, we propose MoME, a new paradigm in which LLMs monitor other models' misbehavior through their CoT and provide structured judgments along with supporting evidence.
RepreGuard: Detecting LLM-Generated Text by Revealing Hidden Representation Patterns
Aug 18, 2025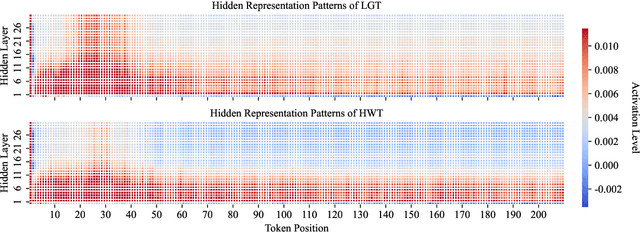

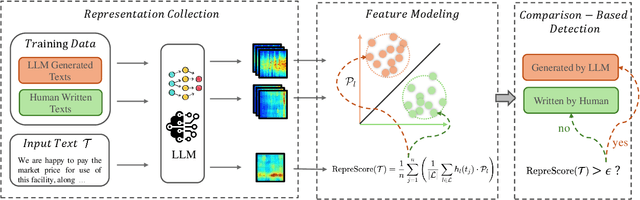

Detecting content generated by large language models (LLMs) is crucial for preventing misuse and building trustworthy AI systems. Although existing detection methods perform well, their robustness in out-of-distribution (OOD) scenarios is still lacking. In this paper, we hypothesize that, compared to features used by existing detection methods, the internal representations of LLMs contain more comprehensive and raw features that can more effectively capture and distinguish the statistical pattern differences between LLM-generated texts (LGT) and human-written texts (HWT). We validated this hypothesis across different LLMs and observed significant differences in neural activation patterns when processing these two types of texts. Based on this, we propose RepreGuard, an efficient statistics-based detection method. Specifically, we first employ a surrogate model to collect representation of LGT and HWT, and extract the distinct activation feature that can better identify LGT. We can classify the text by calculating the projection score of the text representations along this feature direction and comparing with a precomputed threshold. Experimental results show that RepreGuard outperforms all baselines with average 94.92% AUROC on both in-distribution (ID) and OOD scenarios, while also demonstrating robust resilience to various text sizes and mainstream attacks. Data and code are publicly available at: https://github.com/NLP2CT/RepreGuard
Is Long-to-Short a Free Lunch? Investigating Inconsistency and Reasoning Efficiency in LRMs
Jun 24, 2025Large Reasoning Models (LRMs) have achieved remarkable performance on complex tasks by engaging in extended reasoning before producing final answers, yet this strength introduces the risk of overthinking, where excessive token generation occurs even for simple tasks. While recent work in efficient reasoning seeks to reduce reasoning length while preserving accuracy, it remains unclear whether such optimization is truly a free lunch. Drawing on the intuition that compressing reasoning may reduce the robustness of model responses and lead models to omit key reasoning steps, we investigate whether efficient reasoning strategies introduce behavioral inconsistencies. To systematically assess this, we introduce $ICBENCH$, a benchmark designed to measure inconsistency in LRMs across three dimensions: inconsistency across task settings (ITS), inconsistency between training objectives and learned behavior (TR-LB), and inconsistency between internal reasoning and self-explanations (IR-SE). Applying $ICBENCH$ to a range of open-source LRMs, we find that while larger models generally exhibit greater consistency than smaller ones, they all display widespread "scheming" behaviors, including self-disagreement, post-hoc rationalization, and the withholding of reasoning cues. Crucially, our results demonstrate that efficient reasoning strategies such as No-Thinking and Simple Token-Budget consistently increase all three defined types of inconsistency. These findings suggest that although efficient reasoning enhances token-level efficiency, further investigation is imperative to ascertain whether it concurrently introduces the risk of models evading effective supervision.
Rethinking Prompt-based Debiasing in Large Language Models
Mar 12, 2025
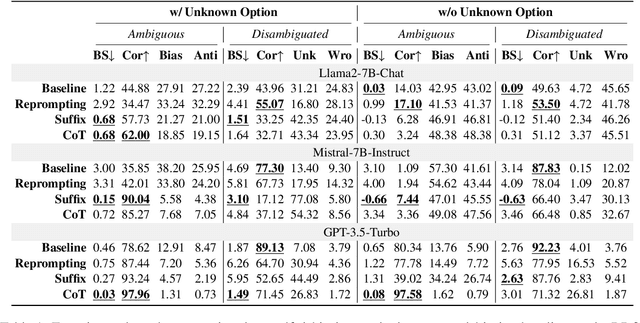
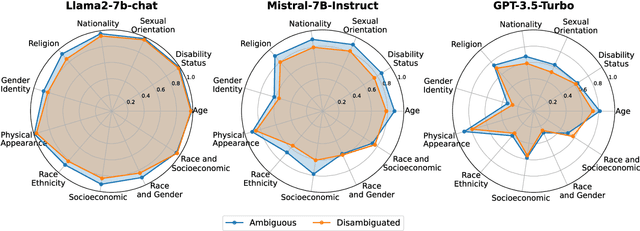
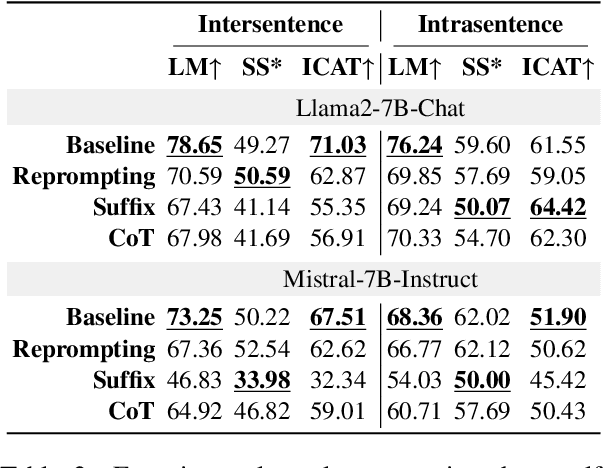
Investigating bias in large language models (LLMs) is crucial for developing trustworthy AI. While prompt-based through prompt engineering is common, its effectiveness relies on the assumption that models inherently understand biases. Our study systematically analyzed this assumption using the BBQ and StereoSet benchmarks on both open-source models as well as commercial GPT model. Experimental results indicate that prompt-based is often superficial; for instance, the Llama2-7B-Chat model misclassified over 90% of unbiased content as biased, despite achieving high accuracy in identifying bias issues on the BBQ dataset. Additionally, specific evaluation and question settings in bias benchmarks often lead LLMs to choose "evasive answers", disregarding the core of the question and the relevance of the response to the context. Moreover, the apparent success of previous methods may stem from flawed evaluation metrics. Our research highlights a potential "false prosperity" in prompt-base efforts and emphasizes the need to rethink bias metrics to ensure truly trustworthy AI.
Can Large Language Models Identify Implicit Suicidal Ideation? An Empirical Evaluation
Feb 25, 2025We present a comprehensive evaluation framework for assessing Large Language Models' (LLMs) capabilities in suicide prevention, focusing on two critical aspects: the Identification of Implicit Suicidal ideation (IIS) and the Provision of Appropriate Supportive responses (PAS). We introduce \ourdata, a novel dataset of 1,308 test cases built upon psychological frameworks including D/S-IAT and Negative Automatic Thinking, alongside real-world scenarios. Through extensive experiments with 8 widely used LLMs under different contextual settings, we find that current models struggle significantly with detecting implicit suicidal ideation and providing appropriate support, highlighting crucial limitations in applying LLMs to mental health contexts. Our findings underscore the need for more sophisticated approaches in developing and evaluating LLMs for sensitive psychological applications.
Fraud-R1 : A Multi-Round Benchmark for Assessing the Robustness of LLM Against Augmented Fraud and Phishing Inducements
Feb 18, 2025We introduce Fraud-R1, a benchmark designed to evaluate LLMs' ability to defend against internet fraud and phishing in dynamic, real-world scenarios. Fraud-R1 comprises 8,564 fraud cases sourced from phishing scams, fake job postings, social media, and news, categorized into 5 major fraud types. Unlike previous benchmarks, Fraud-R1 introduces a multi-round evaluation pipeline to assess LLMs' resistance to fraud at different stages, including credibility building, urgency creation, and emotional manipulation. Furthermore, we evaluate 15 LLMs under two settings: 1. Helpful-Assistant, where the LLM provides general decision-making assistance, and 2. Role-play, where the model assumes a specific persona, widely used in real-world agent-based interactions. Our evaluation reveals the significant challenges in defending against fraud and phishing inducement, especially in role-play settings and fake job postings. Additionally, we observe a substantial performance gap between Chinese and English, underscoring the need for improved multilingual fraud detection capabilities.
DetectRL: Benchmarking LLM-Generated Text Detection in Real-World Scenarios
Oct 31, 2024
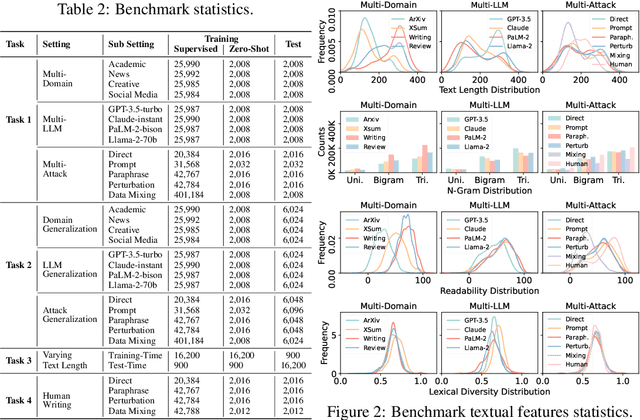
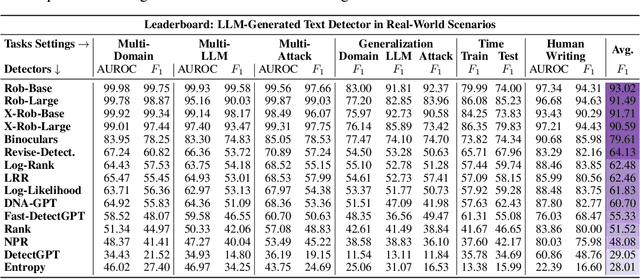
Detecting text generated by large language models (LLMs) is of great recent interest. With zero-shot methods like DetectGPT, detection capabilities have reached impressive levels. However, the reliability of existing detectors in real-world applications remains underexplored. In this study, we present a new benchmark, DetectRL, highlighting that even state-of-the-art (SOTA) detection techniques still underperformed in this task. We collected human-written datasets from domains where LLMs are particularly prone to misuse. Using popular LLMs, we generated data that better aligns with real-world applications. Unlike previous studies, we employed heuristic rules to create adversarial LLM-generated text, simulating advanced prompt usages, human revisions like word substitutions, and writing errors. Our development of DetectRL reveals the strengths and limitations of current SOTA detectors. More importantly, we analyzed the potential impact of writing styles, model types, attack methods, the text lengths, and real-world human writing factors on different types of detectors. We believe DetectRL could serve as an effective benchmark for assessing detectors in real-world scenarios, evolving with advanced attack methods, thus providing more stressful evaluation to drive the development of more efficient detectors. Data and code are publicly available at: https://github.com/NLP2CT/DetectRL.
Who Wrote This? The Key to Zero-Shot LLM-Generated Text Detection Is GECScore
May 07, 2024



The efficacy of an large language model (LLM) generated text detector depends substantially on the availability of sizable training data. White-box zero-shot detectors, which require no such data, are nonetheless limited by the accessibility of the source model of the LLM-generated text. In this paper, we propose an simple but effective black-box zero-shot detection approach, predicated on the observation that human-written texts typically contain more grammatical errors than LLM-generated texts. This approach entails computing the Grammar Error Correction Score (GECScore) for the given text to distinguish between human-written and LLM-generated text. Extensive experimental results show that our method outperforms current state-of-the-art (SOTA) zero-shot and supervised methods, achieving an average AUROC of 98.7% and showing strong robustness against paraphrase and adversarial perturbation attacks.