 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Frontier Planning for Adaptive Peer-Referral Recruitment under Covariate-Dependent Arrivals
Jun 06, 2026Peer-referral recruitment systems such as respondent-driven sampling are critical for studying and intervening on hidden populations affected by infectious diseases. To accelerate recruitment, public health agencies must adaptively allocate limited referral resources across multiple rounds, where current decisions shape both the number and the covariates of future recruits. Prior work makes this problem tractable by assuming that referrals are drawn i.i.d.\ from a homogeneous population, an assumption that ignores the homophily and shared context that drive real peer recruitment. We instead consider a more realistic model in which both referral capacity and the covariates of newly referred individuals are conditioned on the referrer, learned from data with a censored count model and a conditional generative model. The resulting planning problem is challenging because each candidate allocation induces a different distribution over future recruits. We propose \emph{Generative Frontier Planning} (GFP), a model-based planner that replaces per-step Monte-Carlo sampling with a deterministic backup over a latent covariate-coverage value surrogate. The surrogate is designed so that the expected value of the next frontier depends on the offspring generative model only through finite-dimensional summaries that are amortized offline, and so that the resulting per-round objective is monotone with diminishing returns. Together, these two properties make planning tractable: the deterministic backup eliminates Monte-Carlo sampling, and the diminishing-returns structure lets a marginal greedy allocation achieve a \((1-1/e)\)-approximation for the per-round problem. On a simulation environment calibrated to a real respondent-driven sampling dataset, GFP outperforms random, reinforcement-learning, and i.i.d.\ dynamic-programming baselines across four discount factors.
One LR Doesn't Fit All: Heavy-Tail Guided Layerwise Learning Rates for LLMs
May 21, 2026Learning rate configuration is a fundamental aspect of modern deep learning. The prevailing practice of applying a uniform learning rate across all layers overlooks the structural heterogeneity of Transformers, potentially limiting their effectiveness as the backbone of Large Language Models (LLMs). In this paper, we introduce Layerwise Learning Rate (LLR), an adaptive scheme that assigns distinct learning rates to individual Transformer layers. Our method is grounded in Heavy-Tailed Self-Regularization (HT-SR) theory, which characterizes the empirical spectral density (ESD) of weight correlation matrices to quantify heavy-tailedness. Layers with weaker heavy-tailedness are assigned larger learning rates to accelerate their training, while layers with stronger heavy-tailedness receive smaller learning rates. By tailoring learning rates in this manner, LLR promotes balanced training across layers, leading to faster convergence and improved generalization. Extensive experiments across architectures (from LLaMA to GPT-nano), optimizers (AdamW and Muon), and parameter scales (60M-1B) demonstrate that LLR achieves up to 1.5x training speedup and outperforms baselines, notably raising average zero-shot accuracy from 47.09% to 49.02%. A key advantage of LLR is its low tuning overhead: it transfers nearly optimal LR settings directly from the uniform baseline. Code is available at https://github.com/hed-ucas/Layer-wise-Learning-Rate.
TaCo: A Benchmark for Lossless and Lossy Codecs of Heterogeneous Tactile Data
Feb 10, 2026Tactile sensing is crucial for embodied intelligence, providing fine-grained perception and control in complex environments. However, efficient tactile data compression, which is essential for real-time robotic applications under strict bandwidth constraints, remains underexplored. The inherent heterogeneity and spatiotemporal complexity of tactile data further complicate this challenge. To bridge this gap, we introduce TaCo, the first comprehensive benchmark for Tactile data Codecs. TaCo evaluates 30 compression methods, including off-the-shelf compression algorithms and neural codecs, across five diverse datasets from various sensor types. We systematically assess both lossless and lossy compression schemes on four key tasks: lossless storage, human visualization, material and object classification, and dexterous robotic grasping. Notably, we pioneer the development of data-driven codecs explicitly trained on tactile data, TaCo-LL (lossless) and TaCo-L (lossy). Results have validated the superior performance of our TaCo-LL and TaCo-L. This benchmark provides a foundational framework for understanding the critical trade-offs between compression efficiency and task performance, paving the way for future advances in tactile perception.
CORE: Code-based Inverse Self-Training Framework with Graph Expansion for Virtual Agents
Jan 05, 2026The development of Multimodal Virtual Agents has made significant progress through the integration of Multimodal Large Language Models. However, mainstream training paradigms face key challenges: Behavior Cloning is simple and effective through imitation but suffers from low behavioral diversity, while Reinforcement Learning is capable of discovering novel strategies through exploration but heavily relies on manually designed reward functions. To address the conflict between these two methods, we present CORE, a Code-based Inverse Self-Training Framework with Graph Expansion that bridges imitation and exploration, offering a novel training framework that promotes behavioral diversity while eliminating the reliance on manually reward design. Specifically, we introduce Semantic Code Abstraction to automatically infers reward functions from expert demonstrations without manual design. The inferred reward function, referred to as the Label Function, is executable code that verifies one key step within a task. Building on this, we propose Strategy Graph Expansion to enhance in-domain behavioral diversity, which constructs a multi-path graph called Strategy Graph that captures diverse valid solutions beyond expert demonstrations. Furthermore, we introduce Trajectory-Guided Extrapolation, which enriches out-of-domain behavioral diversity by utilizing both successful and failed trajectories to expand the task space. Experiments on Web and Android platforms demonstrate that CORE significantly improves both overall performance and generalization, highlighting its potential as a robust and generalizable training paradigm for building powerful virtual agents.
Demystifying the Roles of LLM Layers in Retrieval, Knowledge, and Reasoning
Oct 02, 2025Recent studies suggest that the deeper layers of Large Language Models (LLMs) contribute little to representation learning and can often be removed without significant performance loss. However, such claims are typically drawn from narrow evaluations and may overlook important aspects of model behavior. In this work, we present a systematic study of depth utilization across diverse dimensions, including evaluation protocols, task categories, and model architectures. Our analysis confirms that very deep layers are generally less effective than earlier ones, but their contributions vary substantially with the evaluation setting. Under likelihood-based metrics without generation, pruning most layers preserves performance, with only the initial few being critical. By contrast, generation-based evaluation uncovers indispensable roles for middle and deeper layers in enabling reasoning and maintaining long-range coherence. We further find that knowledge and retrieval are concentrated in shallow components, whereas reasoning accuracy relies heavily on deeper layers -- yet can be reshaped through distillation. These results highlight that depth usage in LLMs is highly heterogeneous and context-dependent, underscoring the need for task-, metric-, and model-aware perspectives in both interpreting and compressing large models.
OmniVTLA: Vision-Tactile-Language-Action Model with Semantic-Aligned Tactile Sensing
Aug 12, 2025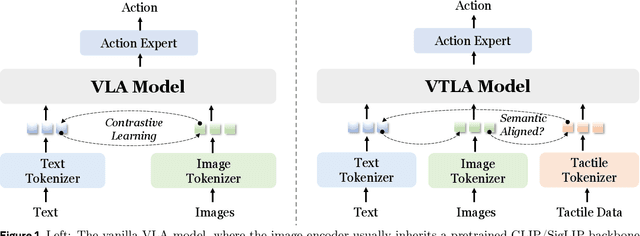

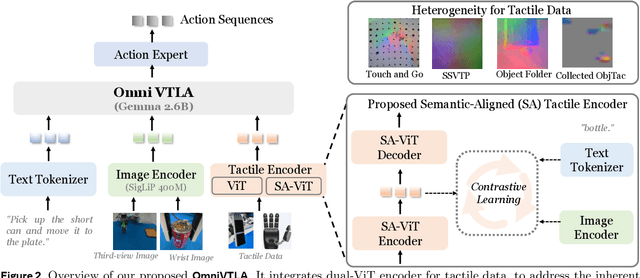

Recent vision-language-action (VLA) models build upon vision-language foundations, and have achieved promising results and exhibit the possibility of task generalization in robot manipulation. However, due to the heterogeneity of tactile sensors and the difficulty of acquiring tactile data, current VLA models significantly overlook the importance of tactile perception and fail in contact-rich tasks. To address this issue, this paper proposes OmniVTLA, a novel architecture involving tactile sensing. Specifically, our contributions are threefold. First, our OmniVTLA features a dual-path tactile encoder framework. This framework enhances tactile perception across diverse vision-based and force-based tactile sensors by using a pretrained vision transformer (ViT) and a semantically-aligned tactile ViT (SA-ViT). Second, we introduce ObjTac, a comprehensive force-based tactile dataset capturing textual, visual, and tactile information for 56 objects across 10 categories. With 135K tri-modal samples, ObjTac supplements existing visuo-tactile datasets. Third, leveraging this dataset, we train a semantically-aligned tactile encoder to learn a unified tactile representation, serving as a better initialization for OmniVTLA. Real-world experiments demonstrate substantial improvements over state-of-the-art VLA baselines, achieving 96.9% success rates with grippers, (21.9% higher over baseline) and 100% success rates with dexterous hands (6.2% higher over baseline) in pick-and-place tasks. Besides, OmniVTLA significantly reduces task completion time and generates smoother trajectories through tactile sensing compared to existing VLA.
Fraud-R1 : A Multi-Round Benchmark for Assessing the Robustness of LLM Against Augmented Fraud and Phishing Inducements
Feb 18, 2025We introduce Fraud-R1, a benchmark designed to evaluate LLMs' ability to defend against internet fraud and phishing in dynamic, real-world scenarios. Fraud-R1 comprises 8,564 fraud cases sourced from phishing scams, fake job postings, social media, and news, categorized into 5 major fraud types. Unlike previous benchmarks, Fraud-R1 introduces a multi-round evaluation pipeline to assess LLMs' resistance to fraud at different stages, including credibility building, urgency creation, and emotional manipulation. Furthermore, we evaluate 15 LLMs under two settings: 1. Helpful-Assistant, where the LLM provides general decision-making assistance, and 2. Role-play, where the model assumes a specific persona, widely used in real-world agent-based interactions. Our evaluation reveals the significant challenges in defending against fraud and phishing inducement, especially in role-play settings and fake job postings. Additionally, we observe a substantial performance gap between Chinese and English, underscoring the need for improved multilingual fraud detection capabilities.
Mitigating Downstream Model Risks via Model Provenance
Oct 03, 2024

Research and industry are rapidly advancing the innovation and adoption of foundation model-based systems, yet the tools for managing these models have not kept pace. Understanding the provenance and lineage of models is critical for researchers, industry, regulators, and public trust. While model cards and system cards were designed to provide transparency, they fall short in key areas: tracing model genealogy, enabling machine readability, offering reliable centralized management systems, and fostering consistent creation incentives. This challenge mirrors issues in software supply chain security, but AI/ML remains at an earlier stage of maturity. Addressing these gaps requires industry-standard tooling that can be adopted by foundation model publishers, open-source model innovators, and major distribution platforms. We propose a machine-readable model specification format to simplify the creation of model records, thereby reducing error-prone human effort, notably when a new model inherits most of its design from a foundation model. Our solution explicitly traces relationships between upstream and downstream models, enhancing transparency and traceability across the model lifecycle. To facilitate the adoption, we introduce the unified model record (UMR) repository , a semantically versioned system that automates the publication of model records to multiple formats (PDF, HTML, LaTeX) and provides a hosted web interface (https://modelrecord.com/). This proof of concept aims to set a new standard for managing foundation models, bridging the gap between innovation and responsible model management.
Can Large Language Models Understand DL-Lite Ontologies? An Empirical Study
Jun 25, 2024Large language models (LLMs) have shown significant achievements in solving a wide range of tasks. Recently, LLMs' capability to store, retrieve and infer with symbolic knowledge has drawn a great deal of attention, showing their potential to understand structured information. However, it is not yet known whether LLMs can understand Description Logic (DL) ontologies. In this work, we empirically analyze the LLMs' capability of understanding DL-Lite ontologies covering 6 representative tasks from syntactic and semantic aspects. With extensive experiments, we demonstrate both the effectiveness and limitations of LLMs in understanding DL-Lite ontologies. We find that LLMs can understand formal syntax and model-theoretic semantics of concepts and roles. However, LLMs struggle with understanding TBox NI transitivity and handling ontologies with large ABoxes. We hope that our experiments and analyses provide more insights into LLMs and inspire to build more faithful knowledge engineering solutions.
A Short Review for Ontology Learning from Text: Stride from Shallow Learning, Deep Learning to Large Language Models Trend
Apr 23, 2024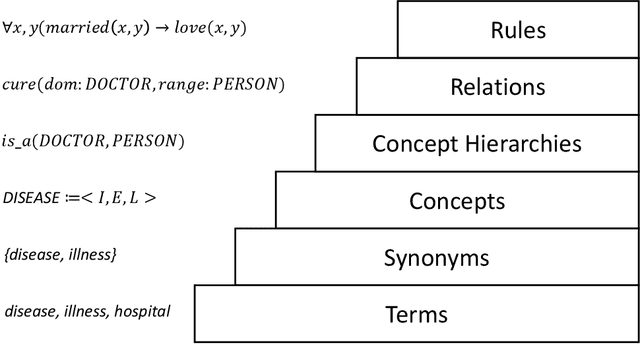
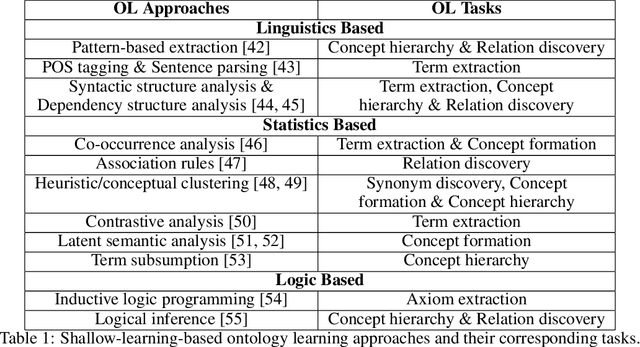
Ontologies provide formal representation of knowledge shared within Semantic Web applications and Ontology learning from text involves the construction of ontologies from a given corpus of text. In the past years, ontology learning has traversed through shallow learning and deep learning methodologies, each offering distinct advantages and limitations in the quest for knowledge extraction and representation. A new trend of these approaches is relying on large language models to enhance ontology learning. This paper gives a review in approaches and challenges of ontology learning. It analyzes the methodologies and limitations of shallow-learning-based and deep-learning-based techniques for ontology learning, and provides comprehensive knowledge for the frontier work of using large language models to enhance ontology learning. In addition, it proposes several noteworthy future directions for further exploration into the integration of large language models with ontology learning tasks.