 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSGQuant: Layer-Sensitivity Guided Quantization for One-Step Diffusion Real-World Video Super-Resolution
Feb 03, 2026One-Step Diffusion Models have demonstrated promising capability and fast inference in video super-resolution (VSR) for real-world. Nevertheless, the substantial model size and high computational cost of Diffusion Transformers (DiTs) limit downstream applications. While low-bit quantization is a common approach for model compression, the effectiveness of quantized models is challenged by the high dynamic range of input latent and diverse layer behaviors. To deal with these challenges, we introduce LSGQuant, a layer-sensitivity guided quantizing approach for one-step diffusion-based real-world VSR. Our method incorporates a Dynamic Range Adaptive Quantizer (DRAQ) to fit video token activations. Furthermore, we estimate layer sensitivity and implement a Variance-Oriented Layer Training Strategy (VOLTS) by analyzing layer-wise statistics in calibration. We also introduce Quantization-Aware Optimization (QAO) to jointly refine the quantized branch and a retained high-precision branch. Extensive experiments demonstrate that our method has nearly performance to origin model with full-precision and significantly exceeds existing quantization techniques. Code is available at: https://github.com/zhengchen1999/LSGQuant.
OneEval: Benchmarking LLM Knowledge-intensive Reasoning over Diverse Knowledge Bases
Jun 14, 2025



Large Language Models (LLMs) have demonstrated substantial progress on reasoning tasks involving unstructured text, yet their capabilities significantly deteriorate when reasoning requires integrating structured external knowledge such as knowledge graphs, code snippets, or formal logic. This limitation is partly due to the absence of benchmarks capable of systematically evaluating LLM performance across diverse structured knowledge modalities. To address this gap, we introduce \textbf{\textsc{OneEval}}, a comprehensive benchmark explicitly designed to assess the knowledge-intensive reasoning capabilities of LLMs across four structured knowledge modalities, unstructured text, knowledge graphs, code, and formal logic, and five critical domains (general knowledge, government, science, law, and programming). \textsc{OneEval} comprises 4,019 carefully curated instances and includes a challenging subset, \textsc{OneEval}\textsubscript{Hard}, consisting of 1,285 particularly difficult cases. Through extensive evaluation of 18 state-of-the-art open-source and proprietary LLMs, we establish three core findings: a) \emph{persistent limitations in structured reasoning}, with even the strongest model achieving only 32.2\% accuracy on \textsc{OneEval}\textsubscript{Hard}; b) \emph{performance consistently declines as the structural complexity of the knowledge base increases}, with accuracy dropping sharply from 53\% (textual reasoning) to 25\% (formal logic); and c) \emph{diminishing returns from extended reasoning chains}, highlighting the critical need for models to adapt reasoning depth appropriately to task complexity. We release the \textsc{OneEval} datasets, evaluation scripts, and baseline results publicly, accompanied by a leaderboard to facilitate ongoing advancements in structured knowledge reasoning.
Electricity Cost Minimization for Multi-Workflow Allocation in Geo-Distributed Data Centers
Apr 27, 2025Worldwide, Geo-distributed Data Centers (GDCs) provide computing and storage services for massive workflow applications, resulting in high electricity costs that vary depending on geographical locations and time. How to reduce electricity costs while satisfying the deadline constraints of workflow applications is important in GDCs, which is determined by the execution time of servers, power, and electricity price. Determining the completion time of workflows with different server frequencies can be challenging, especially in scenarios with heterogeneous computing resources in GDCs. Moreover, the electricity price is also different in geographical locations and may change dynamically. To address these challenges, we develop a geo-distributed system architecture and propose an Electricity Cost aware Multiple Workflows Scheduling algorithm (ECMWS) for servers of GDCs with fixed frequency and power. ECMWS comprises four stages, namely workflow sequencing, deadline partitioning, task sequencing, and resource allocation where two graph embedding models and a policy network are constructed to solve the Markov Decision Process (MDP). After statistically calibrating parameters and algorithm components over a comprehensive set of workflow instances, the proposed algorithms are compared with the state-of-the-art methods over two types of workflow instances. The experimental results demonstrate that our proposed algorithm significantly outperforms other algorithms, achieving an improvement of over 15\% while maintaining an acceptable computational time. The source codes are available at https://gitee.com/public-artifacts/ecmws-experiments.
Enhancing Environmental Robustness in Few-shot Learning via Conditional Representation Learning
Feb 03, 2025
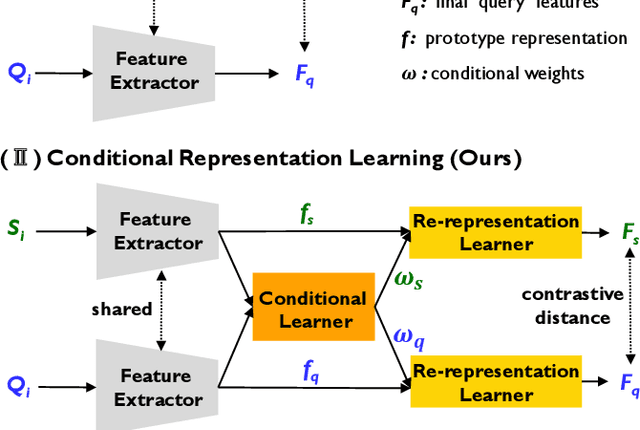

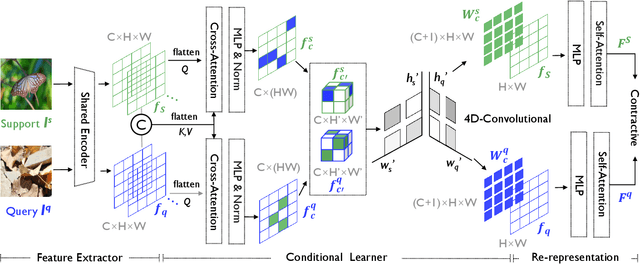
Few-shot learning (FSL) has recently been extensively utilized to overcome the scarcity of training data in domain-specific visual recognition. In real-world scenarios, environmental factors such as complex backgrounds, varying lighting conditions, long-distance shooting, and moving targets often cause test images to exhibit numerous incomplete targets or noise disruptions. However, current research on evaluation datasets and methodologies has largely ignored the concept of "environmental robustness", which refers to maintaining consistent performance in complex and diverse physical environments. This neglect has led to a notable decline in the performance of FSL models during practical testing compared to their training performance. To bridge this gap, we introduce a new real-world multi-domain few-shot learning (RD-FSL) benchmark, which includes four domains and six evaluation datasets. The test images in this benchmark feature various challenging elements, such as camouflaged objects, small targets, and blurriness. Our evaluation experiments reveal that existing methods struggle to utilize training images effectively to generate accurate feature representations for challenging test images. To address this problem, we propose a novel conditional representation learning network (CRLNet) that integrates the interactions between training and testing images as conditional information in their respective representation processes. The main goal is to reduce intra-class variance or enhance inter-class variance at the feature representation level. Finally, comparative experiments reveal that CRLNet surpasses the current state-of-the-art methods, achieving performance improvements ranging from 6.83% to 16.98% across diverse settings and backbones. The source code and dataset are available at https://github.com/guoqianyu-alberta/Conditional-Representation-Learning.
MM-Retinal V2: Transfer an Elite Knowledge Spark into Fundus Vision-Language Pretraining
Jan 27, 2025



Vision-language pretraining (VLP) has been investigated to generalize across diverse downstream tasks for fundus image analysis. Although recent methods showcase promising achievements, they significantly rely on large-scale private image-text data but pay less attention to the pretraining manner, which limits their further advancements. In this work, we introduce MM-Retinal V2, a high-quality image-text paired dataset comprising CFP, FFA, and OCT image modalities. Then, we propose a novel fundus vision-language pretraining model, namely KeepFIT V2, which is pretrained by integrating knowledge from the elite data spark into categorical public datasets. Specifically, a preliminary textual pretraining is adopted to equip the text encoder with primarily ophthalmic textual knowledge. Moreover, a hybrid image-text knowledge injection module is designed for knowledge transfer, which is essentially based on a combination of global semantic concepts from contrastive learning and local appearance details from generative learning. Extensive experiments across zero-shot, few-shot, and linear probing settings highlight the generalization and transferability of KeepFIT V2, delivering performance competitive to state-of-the-art fundus VLP models trained on large-scale private image-text datasets. Our dataset and model are publicly available via https://github.com/lxirich/MM-Retinal.
LLM+KG@VLDB'24 Workshop Summary
Oct 02, 2024
The unification of large language models (LLMs) and knowledge graphs (KGs) has emerged as a hot topic. At the LLM+KG'24 workshop, held in conjunction with VLDB 2024 in Guangzhou, China, one of the key themes explored was important data management challenges and opportunities due to the effective interaction between LLMs and KGs. This report outlines the major directions and approaches presented by various speakers during the LLM+KG'24 workshop.
KGroot: Enhancing Root Cause Analysis through Knowledge Graphs and Graph Convolutional Neural Networks
Feb 11, 2024


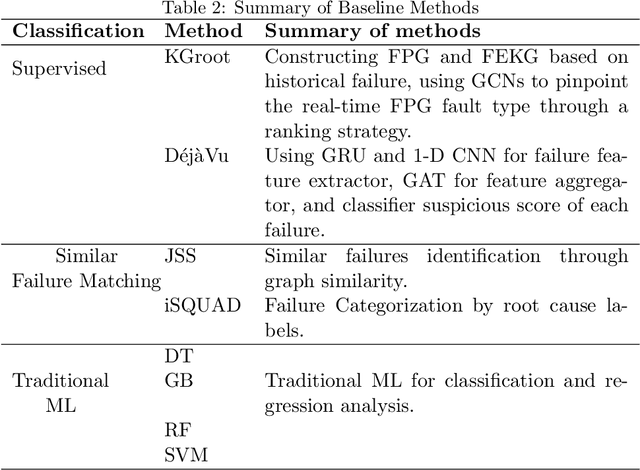
Fault localization is challenging in online micro-service due to the wide variety of monitoring data volume, types, events and complex interdependencies in service and components. Faults events in services are propagative and can trigger a cascade of alerts in a short period of time. In the industry, fault localization is typically conducted manually by experienced personnel. This reliance on experience is unreliable and lacks automation. Different modules present information barriers during manual localization, making it difficult to quickly align during urgent faults. This inefficiency lags stability assurance to minimize fault detection and repair time. Though actionable methods aimed to automatic the process, the accuracy and efficiency are less than satisfactory. The precision of fault localization results is of paramount importance as it underpins engineers trust in the diagnostic conclusions, which are derived from multiple perspectives and offer comprehensive insights. Therefore, a more reliable method is required to automatically identify the associative relationships among fault events and propagation path. To achieve this, KGroot uses event knowledge and the correlation between events to perform root cause reasoning by integrating knowledge graphs and GCNs for RCA. FEKG is built based on historical data, an online graph is constructed in real-time when a failure event occurs, and the similarity between each knowledge graph and online graph is compared using GCNs to pinpoint the fault type through a ranking strategy. Comprehensive experiments demonstrate KGroot can locate the root cause with accuracy of 93.5% top 3 potential causes in second-level. This performance matches the level of real-time fault diagnosis in the industrial environment and significantly surpasses state-of-the-art baselines in RCA in terms of effectiveness and efficiency.
Embedding Ontologies via Incoprorating Extensional and Intensional Knowledge
Jan 20, 2024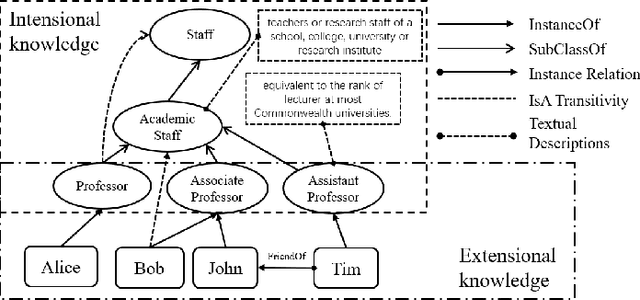
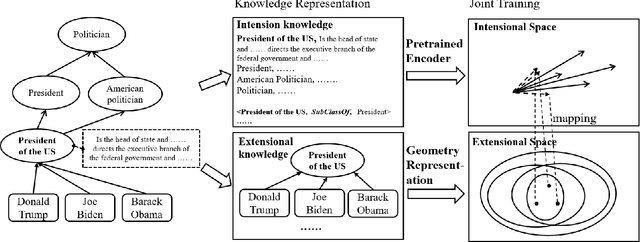
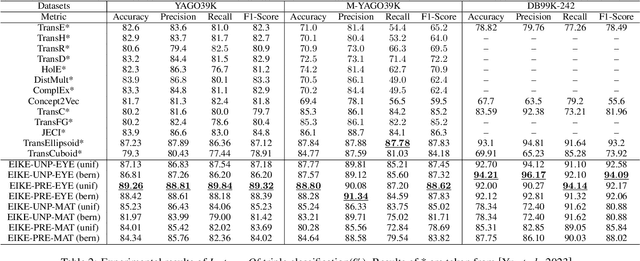
Ontologies contain rich knowledge within domain, which can be divided into two categories, namely extensional knowledge and intensional knowledge. Extensional knowledge provides information about the concrete instances that belong to specific concepts in the ontology, while intensional knowledge details inherent properties, characteristics, and semantic associations among concepts. However, existing ontology embedding approaches fail to take both extensional knowledge and intensional knowledge into fine consideration simultaneously. In this paper, we propose a novel ontology embedding approach named EIKE (Extensional and Intensional Knowledge Embedding) by representing ontologies in two spaces, called extensional space and intensional space. EIKE presents a unified framework for embedding instances, concepts and their relations in an ontology, applying a geometry-based method to model extensional knowledge and a pretrained language model to model intensional knowledge, which can capture both structure information and textual information. Experimental results show that EIKE significantly outperforms state-of-the-art methods in three datasets for both triple classification and link prediction, indicating that EIKE provides a more comprehensive and representative perspective of the domain.
FreeInit: Bridging Initialization Gap in Video Diffusion Models
Dec 12, 2023
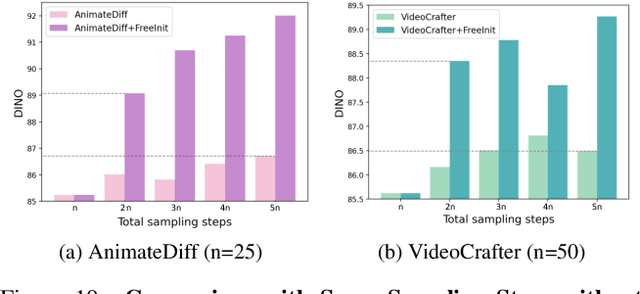


Though diffusion-based video generation has witnessed rapid progress, the inference results of existing models still exhibit unsatisfactory temporal consistency and unnatural dynamics. In this paper, we delve deep into the noise initialization of video diffusion models, and discover an implicit training-inference gap that attributes to the unsatisfactory inference quality. Our key findings are: 1) the spatial-temporal frequency distribution of the initial latent at inference is intrinsically different from that for training, and 2) the denoising process is significantly influenced by the low-frequency components of the initial noise. Motivated by these observations, we propose a concise yet effective inference sampling strategy, FreeInit, which significantly improves temporal consistency of videos generated by diffusion models. Through iteratively refining the spatial-temporal low-frequency components of the initial latent during inference, FreeInit is able to compensate the initialization gap between training and inference, thus effectively improving the subject appearance and temporal consistency of generation results. Extensive experiments demonstrate that FreeInit consistently enhances the generation results of various text-to-video generation models without additional training.
VideoBooth: Diffusion-based Video Generation with Image Prompts
Dec 01, 2023Text-driven video generation witnesses rapid progress. However, merely using text prompts is not enough to depict the desired subject appearance that accurately aligns with users' intents, especially for customized content creation. In this paper, we study the task of video generation with image prompts, which provide more accurate and direct content control beyond the text prompts. Specifically, we propose a feed-forward framework VideoBooth, with two dedicated designs: 1) We propose to embed image prompts in a coarse-to-fine manner. Coarse visual embeddings from image encoder provide high-level encodings of image prompts, while fine visual embeddings from the proposed attention injection module provide multi-scale and detailed encoding of image prompts. These two complementary embeddings can faithfully capture the desired appearance. 2) In the attention injection module at fine level, multi-scale image prompts are fed into different cross-frame attention layers as additional keys and values. This extra spatial information refines the details in the first frame and then it is propagated to the remaining frames, which maintains temporal consistency. Extensive experiments demonstrate that VideoBooth achieves state-of-the-art performance in generating customized high-quality videos with subjects specified in image prompts. Notably, VideoBooth is a generalizable framework where a single model works for a wide range of image prompts with feed-forward pass.