 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Can Learn Scientific Taste
Mar 15, 2026Great scientists have strong judgement and foresight, closely tied to what we call scientific taste. Here, we use the term to refer to the capacity to judge and propose research ideas with high potential impact. However, most relative research focuses on improving an AI scientist's executive capability, while enhancing an AI's scientific taste remains underexplored. In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a preference modeling and alignment problem. For preference modeling, we train Scientific Judge on 700K field- and time-matched pairs of high- vs. low-citation papers to judge ideas. For preference alignment, using Scientific Judge as a reward model, we train a policy model, Scientific Thinker, to propose research ideas with high potential impact. Experiments show Scientific Judge outperforms SOTA LLMs (e.g., GPT-5.2, Gemini 3 Pro) and generalizes to future-year test, unseen fields, and peer-review preference. Furthermore, Scientific Thinker proposes research ideas with higher potential impact than baselines. Our findings show that AI can learn scientific taste, marking a key step toward reaching human-level AI scientists.
Adaptive Attention Distillation for Robust Few-Shot Segmentation under Environmental Perturbations
Jan 07, 2026Few-shot segmentation (FSS) aims to rapidly learn novel class concepts from limited examples to segment specific targets in unseen images, and has been widely applied in areas such as medical diagnosis and industrial inspection. However, existing studies largely overlook the complex environmental factors encountered in real world scenarios-such as illumination, background, and camera viewpoint-which can substantially increase the difficulty of test images. As a result, models trained under laboratory conditions often fall short of practical deployment requirements. To bridge this gap, in this paper, an environment-robust FSS setting is introduced that explicitly incorporates challenging test cases arising from complex environments-such as motion blur, small objects, and camouflaged targets-to enhance model's robustness under realistic, dynamic conditions. An environment robust FSS benchmark (ER-FSS) is established, covering eight datasets across multiple real world scenarios. In addition, an Adaptive Attention Distillation (AAD) method is proposed, which repeatedly contrasts and distills key shared semantics between known (support) and unknown (query) images to derive class-specific attention for novel categories. This strengthens the model's ability to focus on the correct targets in complex environments, thereby improving environmental robustness. Comparative experiments show that AAD improves mIoU by 3.3% - 8.5% across all datasets and settings, demonstrating superior performance and strong generalization. The source code and dataset are available at: https://github.com/guoqianyu-alberta/Adaptive-Attention-Distillation-for-FSS.
Audio-VLA: Adding Contact Audio Perception to Vision-Language-Action Model for Robotic Manipulation
Nov 13, 2025The Vision-Language-Action models (VLA) have achieved significant advances in robotic manipulation recently. However, vision-only VLA models create fundamental limitations, particularly in perceiving interactive and manipulation dynamic processes. This paper proposes Audio-VLA, a multimodal manipulation policy that leverages contact audio to perceive contact events and dynamic process feedback. Audio-VLA overcomes the vision-only constraints of VLA models. Additionally, this paper introduces the Task Completion Rate (TCR) metric to systematically evaluate dynamic operational processes. Audio-VLA employs pre-trained DINOv2 and SigLIP as visual encoders, AudioCLIP as the audio encoder, and Llama2 as the large language model backbone. We apply LoRA fine-tuning to these pre-trained modules to achieve robust cross-modal understanding of both visual and acoustic inputs. A multimodal projection layer aligns features from different modalities into the same feature space. Moreover RLBench and LIBERO simulation environments are enhanced by adding collision-based audio generation to provide realistic sound feedback during object interactions. Since current robotic manipulation evaluations focus on final outcomes rather than providing systematic assessment of dynamic operational processes, the proposed TCR metric measures how well robots perceive dynamic processes during manipulation, creating a more comprehensive evaluation metric. Extensive experiments on LIBERO, RLBench, and two real-world tasks demonstrate Audio-VLA's superior performance over vision-only comparative methods, while the TCR metric effectively quantifies dynamic process perception capabilities.
GaussianMorphing: Mesh-Guided 3D Gaussians for Semantic-Aware Object Morphing
Oct 02, 2025
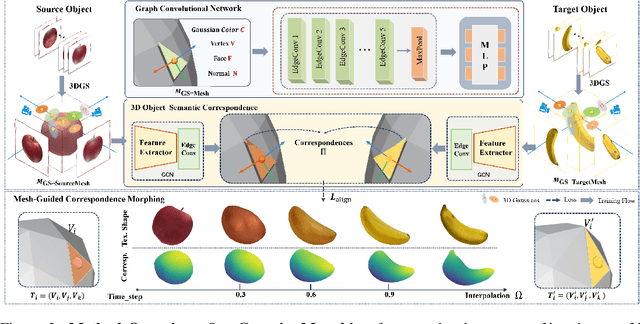
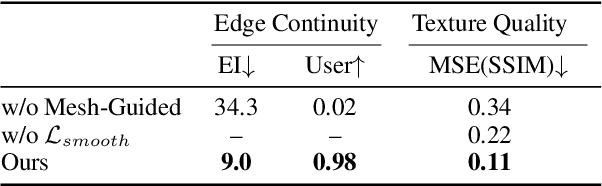
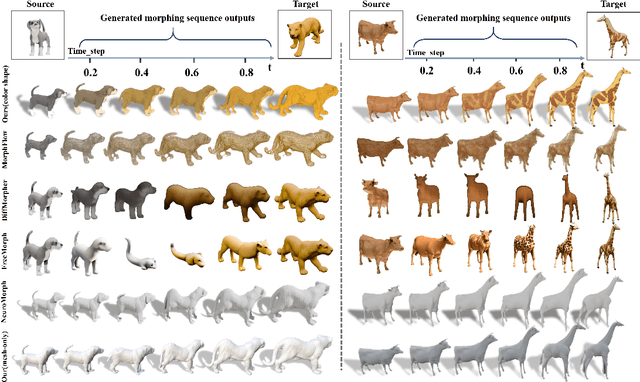
We introduce GaussianMorphing, a novel framework for semantic-aware 3D shape and texture morphing from multi-view images. Previous approaches usually rely on point clouds or require pre-defined homeomorphic mappings for untextured data. Our method overcomes these limitations by leveraging mesh-guided 3D Gaussian Splatting (3DGS) for high-fidelity geometry and appearance modeling. The core of our framework is a unified deformation strategy that anchors 3DGaussians to reconstructed mesh patches, ensuring geometrically consistent transformations while preserving texture fidelity through topology-aware constraints. In parallel, our framework establishes unsupervised semantic correspondence by using the mesh topology as a geometric prior and maintains structural integrity via physically plausible point trajectories. This integrated approach preserves both local detail and global semantic coherence throughout the morphing process with out requiring labeled data. On our proposed TexMorph benchmark, GaussianMorphing substantially outperforms prior 2D/3D methods, reducing color consistency error ($\Delta E$) by 22.2% and EI by 26.2%. Project page: https://baiyunshu.github.io/GAUSSIANMORPHING.github.io/
GTAD: Global Temporal Aggregation Denoising Learning for 3D Semantic Occupancy Prediction
Jul 28, 2025Accurately perceiving dynamic environments is a fundamental task for autonomous driving and robotic systems. Existing methods inadequately utilize temporal information, relying mainly on local temporal interactions between adjacent frames and failing to leverage global sequence information effectively. To address this limitation, we investigate how to effectively aggregate global temporal features from temporal sequences, aiming to achieve occupancy representations that efficiently utilize global temporal information from historical observations. For this purpose, we propose a global temporal aggregation denoising network named GTAD, introducing a global temporal information aggregation framework as a new paradigm for holistic 3D scene understanding. Our method employs an in-model latent denoising network to aggregate local temporal features from the current moment and global temporal features from historical sequences. This approach enables the effective perception of both fine-grained temporal information from adjacent frames and global temporal patterns from historical observations. As a result, it provides a more coherent and comprehensive understanding of the environment. Extensive experiments on the nuScenes and Occ3D-nuScenes benchmark and ablation studies demonstrate the superiority of our method.
Code2Logic: Game-Code-Driven Data Synthesis for Enhancing VLMs General Reasoning
May 20, 2025Visual-language Chain-of-Thought (CoT) data resources are relatively scarce compared to text-only counterparts, limiting the improvement of reasoning capabilities in Vision Language Models (VLMs). However, high-quality vision-language reasoning data is expensive and labor-intensive to annotate. To address this issue, we leverage a promising resource: game code, which naturally contains logical structures and state transition processes. Therefore, we propose Code2Logic, a novel game-code-driven approach for multimodal reasoning data synthesis. Our approach leverages Large Language Models (LLMs) to adapt game code, enabling automatic acquisition of reasoning processes and results through code execution. Using the Code2Logic approach, we developed the GameQA dataset to train and evaluate VLMs. GameQA is cost-effective and scalable to produce, challenging for state-of-the-art models, and diverse with 30 games and 158 tasks. Surprisingly, despite training solely on game data, VLMs demonstrated out of domain generalization, specifically Qwen2.5-VL-7B improving performance by 2.33\% across 7 diverse vision-language benchmarks. Our code and dataset are available at https://github.com/tongjingqi/Code2Logic.
StreamBridge: Turning Your Offline Video Large Language Model into a Proactive Streaming Assistant
May 08, 2025We present StreamBridge, a simple yet effective framework that seamlessly transforms offline Video-LLMs into streaming-capable models. It addresses two fundamental challenges in adapting existing models into online scenarios: (1) limited capability for multi-turn real-time understanding, and (2) lack of proactive response mechanisms. Specifically, StreamBridge incorporates (1) a memory buffer combined with a round-decayed compression strategy, supporting long-context multi-turn interactions, and (2) a decoupled, lightweight activation model that can be effortlessly integrated into existing Video-LLMs, enabling continuous proactive responses. To further support StreamBridge, we construct Stream-IT, a large-scale dataset tailored for streaming video understanding, featuring interleaved video-text sequences and diverse instruction formats. Extensive experiments show that StreamBridge significantly improves the streaming understanding capabilities of offline Video-LLMs across various tasks, outperforming even proprietary models such as GPT-4o and Gemini 1.5 Pro. Simultaneously, it achieves competitive or superior performance on standard video understanding benchmarks.
Enhancing Environmental Robustness in Few-shot Learning via Conditional Representation Learning
Feb 03, 2025
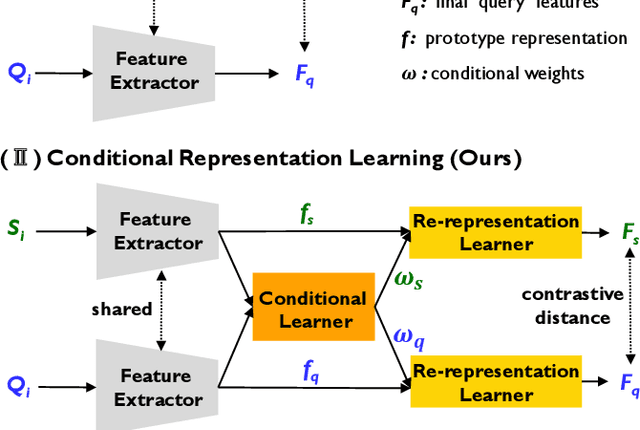

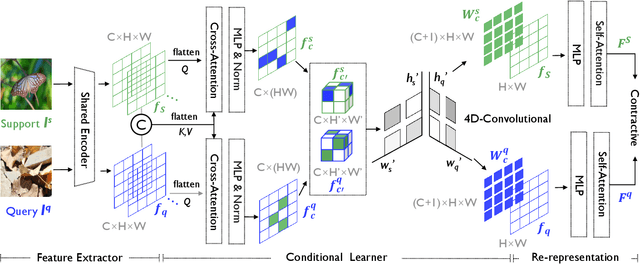
Few-shot learning (FSL) has recently been extensively utilized to overcome the scarcity of training data in domain-specific visual recognition. In real-world scenarios, environmental factors such as complex backgrounds, varying lighting conditions, long-distance shooting, and moving targets often cause test images to exhibit numerous incomplete targets or noise disruptions. However, current research on evaluation datasets and methodologies has largely ignored the concept of "environmental robustness", which refers to maintaining consistent performance in complex and diverse physical environments. This neglect has led to a notable decline in the performance of FSL models during practical testing compared to their training performance. To bridge this gap, we introduce a new real-world multi-domain few-shot learning (RD-FSL) benchmark, which includes four domains and six evaluation datasets. The test images in this benchmark feature various challenging elements, such as camouflaged objects, small targets, and blurriness. Our evaluation experiments reveal that existing methods struggle to utilize training images effectively to generate accurate feature representations for challenging test images. To address this problem, we propose a novel conditional representation learning network (CRLNet) that integrates the interactions between training and testing images as conditional information in their respective representation processes. The main goal is to reduce intra-class variance or enhance inter-class variance at the feature representation level. Finally, comparative experiments reveal that CRLNet surpasses the current state-of-the-art methods, achieving performance improvements ranging from 6.83% to 16.98% across diverse settings and backbones. The source code and dataset are available at https://github.com/guoqianyu-alberta/Conditional-Representation-Learning.
DeTrack: In-model Latent Denoising Learning for Visual Object Tracking
Jan 05, 2025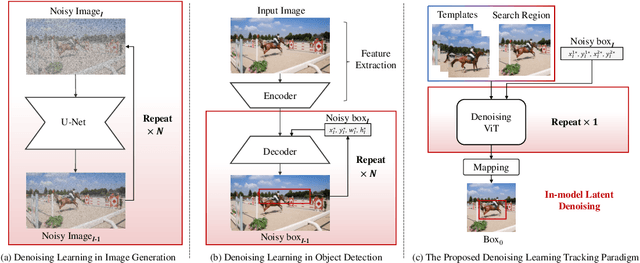

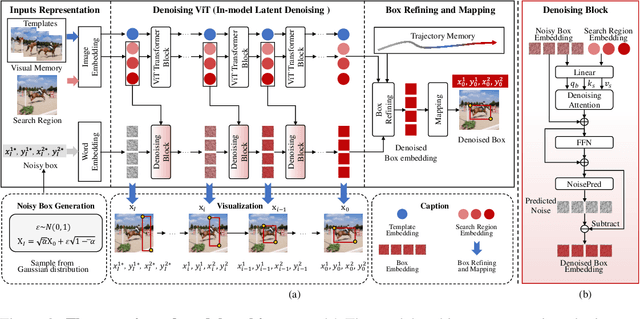
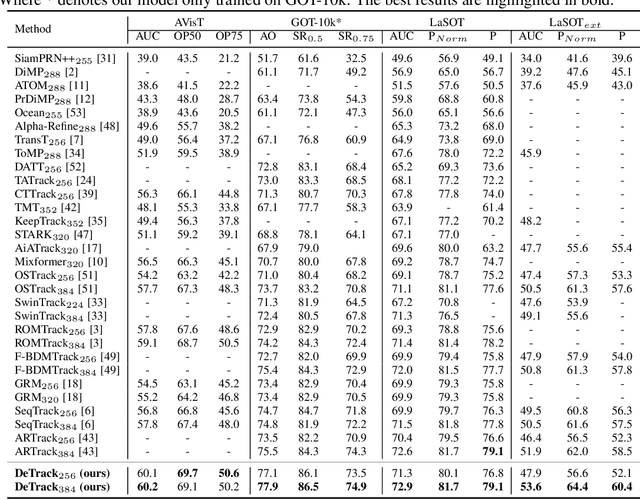
Previous visual object tracking methods employ image-feature regression models or coordinate autoregression models for bounding box prediction. Image-feature regression methods heavily depend on matching results and do not utilize positional prior, while the autoregressive approach can only be trained using bounding boxes available in the training set, potentially resulting in suboptimal performance during testing with unseen data. Inspired by the diffusion model, denoising learning enhances the model's robustness to unseen data. Therefore, We introduce noise to bounding boxes, generating noisy boxes for training, thus enhancing model robustness on testing data. We propose a new paradigm to formulate the visual object tracking problem as a denoising learning process. However, tracking algorithms are usually asked to run in real-time, directly applying the diffusion model to object tracking would severely impair tracking speed. Therefore, we decompose the denoising learning process into every denoising block within a model, not by running the model multiple times, and thus we summarize the proposed paradigm as an in-model latent denoising learning process. Specifically, we propose a denoising Vision Transformer (ViT), which is composed of multiple denoising blocks. In the denoising block, template and search embeddings are projected into every denoising block as conditions. A denoising block is responsible for removing the noise in a predicted bounding box, and multiple stacked denoising blocks cooperate to accomplish the whole denoising process. Subsequently, we utilize image features and trajectory information to refine the denoised bounding box. Besides, we also utilize trajectory memory and visual memory to improve tracking stability. Experimental results validate the effectiveness of our approach, achieving competitive performance on several challenging datasets.
Compound-QA: A Benchmark for Evaluating LLMs on Compound Questions
Nov 15, 2024



Large language models (LLMs) demonstrate remarkable performance across various tasks, prompting researchers to develop diverse evaluation benchmarks. However, existing benchmarks typically measure the ability of LLMs to respond to individual questions, neglecting the complex interactions in real-world applications. In this paper, we introduce Compound Question Synthesis (CQ-Syn) to create the Compound-QA benchmark, focusing on compound questions with multiple sub-questions. This benchmark is derived from existing QA datasets, annotated with proprietary LLMs and verified by humans for accuracy. It encompasses five categories: Factual-Statement, Cause-and-Effect, Hypothetical-Analysis, Comparison-and-Selection, and Evaluation-and-Suggestion. It evaluates the LLM capability in terms of three dimensions including understanding, reasoning, and knowledge. Our assessment of eight open-source LLMs using Compound-QA reveals distinct patterns in their responses to compound questions, which are significantly poorer than those to non-compound questions. Additionally, we investigate various methods to enhance LLMs performance on compound questions. The results indicate that these approaches significantly improve the models' comprehension and reasoning abilities on compound questions.