 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompound-QA: A Benchmark for Evaluating LLMs on Compound Questions
Nov 15, 2024



Large language models (LLMs) demonstrate remarkable performance across various tasks, prompting researchers to develop diverse evaluation benchmarks. However, existing benchmarks typically measure the ability of LLMs to respond to individual questions, neglecting the complex interactions in real-world applications. In this paper, we introduce Compound Question Synthesis (CQ-Syn) to create the Compound-QA benchmark, focusing on compound questions with multiple sub-questions. This benchmark is derived from existing QA datasets, annotated with proprietary LLMs and verified by humans for accuracy. It encompasses five categories: Factual-Statement, Cause-and-Effect, Hypothetical-Analysis, Comparison-and-Selection, and Evaluation-and-Suggestion. It evaluates the LLM capability in terms of three dimensions including understanding, reasoning, and knowledge. Our assessment of eight open-source LLMs using Compound-QA reveals distinct patterns in their responses to compound questions, which are significantly poorer than those to non-compound questions. Additionally, we investigate various methods to enhance LLMs performance on compound questions. The results indicate that these approaches significantly improve the models' comprehension and reasoning abilities on compound questions.
Towards Human-Level 3D Relative Pose Estimation: Generalizable, Training-Free, with Single Reference
Jun 26, 2024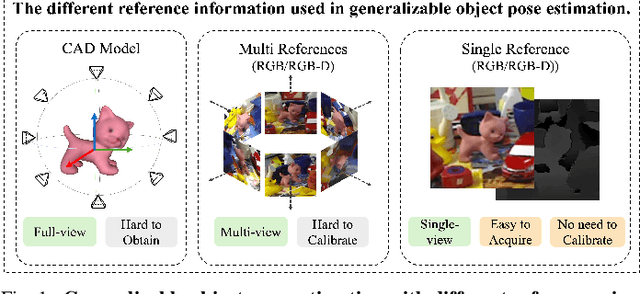
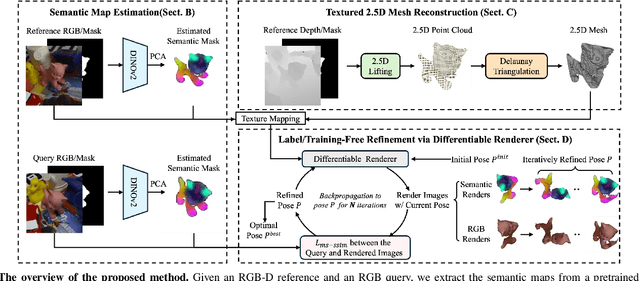

Humans can easily deduce the relative pose of an unseen object, without label/training, given only a single query-reference image pair. This is arguably achieved by incorporating (i) 3D/2.5D shape perception from a single image, (ii) render-and-compare simulation, and (iii) rich semantic cue awareness to furnish (coarse) reference-query correspondence. Existing methods implement (i) by a 3D CAD model or well-calibrated multiple images and (ii) by training a network on specific objects, which necessitate laborious ground-truth labeling and tedious training, potentially leading to challenges in generalization. Moreover, (iii) was less exploited in the paradigm of (ii), despite that the coarse correspondence from (iii) enhances the compare process by filtering out non-overlapped parts under substantial pose differences/occlusions. Motivated by this, we propose a novel 3D generalizable relative pose estimation method by elaborating (i) with a 2.5D shape from an RGB-D reference, (ii) with an off-the-shelf differentiable renderer, and (iii) with semantic cues from a pretrained model like DINOv2. Specifically, our differentiable renderer takes the 2.5D rotatable mesh textured by the RGB and the semantic maps (obtained by DINOv2 from the RGB input), then renders new RGB and semantic maps (with back-surface culling) under a novel rotated view. The refinement loss comes from comparing the rendered RGB and semantic maps with the query ones, back-propagating the gradients through the differentiable renderer to refine the 3D relative pose. As a result, our method can be readily applied to unseen objects, given only a single RGB-D reference, without label/training. Extensive experiments on LineMOD, LM-O, and YCB-V show that our training-free method significantly outperforms the SOTA supervised methods, especially under the rigorous Acc@5/10/15{\deg} metrics and the challenging cross-dataset settings.
StyleBART: Decorate Pretrained Model with Style Adapters for Unsupervised Stylistic Headline Generation
Oct 26, 2023
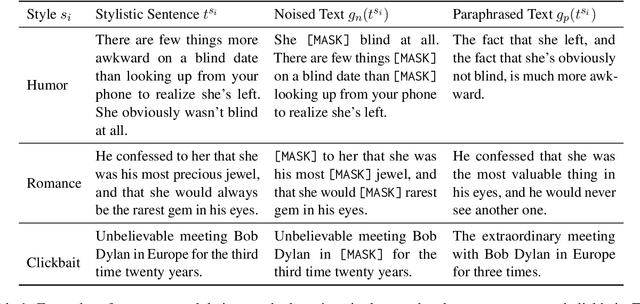

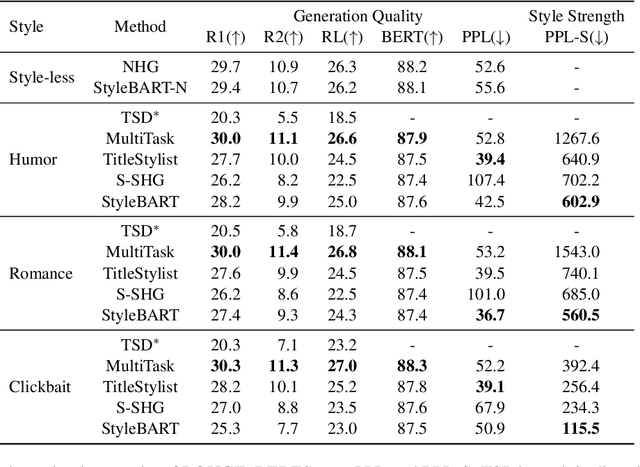
Stylistic headline generation is the task to generate a headline that not only summarizes the content of an article, but also reflects a desired style that attracts users. As style-specific article-headline pairs are scarce, previous researches focus on unsupervised approaches with a standard headline generation dataset and mono-style corpora. In this work, we follow this line and propose StyleBART, an unsupervised approach for stylistic headline generation. Our method decorates the pretrained BART model with adapters that are responsible for different styles and allows the generation of headlines with diverse styles by simply switching the adapters. Different from previous works, StyleBART separates the task of style learning and headline generation, making it possible to freely combine the base model and the style adapters during inference. We further propose an inverse paraphrasing task to enhance the style adapters. Extensive automatic and human evaluations show that StyleBART achieves new state-of-the-art performance in the unsupervised stylistic headline generation task, producing high-quality headlines with the desired style.